이번 글에서는 Transformer 모델의 전반적인 Architecture 및 구성에 데하여 알아보겠습니다.
Transformer: Attention is All You Need
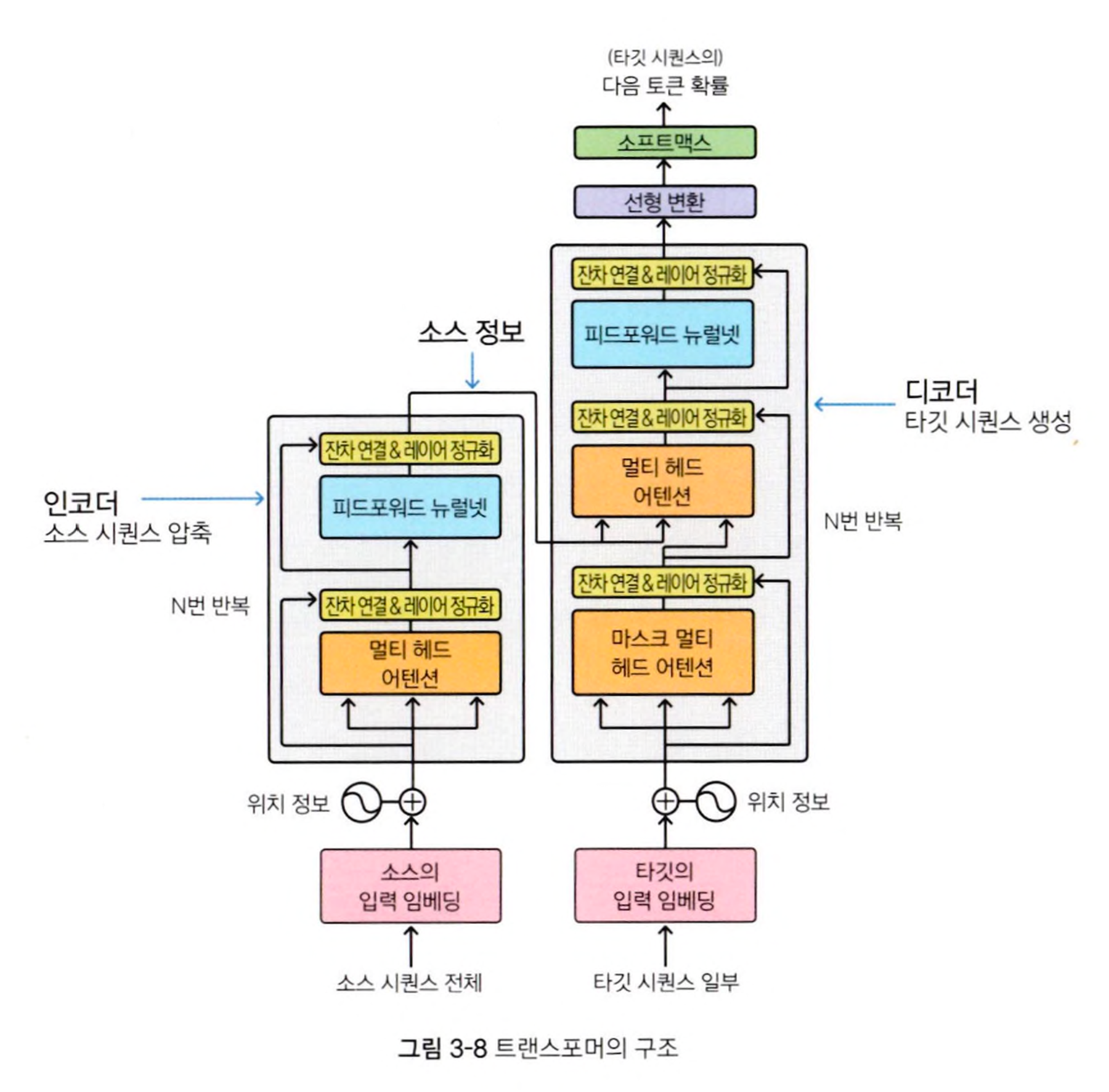
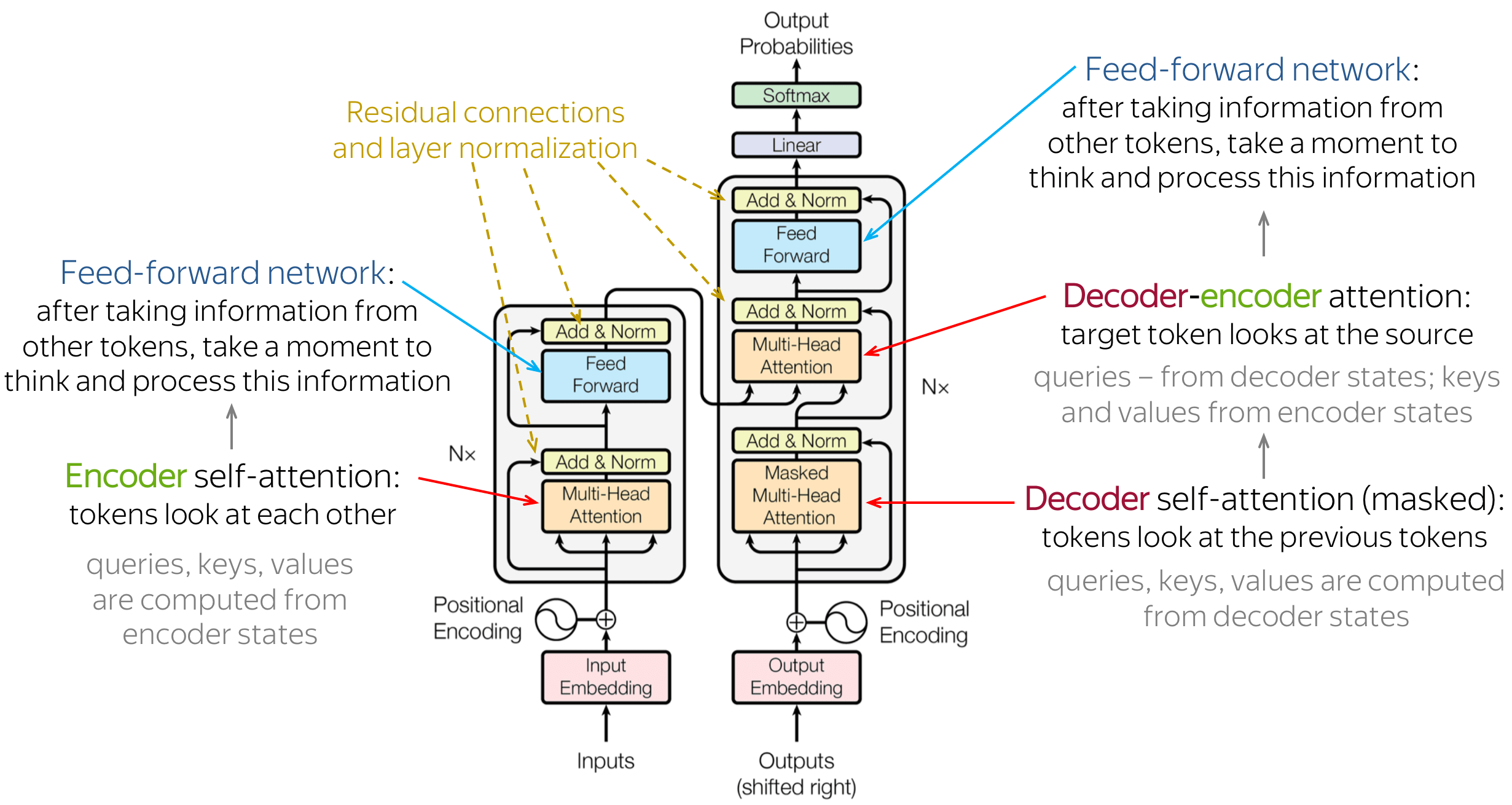
- Transformer 모델은 2017년에 "Attention is All You Need"라는 논문을 통해서 소개되었습니다.
- 주요한 핵심 아이디어는 "Self-Attention" 이라는 매커니즘에 기반하여, 문장 내의 모든 단어들 사이의 관계를 한 번에 파악할 수 있다는 점에 있습니다.
- 이전의 설명했던 RNN(Recurrent Neural Network), LSTM(Long Short-Term Memory)과 같은 순차적인 Model이 가진 순차적 처리의 한계를 극복했다는 특징이 있습니다.
- 그리고 현재 Transformer 모델은 Sequence - Sequence간의 작업 뿐만 아니라, Language Modeling, Pre-Training 설정에서도 사실상의 표준 모델입니다.
- 그리고 Transformer Model은 새로운 모델링 패러다임을 도입했습니다.
Attention 및 Self-Attention 개념에 관한 내용은 아래의 글에 자세히 작성해 두었으니 한번 읽어보세요!
[NLP] Attention - 어텐션
1. Attention Attention은 CS 및 ML에서 중요한 개념중 하나로 여겨집니다. Attention의 매커니즘은 주로 Sequence Data를 처리하거나 생성하는 모델에서 사용됩니다. -> Sequence 입력을 수행하는 머신러닝 학습
daehyun-bigbread.tistory.com
Transformer Model과 RNN Model의 차이점
Transformer 모델과 RNN 모델간의 차이점을 한번 얘기해 보겠습니다.
"나는 은행에 도착 했어... 거리를 건너서? 강을 건너서?"
- 이 문장에서 은행이 의미하는게 뭘까요?
- 문장을 Encoding 할 때 RNN은 전체 문장을 읽을때 까지 은행이 무엇을 의미하는지 이해하지 못하며 긴 Sequence의 경우 시간이 오래 걸릴수도 있습니다.
- 이와 대조적으로 Transformer의 Encoder Token은 서로 동시에 상호작용합니다.
- 직관적으로 Transformer의 Encoder는 일련의 추론하는 단계(Layer-입력 데이터의 변환 & 정보 처리를 담당하는 단위)로 생각할 수 있습니다.
- 각 단계(각 Layer)에서의 Token은 서로를 바라보고(Attention - Self Attention), 정보를 교환하면서 전체 문장의 맥략에서 서로를 더 잘 이해하려고 노력합니다.
- 각 Decoder Layer에서의 Prefix Token은 Self-Attention 매커니즘을 통해서 서로 상호 작용 하면서 Encoder 상태를 확인합니다.
- Attention 및 Self-Attention에 관한 개념은 위의 링크를 달아놓았으니 한번 읽어보세요!
Transformer: Encoder & Decoder

Transformer 모델은 크게 2개의 부분으로 구성되어 있습니다. Encoder와 Decoder로 구성되어 있습니다.
아래에 Encoder & Decoder에 관한 적은글을 참고해주세요!
- 아래의 글은 seq2seq에 데한 Encoder & Decoder에 관하여 쓴 글이지만, 기본적인 개념과 개념은 유사합니다.
- 다만 구체적인 구현과 작동 방식에서의 차이는 있습니다. Transformer Model에서 Encoder & Decoder 부분에 중점을 두고 설명해보겠습니다.
[NLP] Seq2Seq, Encoder & Decoder
1..sequence-to-sequence 💡 트랜스포머(Transformer) 모델은 기계 번역(machine translation) 등 시퀀스-투-시퀀스(sequence-to-sequence) 과제를 수행하기 위한 모델입니다. sequence: 단어 같은 무언가의 나열을 의미합
daehyun-bigbread.tistory.com
Transformer 모델의 Encoder
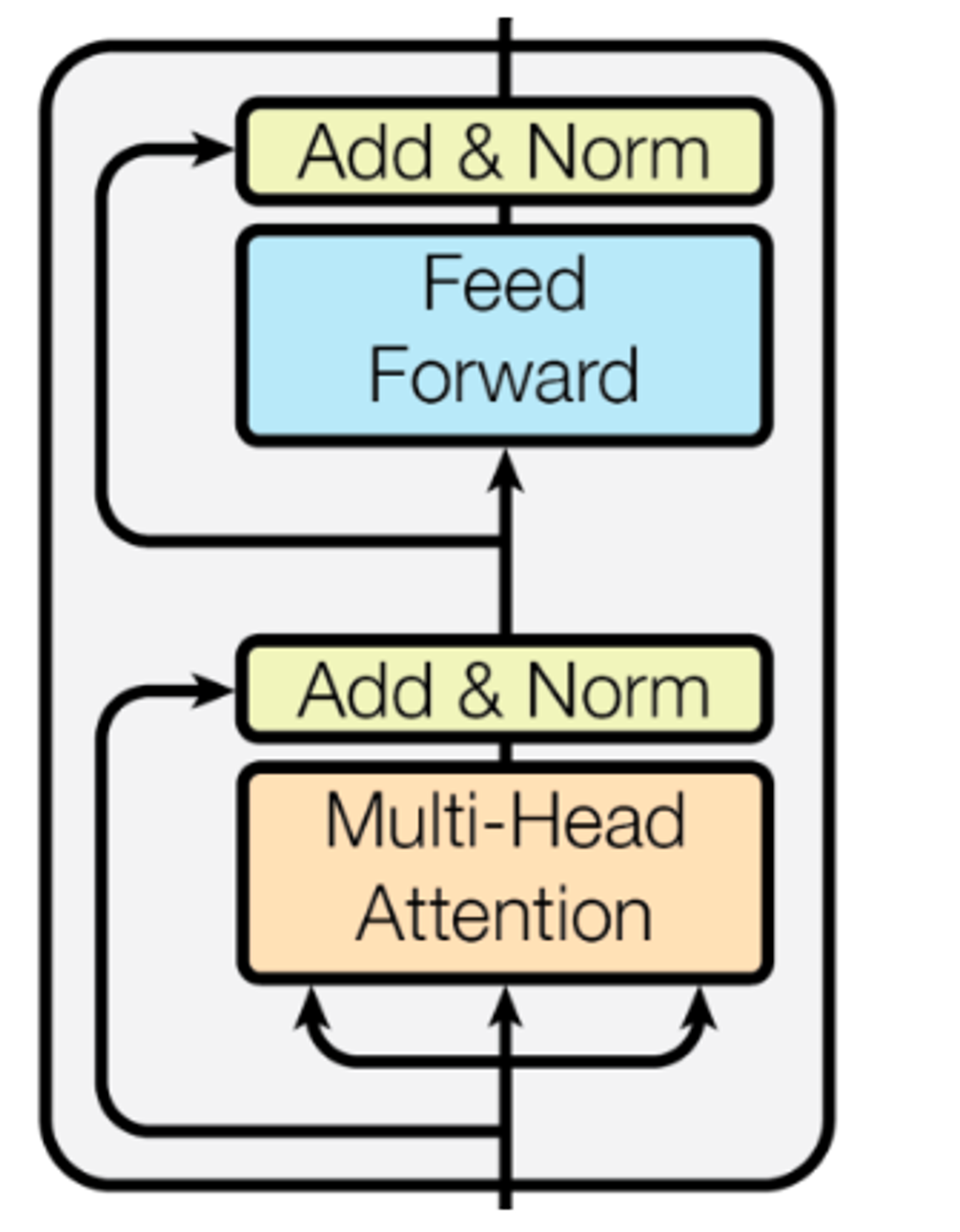
- Encoder: Input Sequence(입력 시퀀스)를 처리하는 구성요소로, 여러개의 Encoder Layer를 순차적으로 쌓아서 구성합니다.
- 각 Layer는 Multi-Head Attention 매커니즘, Position-wise Feed-Forward Network를 포함하며, input 데이터의 전체적인 Context를 효과적으로 포착하여 처리합니다.
- Transformer Model의 Encoder는 순차적 처리가 아닌, 전체 Input Sequence를 한번에 처리하는 점에서 RNN 기반의 Encoder와 차이가 있습니다.
Transformer 모델의 Encoder Example Code
이 코드는 예제 코드입니다. 사용자에 맞춰서 수정을 해야 합니다.
- # seq_len: 전체 데이터를 받아도 그 Sequence length까지만 받겠다.
class Encoder(tf.keras.layers.Layer):
def __init__(self, **kargs):
super(Encoder, self).__init__()
self.d_model = kargs['d_model']
self.num_layers = kargs['num_layers']
self.embedding = tf.keras.layers.Embedding(kargs['input_vocab_size'], self.d_model)
self.pos_encoding = positional_encoding(kargs['maximum_position_encoding'],
self.d_model)
self.enc_layers = [EncoderLayer(**kargs)
for _ in range(self.num_layers)]
self.dropout = tf.keras.layers.Dropout(kargs['rate'])
def call(self, x, mask):
attn = None
seq_len = tf.shape(x)[1]
# adding embedding and position encoding.
x = self.embedding(x) # (batch_size, input_seq_len, d_model)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
x += self.pos_encoding[:, :seq_len, :] # seq_len
x = self.dropout(x)
for i in range(self.num_layers):
x, attn = self.enc_layers[i](x, mask)
return x, attn # (batch_size, input_seq_len, d_model)Transformer 모델의 Decoder
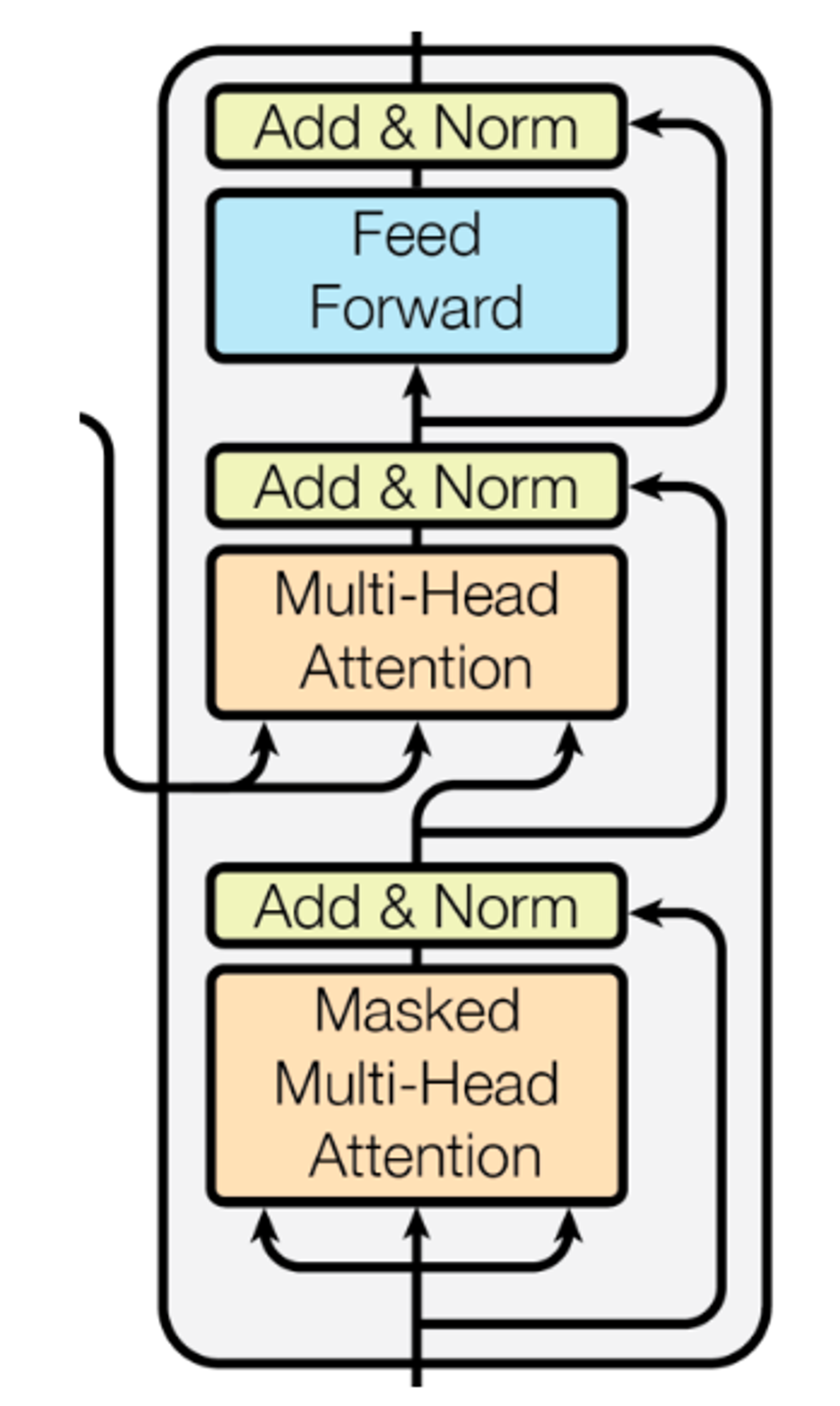
- Decoder: Target Sequence를 처리하는 구성 요소로, 여러개의 Decoder Layer를 순차적으로 쌓아서 구성합니다.
- Decoder Layer는 Encoder와 유사하게 Multi-Head Attention과 Feed-Forward Networks를 사용하지만, 추가적으로 Encoder의 출력 & 상호작용하는 Encoder-Decoder Attention 매커니즘을 포함합니다.
- 이를 통해서 Decoder는 Encoder가 처리한 정보와 자신이 지금까지 생성한 출력을 기반으로 다음 토큰을 예측합니다.
Transformer 모델의 Decoder Example Code
이 코드는 예제 코드입니다. 사용자에 맞춰서 수정을 해야 합니다.
class Decoder(tf.keras.layers.Layer):
def __init__(self, **kargs):
super(Decoder, self).__init__()
self.d_model = kargs['d_model']
self.num_layers = kargs['num_layers']
self.embedding = tf.keras.layers.Embedding(kargs['target_vocab_size'], self.d_model)
self.pos_encoding = positional_encoding(kargs['maximum_position_encoding'], self.d_model)
self.dec_layers = [DecoderLayer(**kargs)
for _ in range(self.num_layers)]
self.dropout = tf.keras.layers.Dropout(kargs['rate'])
def call(self, x, enc_output, look_ahead_mask, padding_mask):
seq_len = tf.shape(x)[1]
attention_weights = {}
x = self.embedding(x) # (batch_size, target_seq_len, d_model)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
x += self.pos_encoding[:, :seq_len, :]
x = self.dropout(x)
for i in range(self.num_layers):
x, block1, block2 = self.dec_layers[i](x, enc_output, look_ahead_mask, padding_mask)
attention_weights['decoder_layer{}_block1'.format(i+1)] = block1
attention_weights['decoder_layer{}_block2'.format(i+1)] = block2
# x.shape == (batch_size, target_seq_len, d_model)
return x, attention_weightsTransformer: Layer
Layer에 데하여 설명을 해보겠습니다.
- Transformer 모델에서의 "Layer"는 Model의 핵심 구성 요소중 하나로, 입력 데이터의 변환 & 정보 처리를 담당하는 단위입니다.
- 모델의 입력을 만드는 계층을 Input Layer, 출력을 Output Layer라고 합니다.
- Transformer Model은 일반적으로 여러 개의 Layer를 순차적으로 쌓아서 구성되며, 각 Layer는 입력 데이터를 받아서 처리하고 그 결과를 다음 Layer로 전달합니다.
- 이러한 구조를 통해서 Model은 Data의 복잡한 특성 & 패턴을 학습할 수 있습니다.
- 크게 Transformer 모델의 Layer는 2가지 주요 구성 요소로 이루어져 있는데, 하나는 Multi-Head Attention, 다른 하나는 Position-wise Feed-Forward Network 입니다.
- 그리고 각 Layer는 정규화(Normalization)과 Residual Connection과 같은 기법을 사용하여 학습의 안정성, 효율성을 높입니다.
- Normalization은 Layer의 Input(입력), Output(출력)을 정규화 하여 학습과정을 안정화 시키는 역할을 합니다.
- Residual Connection은 Input(입력)을 Layer의 Output(출력)에 직접 더하는 방식으로, 깊은 네트워크에서 발생할 수 있는 학습 문제를 완화합니다.
Transformer: Input Layer
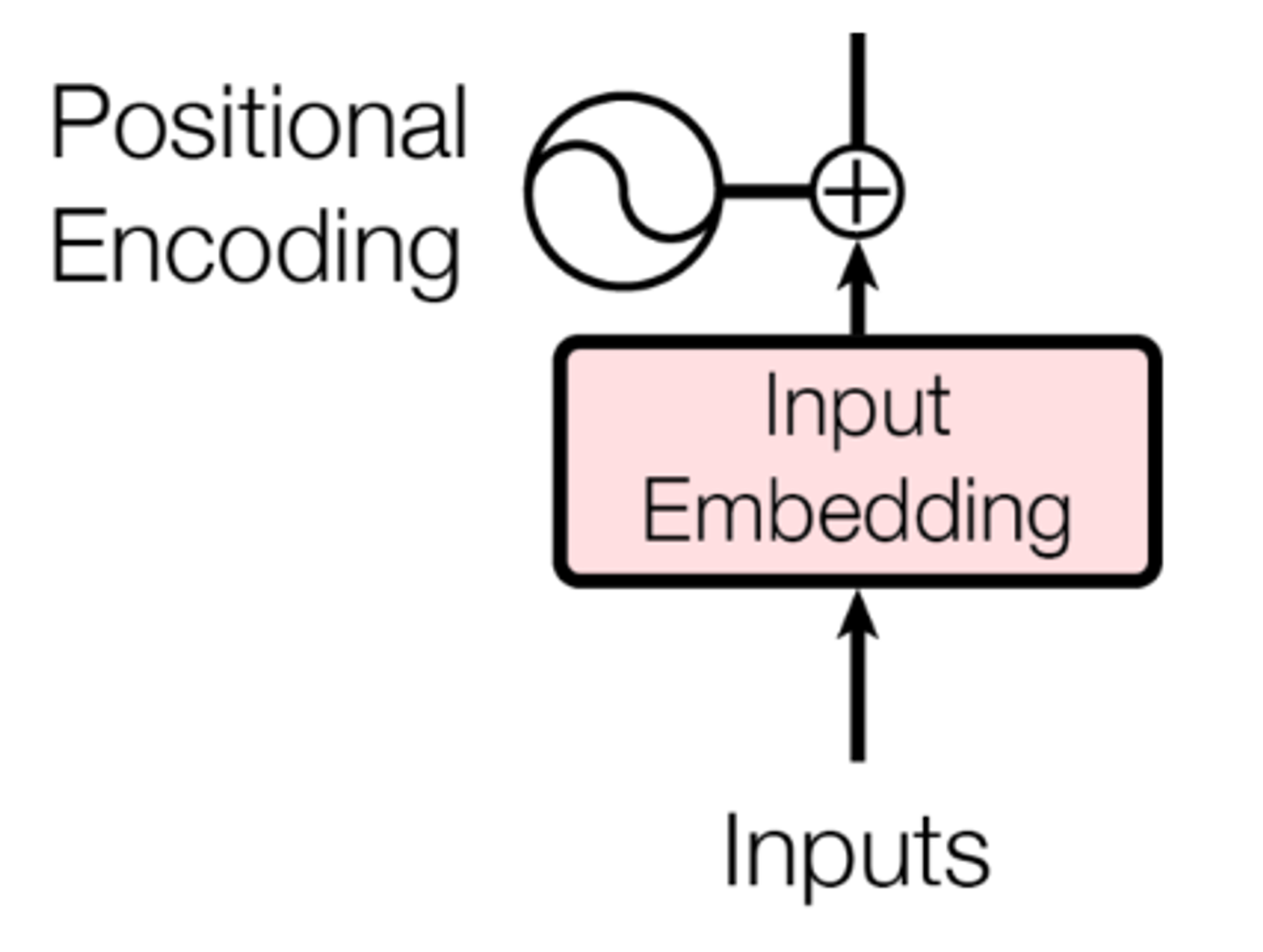
- Encoder Input은 Source Sequence & Input Embedding 값에 위치정보까지 더해서 만듭니다.
- 이때 Encoder Input은 Source 언어 문장의 Token Index Sequence가 됩니다. 한번 예를 들어보겠습니다.
Self-Attention의 Input Layer의 동작방식
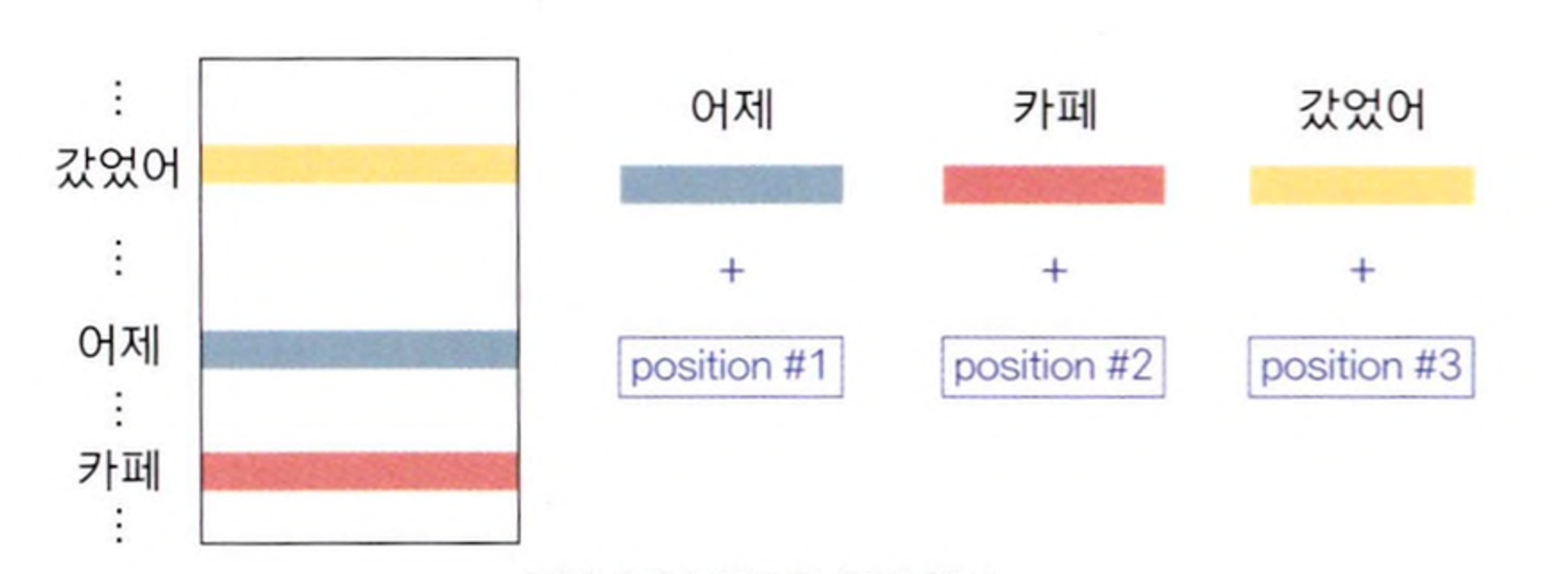
- 예를 들어 소스 언어의 Token Sequence가 "어제, 카페, 갔었어"라면 Encoder Input Layer(인코더 입력층)의 직접적인 입력값은 이들 Token들에 대응하는 인덱스 시퀀스가 되며 Encoder Input(인코더 입력)은 그림과 같은 방식으로 만들어집니다.
- 그리고 Input Embedding에 더하는 위치 정보는 해당 Token이 문장 내에서 몇번째의 위치인지 정보를 나타냅니다.
"어제" 가 첫번째, "카페" 가 두번째, "갔었어" 가 세번째면 → Transformer Model은 이같은 방식으로 소스 언어의 토큰 시퀀스를 이에 대응하는 Vector Sequence(벡터 시퀀스)로 변환해 Incoder input을 만듭니다.
- 그러면 Encoder Input Layer에서 만들어진 Vector Sequence가 최초의 Encoder Block의 Input이 됩니다.
- 그 다음에는 Output Vector Sequence가 두번째 Encoder Block의 Input이 됩니다.
- 그러면 다음 Encoder 블럭의 Input(입력)은 이전 Block의 Output(출력)입니다. 이 과정을 N번 반복합니다.
Transformer: Encoder Layer Example Code
이 코드는 예제 코드입니다. 사용자에 맞춰서 수정을 해야 합니다.
class EncoderLayer(tf.keras.layers.Layer):
def __init__(self, **kargs):
super(EncoderLayer, self).__init__()
self.mha = MultiHeadAttention(**kargs)
self.ffn = point_wise_feed_forward_network(**kargs)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(kargs['rate'])
self.dropout2 = tf.keras.layers.Dropout(kargs['rate'])
def call(self, x, mask):
attn_output, _ = self.mha(x, x, x, mask) # (batch_size, input_seq_len, d_model)
attn_output = self.dropout1(attn_output)
out1 = self.layernorm1(x + attn_output) # (batch_size, input_seq_len, d_model)
ffn_output = self.ffn(out1) # (batch_size, input_seq_len, d_model)
ffn_output = self.dropout2(ffn_output)
out2 = self.layernorm2(out1 + ffn_output) # (batch_size, input_seq_len, d_model)
return out2, attn_outputTransformer: Output Layer
Output Layer는 Transformer 모델의 출력층입니다.
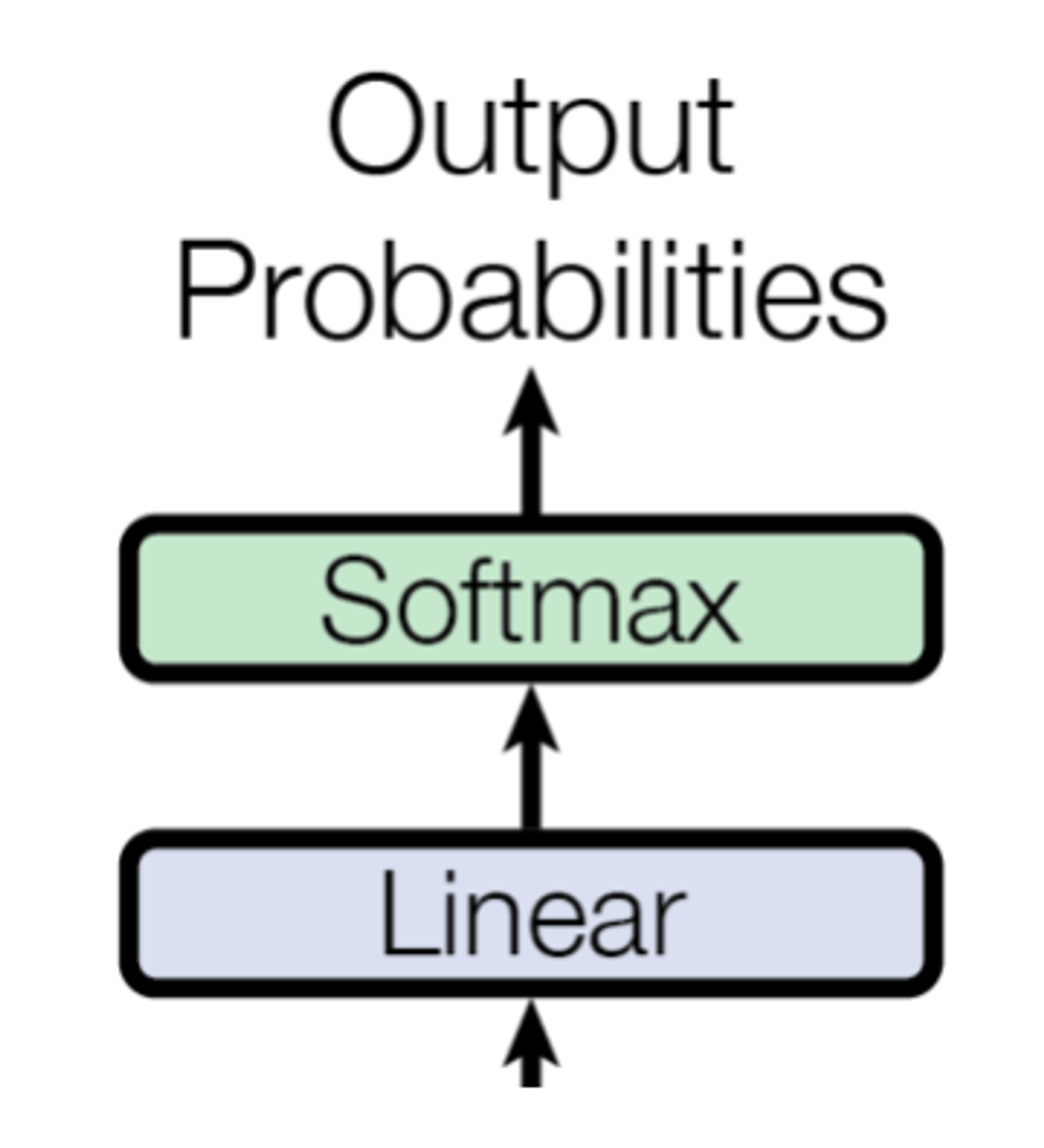
- Output Layer의 출력은 Target 언어의 어휘수만큼 차원을 가지는 확률벡터입니다.
- Multi-Head Attention은 Attention 관련 글에서 다루었으므로, 처음 보는 Position-wise Feed-Forward Network에 데하여 설명해 보겠습니다.
Transformer: Decoder Layer Example Code
이 코드는 예제 코드입니다. 사용자에 맞춰서 수정을 해야 합니다.
class DecoderLayer(tf.keras.layers.Layer):
def __init__(self, **kargs):
super(DecoderLayer, self).__init__()
self.mha1 = MultiHeadAttention(**kargs)
self.mha2 = MultiHeadAttention(**kargs)
self.ffn = point_wise_feed_forward_network(**kargs)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm3 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(kargs['rate'])
self.dropout2 = tf.keras.layers.Dropout(kargs['rate'])
self.dropout3 = tf.keras.layers.Dropout(kargs['rate'])
def call(self, x, enc_output, look_ahead_mask, padding_mask):
# enc_output.shape == (batch_size, input_seq_len, d_model)
attn1, attn_weights_block1 = self.mha1(x, x, x, look_ahead_mask) # (batch_size, target_seq_len, d_model)
attn1 = self.dropout1(attn1)
out1 = self.layernorm1(attn1 + x)
attn2, attn_weights_block2 = self.mha2(
enc_output, enc_output, out1, padding_mask) # (batch_size, target_seq_len, d_model)
attn2 = self.dropout2(attn2)
out2 = self.layernorm2(attn2 + out1) # (batch_size, target_seq_len, d_model)
ffn_output = self.ffn(out2) # (batch_size, target_seq_len, d_model)
ffn_output = self.dropout3(ffn_output)
out3 = self.layernorm3(ffn_output + out2) # (batch_size, target_seq_len, d_model)
return out3, attn_weights_block1, attn_weights_block2Feed-Forward Networks
Position-wise Feed-Forward Network에 데하여 설명을 드릴려고 했는데, 이건 Transformer 모델의 특정 Context(문맥)에서만 사용되는 FFN(Feed-Forward Network)이라고 합니다. 그래서 일단 Feed-Forward Network에 데한 설명을 먼저 한 다음에 Position-wise Feed-Forward Network에 데한 설명을 이어서 하도록 하겠습니다.
Feed-Forward Networks (FFN)
- Feed-Forward Networks는 가장 기본적인 인공 신경망 구조중 하나로, Input Layer(입력층)에서 Output Layer(출력층)으로 데이터가 순방향으로 흐르는 구조를 의미합니다.
- 여기서 Data는 각 Layer(층)을 지날 때마다 가중치에 의해 변환되고, Activation Function(활성화 함수)를 통해 다음 Layer(층)으로 전달됩니다.
- 이러한 네트워크는 순환 연결이나 복잡한 Feedback 루프가 없어서 계산이 비교적 간단하고, 다양한 문제에 적용될 수 있습니다.
- 정리하자면, 데이터가 네트워크를 통해 한 방향으로만 흐른다는 것을 의미합니다. 입력 데이터는 Input Layer(입력층)에서 시작하여 Hidden Layer(은닉층)을 거쳐 Output Layer(출력층)으로 전달되며, 각 층에서는 Activation Function(활성화 함수)를 통해 처리됩니다. 이 과정에서 순환(loop)이나 되돌아가는(feedback) 연결은 없으며, 각 층은 이전 층의 출력을 다음 층의 Input(입력)으로만 사용합니다.
Feed-Forward Networks (FFN)의 기본적인 형태
- FNN(Feed-Forward Networks)은 인공신경망의 기본적인 형태입니다.
- 다수의 Input(입력) Node, Weight(가중치), Activation Function(활성화 함수)를 통해 출력 노드로 정보를 전달합니다.
- 이때 Weight(가중치)는 학습 과정에서 업데이트 되며, 초기 Weight(가중치)는 보통 무작위로 결정됩니다.
- FNN(Feed-Forward Networks)는 MLP, Multi-Layer Perceptron(다중 퍼셉트론)이라고도 불리며, Hidden Layer(은닉층)이 하나 이상인 인공신겸망을 의미합니다.
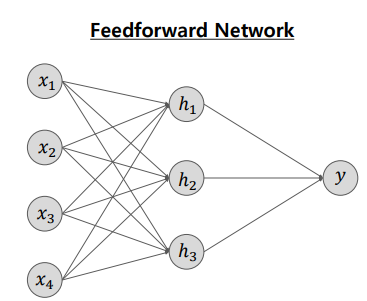
Feed-Forward Networks (FFN)의 네트워크 구조
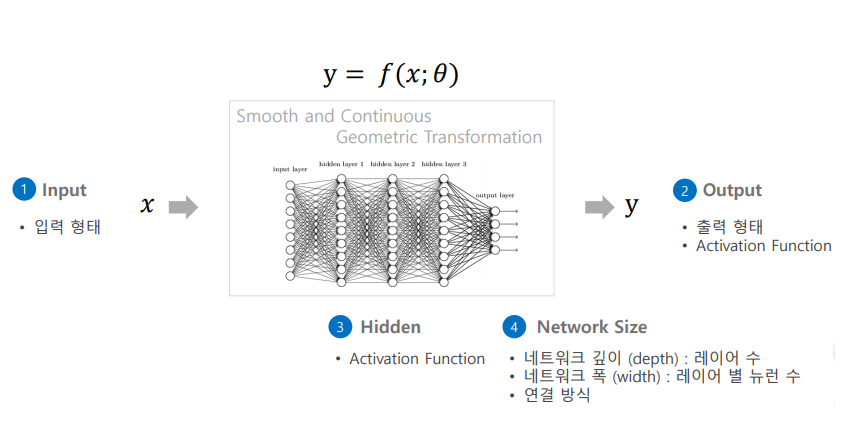
- 이 글에서는 Transformer 모델을 다루기 위해서 자세한 설명은 나중에 Deep_Learning 파트에서 설명하도록 하겠습니다.
Summary: "Feed-Forward Networks"는 넓은 의미에서는 데이터가 순방향으로 전달되는 신경망 구조를 의미하며, 다양한 Context 및 구조에서 사용될 수 있습니다.
Position-wise Feed-Forward Networks(PFFN)
Position-wise Feed-Forward Networks 에 대한 정의를 한번 보도록 하겠습니다.
Transformer내에서 Position-wise Feed-Forward Networks의 정의
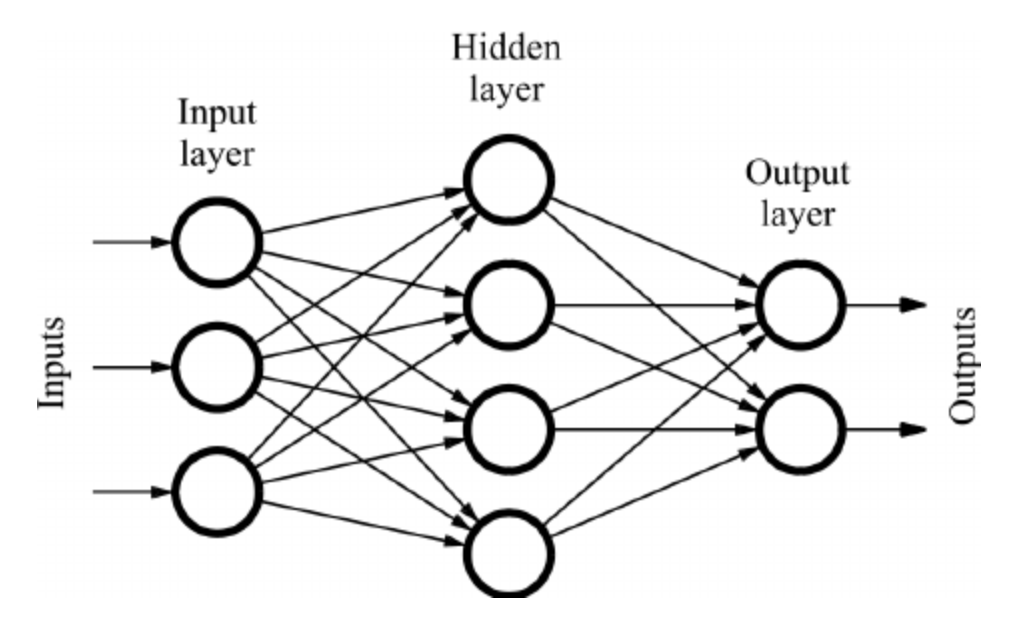
- Transformer 모델 내에서 "Position-wise Feed-Forward Networks"는 특별한 유형의 FFN(Feed-Forward Networks) - *Fully Connected Feed-Forward Network 을 의미합니다.
- 이 네트워크는 Transformer 모델 내에서 각 Encoder, Decoder 내에 존재하며, Sequence의 각 위치(Position)에 있는 Word Vector(단어 벡터)에 독립적으로 동일한 네트워크를 적용합니다.
- 즉, Sequence 내 모든 단어(or Token)들은 각자의 위치에서 FFN(Feed-Forward Networks)를 거치게 되는데, 보통 2개의 Linear Transformation(선형 변환) & 하나의 NonLinear Function (비선형 함수 - Ex. ReLU함수)로 구성됩니다.
- Position-wise라는 용어는 이 네트워크의 Sequence가 각 위치마다 독립적으로 적용된다는 점을 강조합니다.
* Fully Connected Feed-Forward Network: 네트워크의 한층에 있는 모든 Neuron이 이전층(Layer)의 모든 Neuron과 연결되어 있음을 의미합니다. 즉, Fully Connected 구조는 네트워크의 각 Layer가 전체적으로 연결된 구조를 의미합니다.
Position-wise Feed-Forward Networks
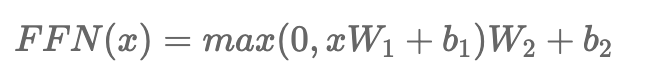
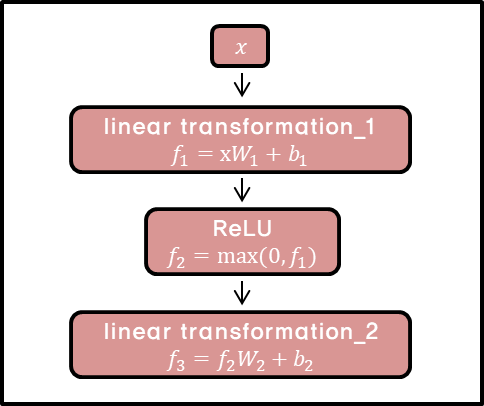
- x에 Linear Transformation(선형 변환)을 적용한 뒤, NonLinear Function(비선형함수)인 ReLU함수(max(0, z)를 거쳐 다시한번 Linear Transformation(선형 변환)을 적용합니다.
- 이때 각각의 Position마다 같은 Parameter(매개변수)인 W, b를 사용하지만, 만약 Layer가 달라지면 다른 Parameter를 사용합니다.
Point-Wise Feed Forward Network Example Code
이 코드는 예제 코드입니다. 사용자에 맞춰서 수정을 해야 합니다.
def point_wise_feed_forward_network(**kargs):
return tf.keras.Sequential([
tf.keras.layers.Dense(kargs['dff'], activation='relu'), # (batch_size, seq_len, dff)
tf.keras.layers.Dense(kargs['d_model']) # (batch_size, seq_len, d_model)
])Self-Attention
Self-Attention에 관한 내용은 Attention에 관한 글에 설명을 해놓았으니, 이 글에서는 개념만 설명하겠습니다. 예시 코드는 아래의 글을 참고해주세요!
[NLP] Attention - 어텐션
1. Attention Attention은 CS 및 ML에서 중요한 개념중 하나로 여겨집니다. Attention의 매커니즘은 주로 Sequence Data를 처리하거나 생성하는 모델에서 사용됩니다. -> Sequence 입력을 수행하는 머신러닝 학습
daehyun-bigbread.tistory.com
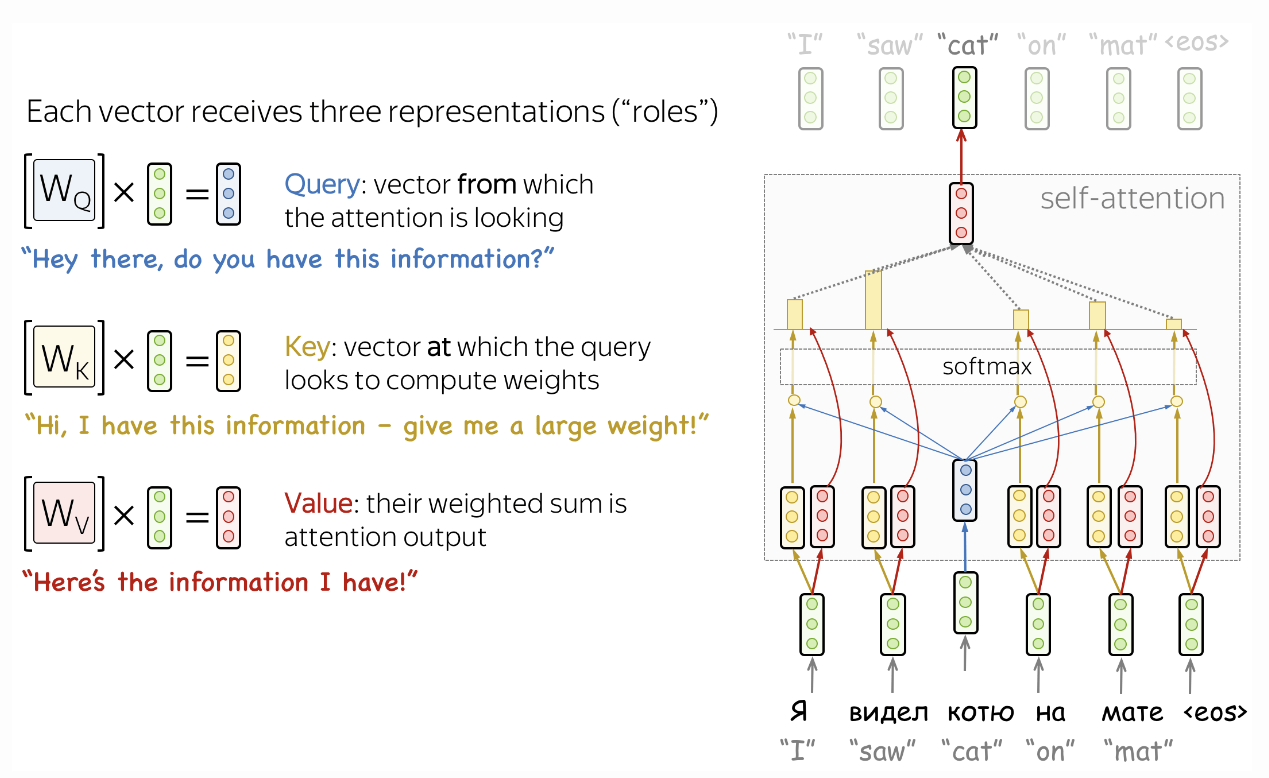
Self-Attention 기법은 Attention 기법을 말 그대로 자기 자신에게 수행하는 Attention 기법입니다.
- Input Sequence 내의 각 요소간의 상대적인 중요도를 계산하는 매커니즘이며, Sequence의 다양한 위치간의 서로 다른 관계를 학습할 수 있습니다.
- Sequence 요소 가운데 Task 수행에 중요한 Element(요소)에 집중하고 그렇지 않은 Element(요소)는 무시합니다.
- 이러면 Task가 수행하는 성능이 상승할 뿐더러 Decoding 할때 Source Sequence 가운데 중요한 Element(요소)들만 추립니다.
- 문맥에 따라 집중할 단어를 결정하는 방식을 의미 -> 중요한 단어에만 집중을 하고 나머지는 그냥 읽습니다.
- 이 방법이 문맥을 파악하는 핵심이며, 이러한 방식을 Deep Learning 모델에 적용한것이 'Attention' 매커니즘이며, 이 매커니즘을 자기 자신에게 적용한것이 'Self-Attention' 입니다. 한번 매커니즘을 예시를 들어서 설명해 보겠습니다.
Self-Attention의 계산 예시
Self-Attention은 Query(쿼리), Key(키), Value(밸류) 3가지 요소가 서로 영향을 주고 받는 구조입니다.
- 문장내 각 단어가 Vector(벡터) 형태로 input(입력)을 받습니다.
* Vector: 숫자의 나열 정도
- 각 단어의 Vector는 3가지 과정을 거쳐서 반환이 됩니다.
- Query(쿼리) - 내가 찾고 정보를 요청하는것 입니다.
- Key(키) - 내가 찾는 정보가 있는 찾아보는 과정입니다.
- Value(밸류) - 찾아서 제공된 정보가 가치 있는지 판단하는 과정입니다.

- 위의 그림을 보면 입력되는 문장 "어제 카페 갔었어 거기 사람 많더라" 이 6개 단어로 구성되어 있다면?
- 여기서의 Self-Attention 계산 대상은 Query(쿼리) Vector 6개, Key(키) Vector 6개, Value(밸류) Vector 6개등 모두 18개가 됩니다.

- 위의 표는 더 세부적으로 나타낸것입니다. Self-Attention은 Query 단어 각각에 대해 모든 Key 단어와 얼마나 유기적인 관계를 맺고 있는지의 확률값들의 합이 1인 확률값으로 나타냅니다.
- 이것을 보면 Self-Attention 모듈은 Value(밸류) Vector들을 Weighted Sum(가중합)하는 방식으로 계산을 마무리 합니다.
- 확률값이 가장 높은 키 단어가 쿼리 단어와 가장 관련이 높은 단어라고 할 수 있습니다.
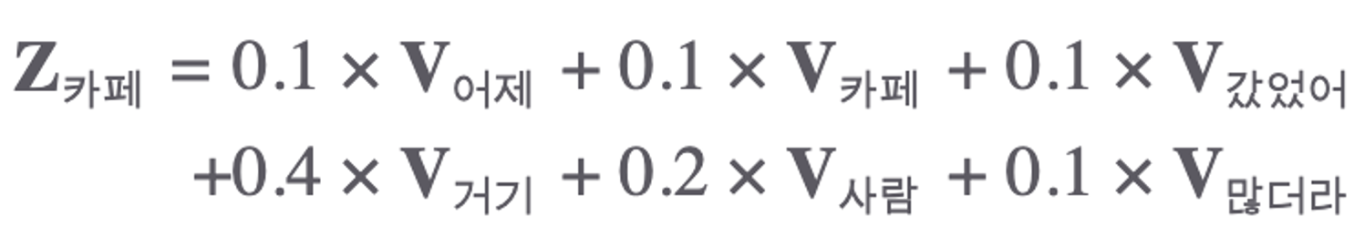
- 여기서는 '카페'에 대해서만 계산 예시를 들었지만, 이러한 방식으로 나머지 단어들오 Self-Attention을 각각 수행합니다.
Self-Attention의 동작 방식
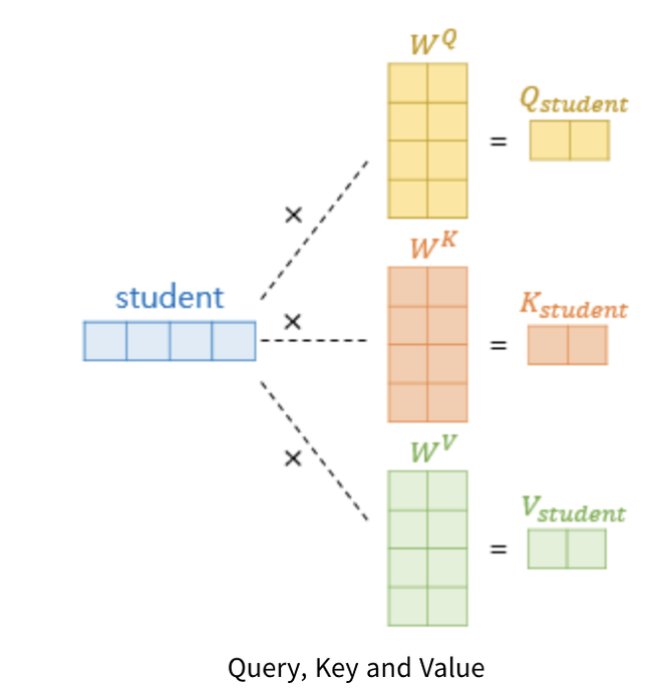
Self-Attention에서 가장 중요한 개념은 Query(쿼리), Key(키), Value(밸류)의 시작값이 동일하다는 점입니다.
- 그렇다고 Query(쿼리), Key(키), Value(밸류)가 동일 하다는 말이 이닙니다.
- 그림을 보면 가중치 Weight W값에 의해서 최종적인 Query(쿼리), Key(키), Value(밸류)값은 서로 달라집니다.
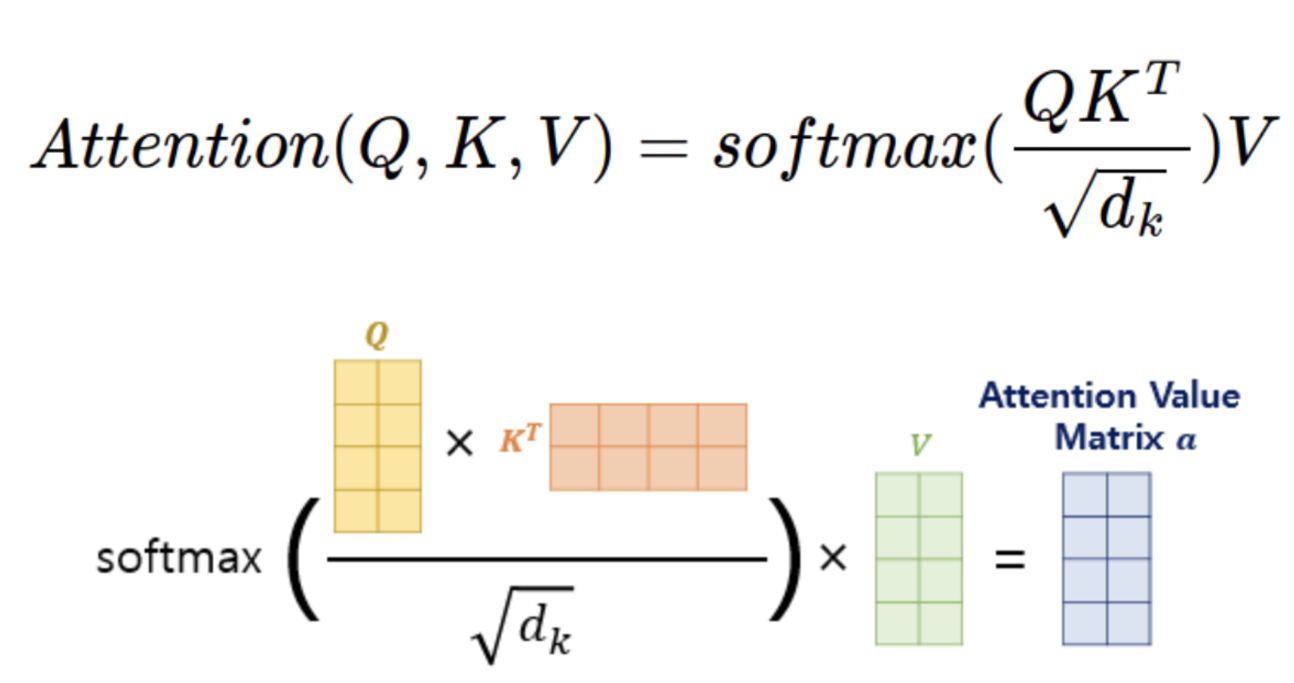
Attention을 구하는 공식을 보겠습니다.
- 일단 Query(쿼리)랑 Key(키)를 내적해줍니다. 이렇게 내적을 해주는 이유는 둘 사이의 연관성을 계산하기 위해서입니다.
- 이 내적된 값을 "Attention Score"라고 합니다. Dot-Product Attention 부분에서 자세히 설명 했지만 이번에는 간단하게 설명해 보겠습니다.
- 만약, Query(쿼리)랑 Key(키)의 Dimension(차원)이 커지면, 내적 값의 Attention Score가 커지게 되어서 모델이 학습하는데 어려움이 생깁니다.
- 이 문제를 해결하기 위해서 차원 d_k의 루트만큼 나누어주는 Scaling 작업을 진행합니다. 이과정을 "Scaled Dot-Product Attention" 이라고 합니다.
- 그리고 Scaled Dot-Product Attention"을 진행한 값을 정규화를 진행해주기 위해서 Softmax 함수를 거쳐서 보정을 위해 계산된 score행렬, value행렬을 내적합니다. 그러면 최종적으로 Attention 행렬을 얻을 수 있게 됩니다. 예시 문장을 들어서 설명해 보겠습니다.
"I am a student"라는 문장으로 예시를 들어보겠습니다.
- Self-Attention은 Query(쿼리), Key(키), Value(밸류) 3개 요소 사이의 문맥적 관계성을 추출합니다.
Q = X * Wq, K = X * Wk, W = X * Wv
- 위의 수식처럼 Input Vector Sequence(입력 벡터 시퀀스) X에 Query(쿼리), Key(키), Value(밸류)를 만들어주는 행렬(W)를 각각 곱해줍니다.
- Input Vector Sequence(입력 벡터 시퀀스)가 4개이면 왼쪽에 있는 행렬을 적용하면 Query(쿼리), Key(키), Value(밸류) 각각 4개씩, 총 12개가 나옵니다.
* Word Embedding: 단어를 Vector로 변환해서 Dense(밀집)한 Vector공간에 Mapping 하여 실수 Vector로 표현합니다.
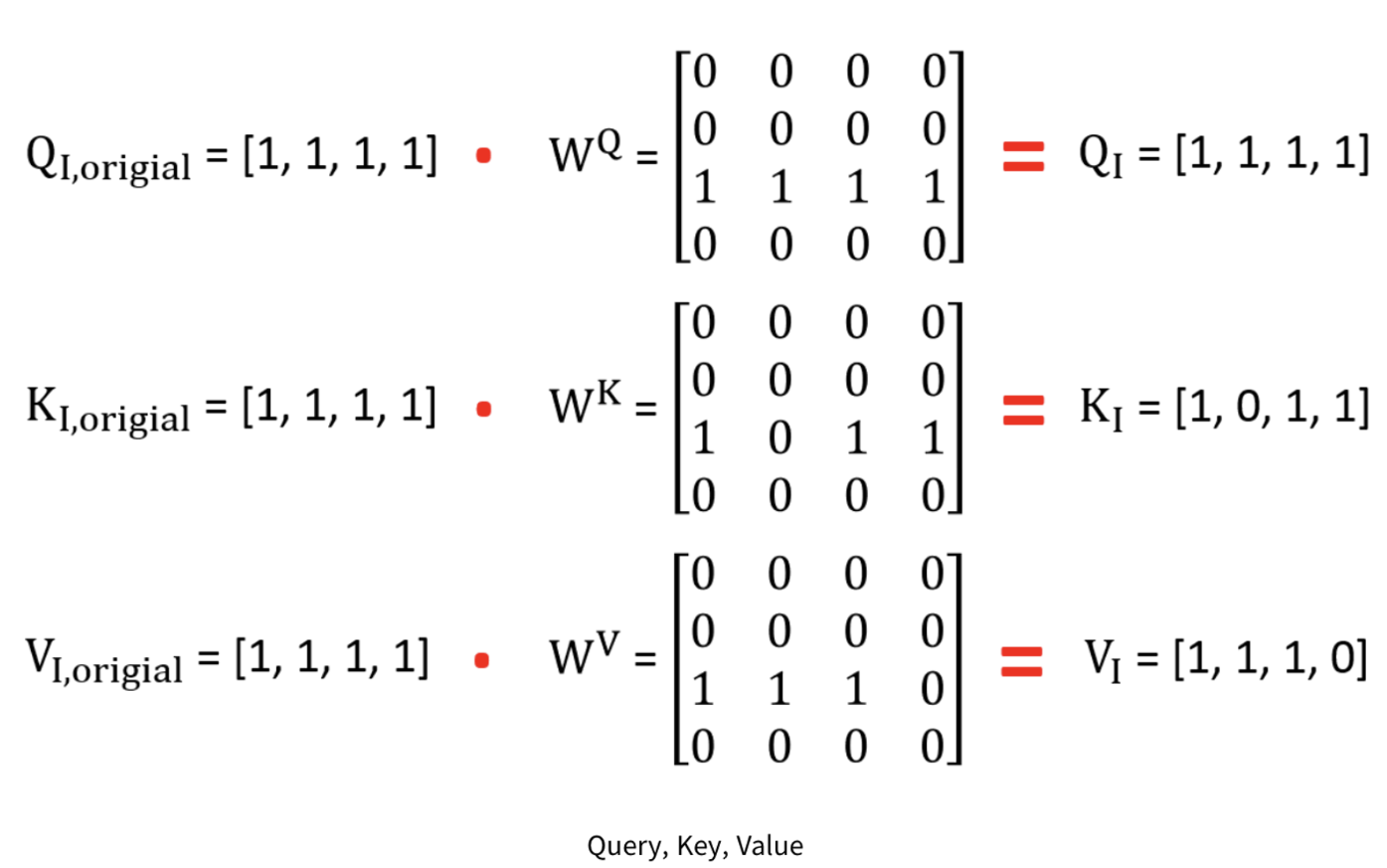
- 각 단어에 데하여 Word Embedding(단어 임베딩)을 합니다. 단어 'i'의 Embedding이 [1,1,1,1]이라고 했을 때, 처음 'i'의 처음 Query(쿼리), Key(키), Value(밸류)를 각각 'Q_i, original', 'K_i, original', 'V_i, original', 라고 합니다.
- Embedding의 값이 다 [1,1,1,1]로 같은 이유는 Self-Attention 매커니즘에서는 같아야 하기 때문에 모두 [1,1,1,1]이라고 동일합니다.
- 학습된 Weight(가중치)값이 'WQ', 'WK', 'WV'라고 할때 Original 값들과 점곱을 해주면 최종적으로 'Q', 'K', 'V'값이 도출됩니다.
- 'Q', 'K', 'V'값을 이용해서 위에서 설정한 보정된 'Attention Score'를 곱해주면 아래의 왼쪽식과 같이 1.5라는 값이 나옵니다.
- 행렬 'Q', 'K'는 서로 점곱 계산해주고, 여기서 행렬 'Q', 'K', 'V'의 Dimension(차원)은 4이므로 루트 4로 나누어줍니다.
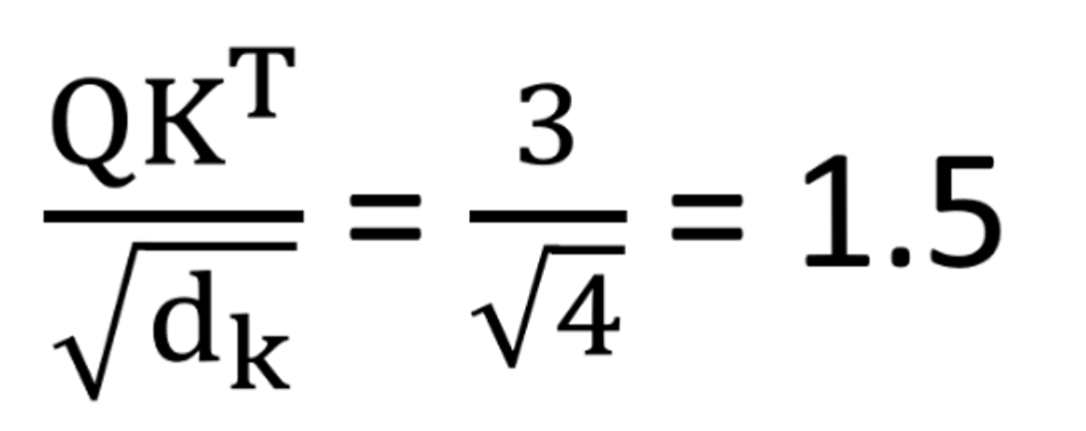
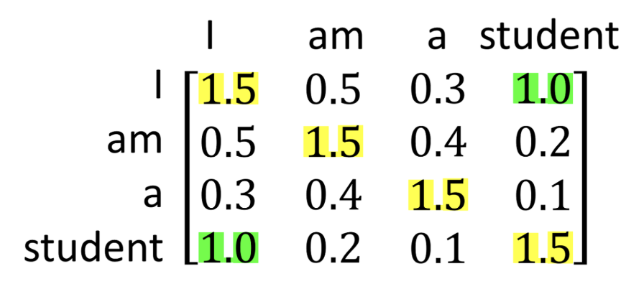
- 'i' 뿐만 아니라 모든 단어간의 'Self-Attention'을 해주면 위의 오른쪽 행렬과 같은 결과가 나옵니다.
- 가운데 노락색 부분은 자기 자신에 대한 'Attention'이므로 당연히 값이 제일 크고, 양쪽 초록색 부분을 보면 점수가 높습니다.
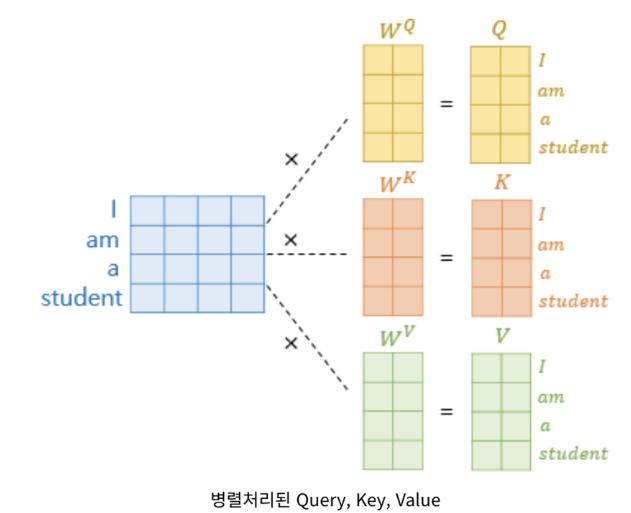
- 위의 그림은 단어 하나하나의 'Attention'을 구하는 과정을 도식화 한 그림입니다.
- 실제로는 여러 단어를 위의 그림과 같이 병렬 처리를 해서 계산을 합니다.
- 병렬처리를 하면 연산속도가 빨리지는 이점이 있기 때문입니다. 간단히 'Self-Attention' 과정을 요약해서 설명해보겠습니다.
Self-Attention 과정 Summary
1. 원하는 문장을 임베딩하고 학습을 통해 각 Query, Key, Value에 맞는 weight들을 구해줌.
2. 각 단어의 임베딩의 Query, Key, Value(Query = Key = Value)와 weight를 점곱(내적)해 최종 Q, K, V를 구함.
3. Attention score 공식을 통해 각 단어별 Self Attention value를 도출
4. Self Attention value의 내부를 비교하면서 상관관계가 높은 단어들을 도출
Multi-Head Attention
Multi-Head Attention도 개념만 설명하겠습니다. 예시 코드는 위에 Attention 관련한 글에 예시 코드를 만들어 놓았으니 필요하신분은 확인해주세요!
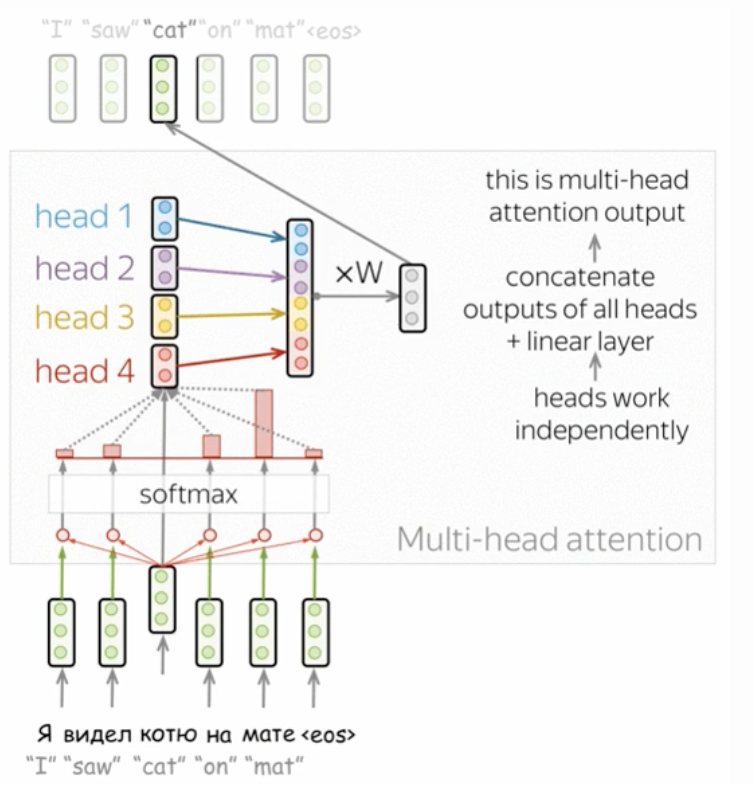
Multi-Head Attention은 여러개의 'Attention Head'를 가지고 있습니다. 여기서 각 'Head Attention'에서 나온 값을 연결해 사용하는 방식입니다.
- 한번의 'Attention'을 이용하여 학습을 시키는것 보다는 'Attention'을 병렬로 여러개 사용하는 방식입니다.
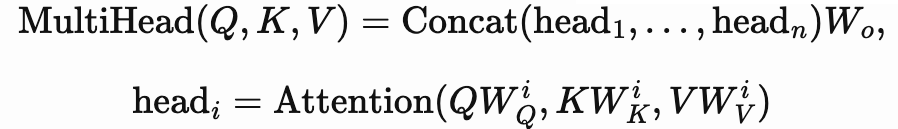
- 순서는 원래의 Query(쿼리), Key(키) Value(밸류) 행렬 값을 Head수 만큼 분할합니다.
- 분할한 행렬 값을 통해, 각 'Attention' Value값들을 도출합니다.
- 도출된 'Attention value'값들을 concatenate(쌓아 합치기)하여서 최종 'Attention Value'를 도출합니다.
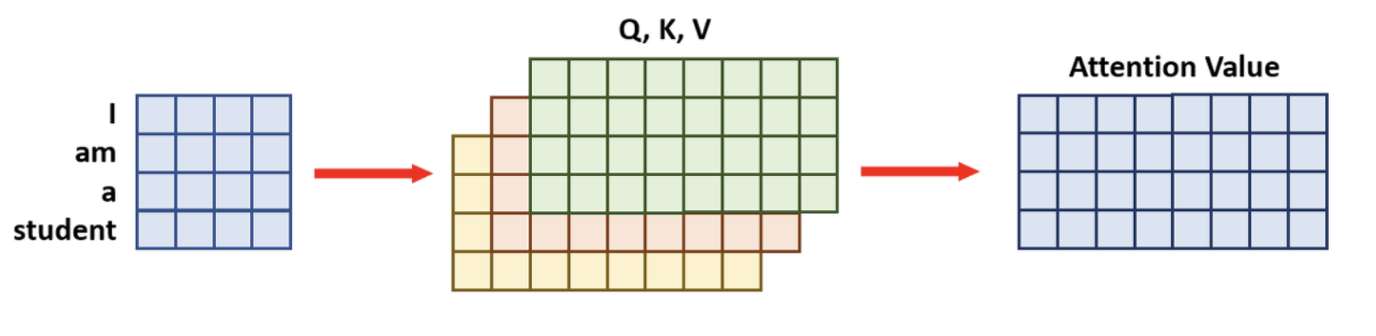
- [4x4] 크기의 문장 Embedding Vector와 [4x8]의 Query(쿼리), Key(키) Value(밸류)가 있을 때, 일반적인 한 번에 계산하는 Attention 메커니즘은 [4x4]*[4x8]=[4x8]의 'Attention Value'가 한 번에 도출됩니다.
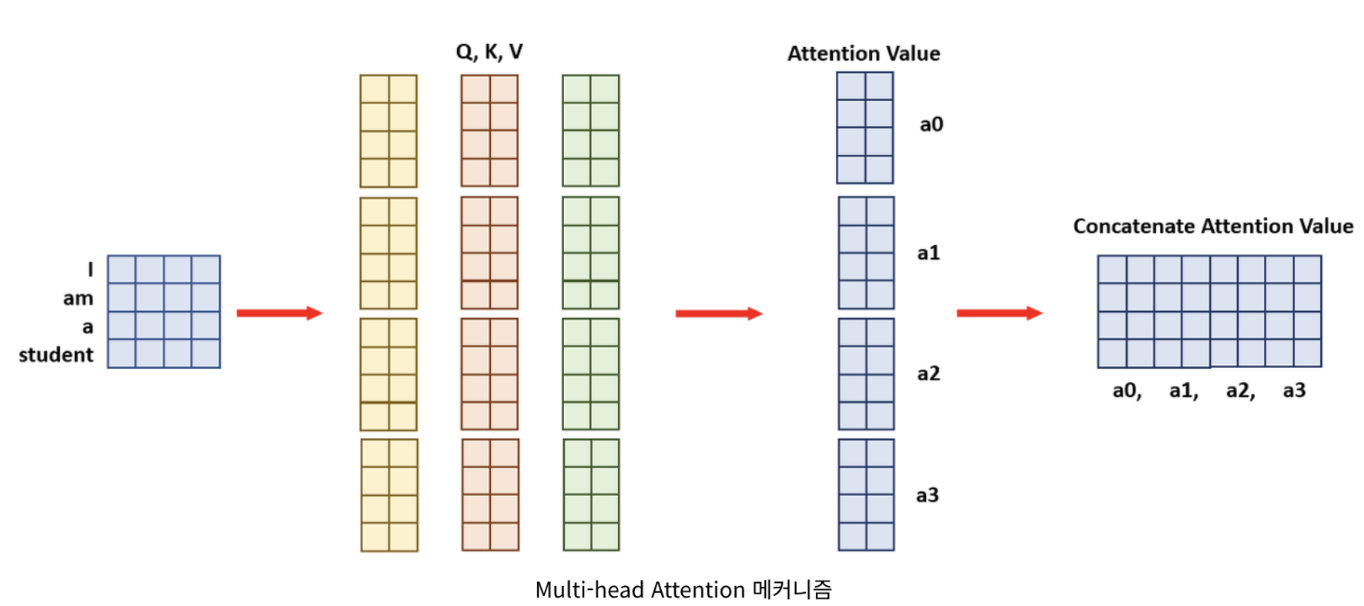
- 'Multi-Head Attention' 매커니즘으로 보면 여기서 Head는 4개 입니다. 'I, am, a, student'
- Head가 4개 이므로 각 연산과정이 1/4만큼 필요합니다.
- 위의 그림으로 보면 크기가 [4x8]이었던, Query(쿼리), Key(키) Value(밸류)를 4등분 하여 [4x2]로 만듭니다. 그러면 여기서의 'Attention Value'는 [4x2]가 됩니다.
- 이 'Attention Value'들을 마지막으로 Concatenate(합쳐준다)합쳐주면, 크기가 [4x8]가 되어 일반적인 Attention 매커니즘의 결과값과 동일하게 됩니다. 예시를 한번 들어보겠습니다.
Summary: Query(쿼리), Key(키), Value(밸류)값을 한 번에 계산하지 않고 head 수만큼 나눠 계산 후 나중에 Attention Value들을 합치는 메커니즘. 한마디로 분할 계산 후 합산하는 방식.
Multi-Head Attention Example

- 입력 단어 수는 2개, 밸류의 차원수는 3, 헤드는 8개인 멀티-헤드 어텐션을 나타낸 그림 입니다.
- 개별 헤드의 셀프 어텐션 수행 결과는 ‘입력 단어 수 ×, 밸류 차원수’, 즉 2×3 크기를 갖는 행렬입니다.
- 8개 헤드의 셀프 어텐션 수행 결과를 다음 그림의 ①처럼 이어 붙이면 2×24 의 행렬이 됩니다.
- Multi-Head Attention의 최종 수행 결과는 '입력 단어 수' x '목표 차원 수' 이며, Encoder, Decoder Block 모두에 적용됩니다.
Multi-Head Attention은 개별 Head의 Self-Attention 수행 결과를 이어 붙인 행렬 (①)에 W0를 행렬곱해서 마무리 된다.
→ 셀프 어텐션 수행 결과 행렬의 열(column)의 수 × 목표 차원수
Multi-Head Attention 부가 설명
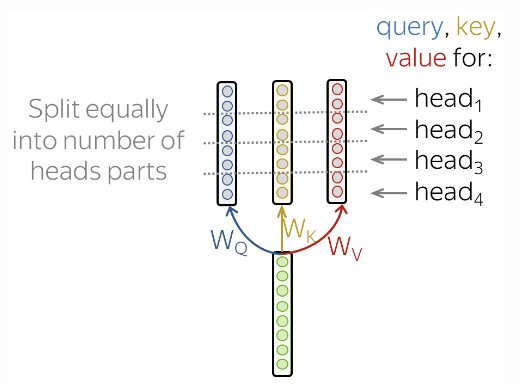
- 위의 사진에서는 하나의 Head-Attention을 위해 계산한 Query(쿼리), Key(키), Value(밸류) 값을 여러 부분으로 분할합니다.
- 이러한 방식으로 하나 또는 여러개의 Attention Head가 있는 모델은 동일한 크기를 가집니다.
- 이말을 정리하면, Multi-Head Attention은 Model의 크기를 늘리지 않고 동일한 크기를 가지지만, 계산한 Query(쿼리), Key(키), Value(밸류) 값을 여러 부분으로 분할합니다.
Multi-Head Attention Example Code
이 코드는 예제 코드입니다. 사용자에 맞춰서 수정을 해야 합니다.
- Multi-Head Attention Input = Output
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, **kargs):
super(MultiHeadAttention, self).__init__()
self.num_heads = kargs['num_heads']
self.d_model = kargs['d_model']
assert self.d_model % self.num_heads == 0
self.depth = self.d_model // self.num_heads
self.wq = tf.keras.layers.Dense(kargs['d_model']) # Multi-Head Attetion Input = Output
self.wk = tf.keras.layers.Dense(kargs['d_model'])
self.wv = tf.keras.layers.Dense(kargs['d_model'])
self.dense = tf.keras.layers.Dense(kargs['d_model'])
def split_heads(self, x, batch_size):
"""Split the last dimension into (num_heads, depth).
Transpose the result such that the shape is (batch_size, num_heads, seq_len, depth)
"""
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, v, k, q, mask):
batch_size = tf.shape(q)[0]
q = self.wq(q) # (batch_size, seq_len, d_model)
k = self.wk(k) # (batch_size, seq_len, d_model)
v = self.wv(v) # (batch_size, seq_len, d_model)
q = self.split_heads(q, batch_size) # (batch_size, num_heads, seq_len_q, depth)
k = self.split_heads(k, batch_size) # (batch_size, num_heads, seq_len_k, depth)
v = self.split_heads(v, batch_size) # (batch_size, num_heads, seq_len_v, depth)
# scaled_attention.shape == (batch_size, num_heads, seq_len_q, depth)
# attention_weights.shape == (batch_size, num_heads, seq_len_q, seq_len_k)
scaled_attention, attention_weights = scaled_dot_product_attention(
q, k, v, mask)
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3]) # (batch_size, seq_len_q, num_heads, depth)
concat_attention = tf.reshape(scaled_attention,
(batch_size, -1, self.d_model)) # (batch_size, seq_len_q, d_model)
output = self.dense(concat_attention) # (batch_size, seq_len_q, d_model)
return output, attention_weightsPositional Encoding
Transformer 모델에서의 Positinal encoding은 Sequence 내 단어들의 상대적인 위치 정보를 주입하는데 사용합니다.
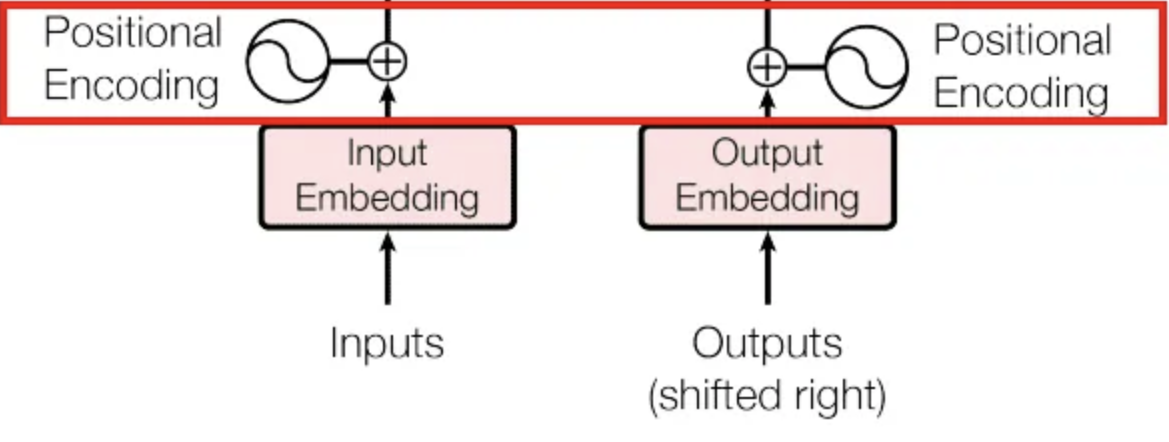
- 다시 설명하면, Model이 단어의 순서를 이해하고, 효과적으로 처리하게 도와줍니다.
- Transformer Model에서 주로 사용되는 Positional encoding 방법은 Sin(사인)함수, Cos(코사인)함수를 사용합니다.

- 한번 수식을 보면 PE는 Positional Encoding Matrix의 요소입니다.
- 이말은 Input Sequence(입력 시퀀스)의 각 위치(또는 단어)에 대한 고유한 위치 정보를 제공하는데 사용되는 행렬(matirx)의 각 원소(element)를 지칭합니다.
- Transformer 모델은 Sequence의 순서 정보를 내재적으로 처리를 못하기 때문에, 위치 정보를 모델에 주입해야합니다.
- pos는 Sequence에서 단어 또는 Token의 위치(index)를 의미합니다.
- i는 Positional Encoding Vector 내에 차원의 Index. 즉, Encoding 차원(d_model)내의 Index를 나타냅니다.
- d_model은 모델의 Embedding Dimension(임베딩 차원), 모든 Input Token(입력 토큰)이 변환되는 Vector의 크기를 의미합니다.
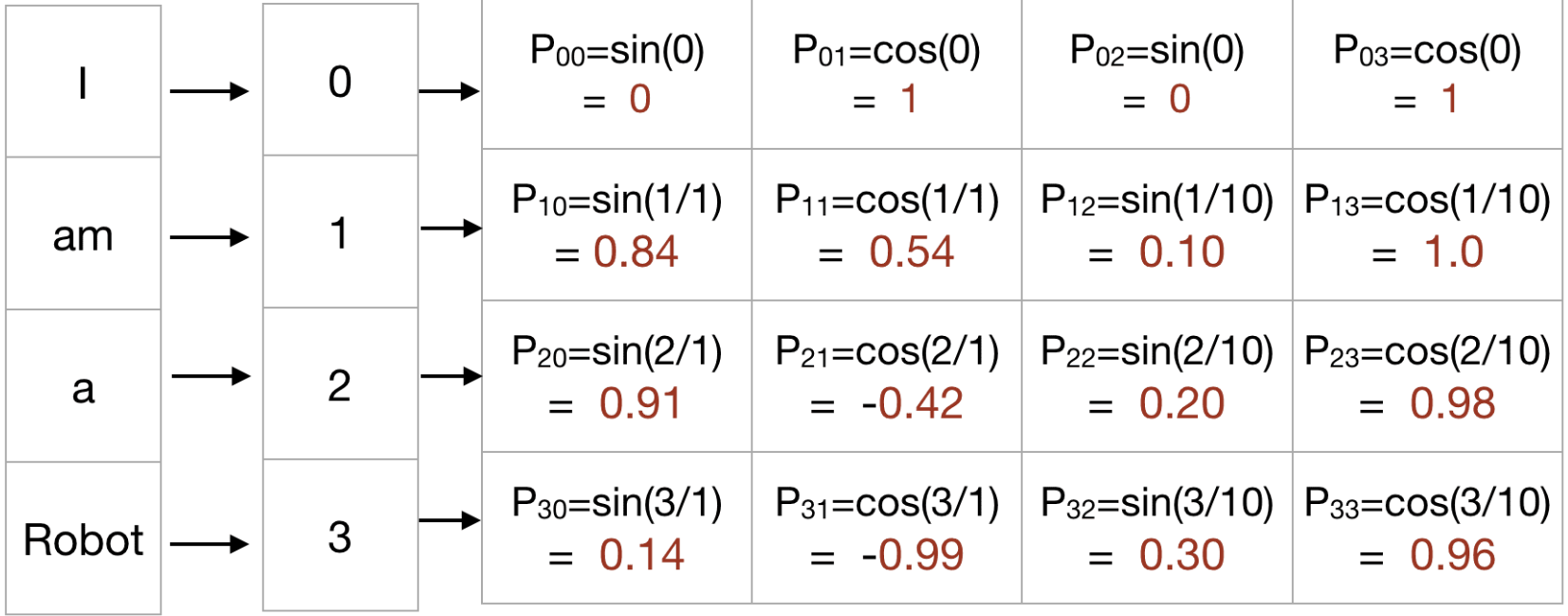
한번 예시를 "I am a Robot"으로 들어보겠습니다.
- 'Pos'는 Input Sequence(입력 시퀀스)에서의 객체의 위치입니다.
- 입력시퀀스의 길이는 0 <= pos < L / 2 입니다, L은 Input Sequence(입력 시퀀스-Token)의 길이입니다.
- 'd_model' 은 Output Embedding 공간의 Dimension(차원)입니다.
- 'PE(pos, 2i)' 는 위치를 Mapping 하는 함수이며, Indexing할 Input Sequence의 위치를 나타냅니다.
- '10000' 은 Transformer 논문에서 Positional Encoding 수식에서 설정된 사용자의 정의 Scaler(스칼라)입니다. 다른곳에서 설명한 수식에는 10000 대신 'n' 이라고 지칭하기도 합니다.
- 'i' 는 열 index에 매칭하는데 사용됩니다. 0< <= i < d_model / 2 입니다.
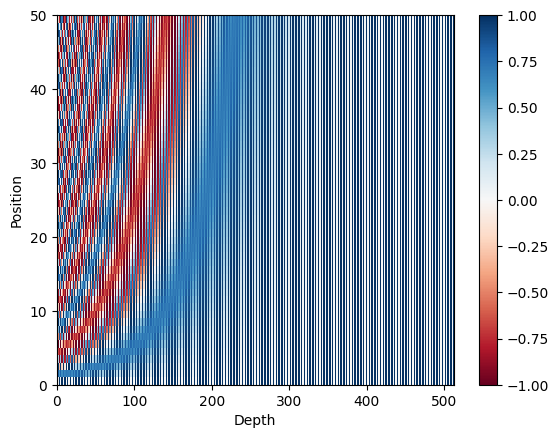
위의 Matrix표를 보시면 짝수 위치는 Sin 함수에 해당하고, 홀수 위치는 Cos 함수에 해당하는 것을 알 수 있습니다.
- 한번 '10000' 을 '100' 으로 낮추고, 'd_model' - Output Embedding 공간의 Dimension(차원)을 4로 하고 계산해보면 아래와 같은 Encoding Matrix를 볼 수 있습니다.
Positional Encoding은 주기적인 패턴을 생성합니다.
- Positional Encoding 수식에서의 사용되는 Sin, Cos 함수안에 들어가는 공식은 주기적인 패턴을 생성합니다.
- 주기적인 값을 생성하면서 서로 다른 위치에 데하여 고유한 값을 생성하는 목적으로 사용됩니다.
- Positional Encoding에서 서로 다른 위치에 데하여 생성한 고유한 값은 단어의 상대적인 위치를 Embedding 공간에 반영하여 Transformer 모델이 문장의 순서를 인식하도록 도와줍니다.
Scaling
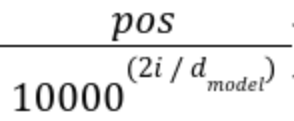
- Scaling은 Positional Encoding에서의 위치 'pos' 에 대한 Scaling 역할을 하며, 다양한 위치의 값들을 생성하는 역할을 합니다.
'Pos'는 Input Sequence(입력 시퀀스)에서의 객체의 위치입니다.
입력시퀀스의 길이는 0 <= pos < L / 2 입니다, L은 Input Sequence(입력 시퀀스-Token)의 길이입니다.
홀수/짝수 Dimension 구분
- 위에서 Positional Encoding Matrix 표를 보시면 왼쪽에서 2번째 표를 보면 "0, 1, 2, 3"이라고 있습니다.
- 이건 차원을 나타내는 숫자인데, 여기서 홀수 숫자는 Cos(코사인)함수가 홀수 Dimension(차원), 짝수 숫자는 SIn(사인)함수는 짝수 Dimension(차원)을 처리하여 Dimension(차원)간 다양성을 확보합니다.
- 이렇게 하면 각 Dimension(차원)이 서로 다른 정보를 담당하게 되며, Model이 단어의 상대적인 위치를 효과적으로 학습할 수 있습니다.
Positional Encoding Example Code
이 코드는 예제 코드입니다. 사용자에 맞춰서 수정을 해야 합니다.
- Sin, Cos 함수 만들고 값들을 겹치지 않게 해야 합니다.
- "Embedding"은 정보를 효과적으로 표현하고 처리할 수 있도록 데이터를 저차원 공간에 매핑하는 기술- "Mapping"은 일반적으로 한 세트의 값에서 다른 세트의 값으로 대응시키는 것을 의미합니다.
- embedding dimension 이 달라져도 positional encoding으로 고정된 값으로 들어옵니다.
- 신경망 모델에서 입력 데이터를 저차원의 공간으로 변환홥니다.
def get_angles(pos, i, d_model):
angle_rates = 1 / np.power(10000, (2 * i//2) / np.float32(d_model))
return pos * angle_ratesdef positional_encoding(position, d_model):
angle_rads = get_angles(np.arange(position)[:, np.newaxis],
np.arange(d_model)[np.newaxis, :],
d_model)
# apply sin to even indices in the array; 2i
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])
# apply cos to odd indices in the array; 2i+1
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])
pos_encoding = angle_rads[np.newaxis, ...]
return tf.cast(pos_encoding, dtype=tf.float32)이렇게 Embedding Layer로 사용합니다.
pos_encoding = positional_encoding(50, 512) #512 - embedding dimension의 dimension
print (pos_encoding.shape)
plt.pcolormesh(pos_encoding[0], cmap='RdBu')
plt.xlabel('Depth')
plt.xlim((0, 512))
plt.ylabel('Position')
plt.colorbar()
plt.show()- Result: (1, 50, 512)
Transformer: Model Architecture
Transformer 모델의 전반적인 구조를 한번 보겠습니다.
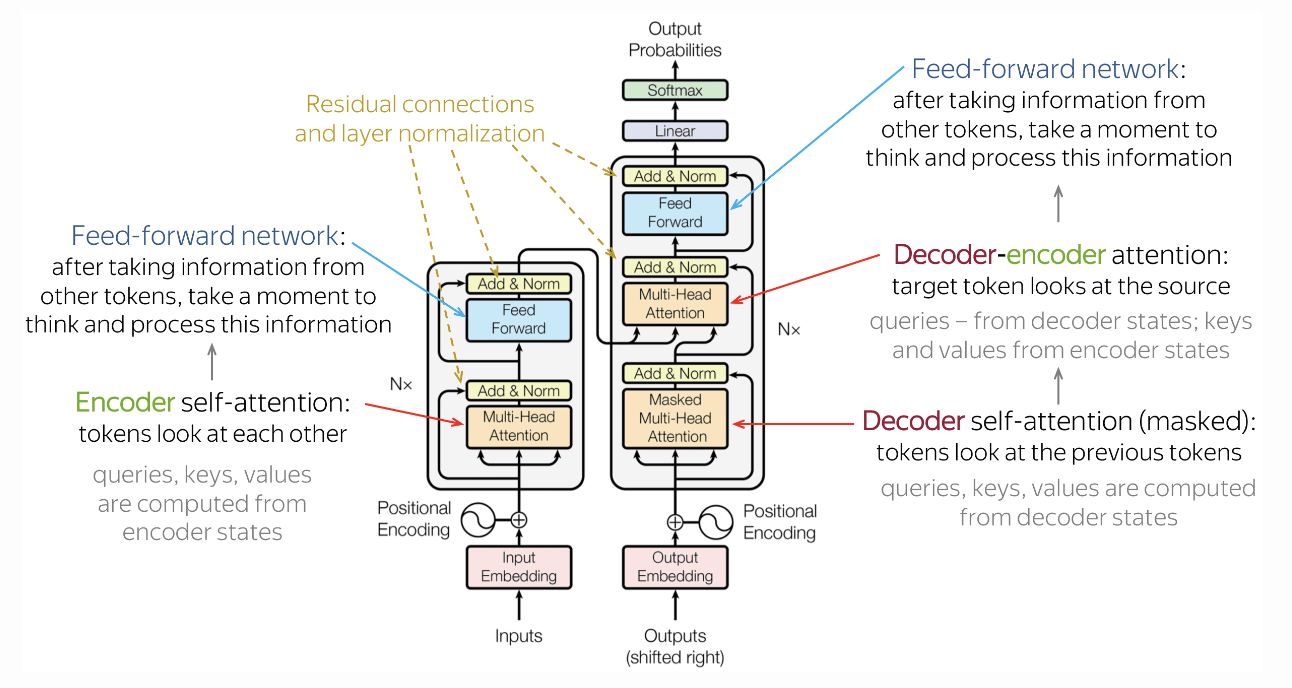
- 크게는 Encoder, Decoder 부분으로 구성이 되어 있으며, 세부적으로는 Feed-Forward Block, Residual Connection & Layer Normalization, Positional Encoding, Multi-Head Attention으로 구성되어 있습니다.
- 위에서 자세한 설명을 했으니까 여기서는 대략적인 설명만 하겠습니다.
Feed-forward Block
- 각 Layer에는 Feed-Forward Network Block이 있습니다. 2개의 Linear Layer(선형 레이어)사이에는 ReLU가 있습니다.
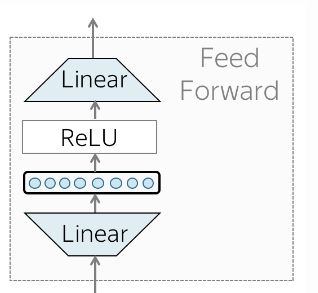
- Attention 매커니즘을 통해서 다른 Token을 살펴본 후 모델은 Feed-Forward Block을 사용하여 새로운 정보를 처리합니다.
Residual Connection (잔여 연결)
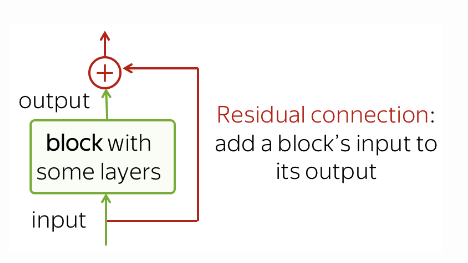
- Residual Connection은 매우 간단하면서 매우 유용합니다.
- Block의 Input(입력)을 Output(출력)에 추가 하는 구조입니다.
- Network를 통해서 Gradient Flow(흐름)을 완화하고 많은 Layer(레이어)를 쌓을 수 있습니다.
- Transformer에서는 각 Attention 및 Feed-Forward Block 후에 Residual Connection(잔여 연결)이 사용됩니다.
Layer Normalization (레이어 정규화)
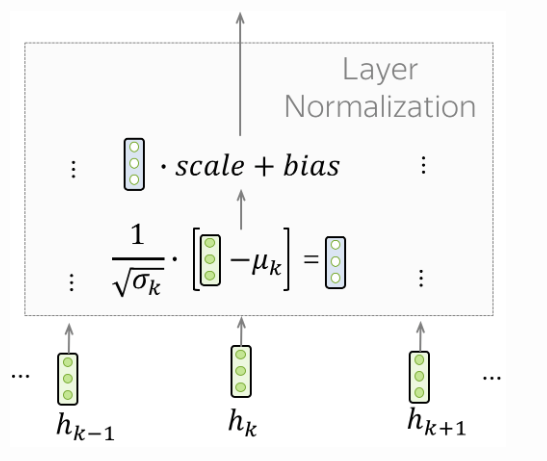
- "Add & Norm" Layer 의 "Norm" 부분은 Layer Normalization(레이어 정규화)를 나타냅니다.
- 각 예제의 Vector 표현을 독립적으로 정규화 합니다.
- 이는 다음 Layer로 "Flow"를 제어하기 위해 수행됩니다.
- Layer Normalization(레이어 정규화)는 안정성을 향상시키고 품질까지 향상시킵니다.
- Transformer에서는 각 Token의 Vector 표현을 Normalization(정규화)합니다.
- 또한 Layer Norm에는 훈련 가능한 매개변수인 'scale', 'bias' 그리고 Normalization(정규화)후에 Layer의 출력(or Next Layer의 Input)의 크기를 조정하는데 이용합니다.
Positional Encoding
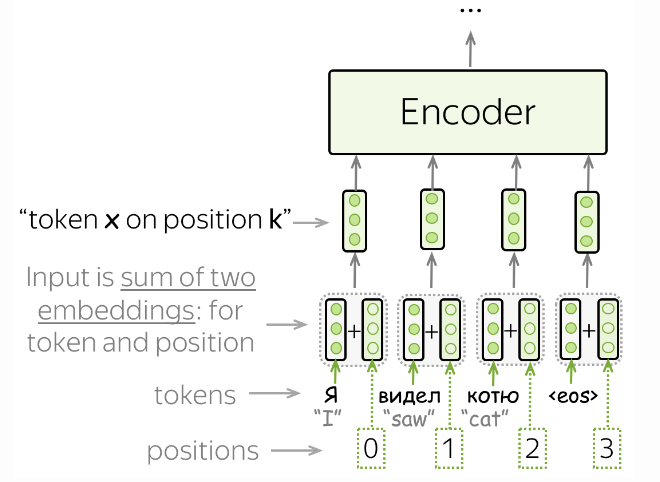
- Transformer Model은 Recurrence(반복) & Convolution이 포함되어 있지 않습니다
- 그러면 Input(입력)으로 들어오는 Token의 순서를 알 수 없습니다.
- 따라서 Model의 Token의 Position(위치)를 알려줘야 합니다.
- 이를 위해서는 두가지의 Embedding 세트가 있는데, Token, Position이 있습니다.
- 그리고 Token의 입력 표현 형태는 Token + Position(위치)의 Embedding의 합입니다.
Transformer Model Example Code
이 코드는 예제 코드입니다. 사용자에 맞춰서 수정을 해야 합니다.
Parameter
char2idx = prepro_configs['char2idx']
end_index = prepro_configs['end_symbol']
model_name = 'transformer'
vocab_size = prepro_configs['vocab_size']
BATCH_SIZE = 2
MAX_SEQUENCE = 25
EPOCHS = 30
VALID_SPLIT = 0.1
kargs = {'model_name': model_name,
'num_layers': 2,
'd_model': 512,
'num_heads': 8,
'dff': 2048,
'input_vocab_size': vocab_size,
'target_vocab_size': vocab_size,
'maximum_position_encoding': MAX_SEQUENCE,
'end_token_idx': char2idx[end_index],
'rate': 0.1
}Transformer Model Code
class Transformer(tf.keras.Model):
def __init__(self, **kargs):
super(Transformer, self).__init__(name=kargs['model_name'])
self.end_token_idx = kargs['end_token_idx']
self.encoder = Encoder(**kargs)
self.decoder = Decoder(**kargs)
self.final_layer = tf.keras.layers.Dense(kargs['target_vocab_size'])
def call(self, x):
inp, tar = x
enc_padding_mask, look_ahead_mask, dec_padding_mask = create_masks(inp, tar)
enc_output, attn = self.encoder(inp, enc_padding_mask) # (batch_size, inp_seq_len, d_model)
# dec_output.shape == (batch_size, tar_seq_len, d_model)
dec_output, attn = self.decoder(
tar, enc_output, look_ahead_mask, dec_padding_mask)
final_output = self.final_layer(dec_output) # (batch_size, tar_seq_len, target_vocab_size)
return final_output, attn
def inference(self, x):
inp = x
tar = tf.expand_dims([STD_INDEX], 0)
enc_padding_mask, look_ahead_mask, dec_padding_mask = create_masks(inp, tar)
enc_output = self.encoder(inp, enc_padding_mask)
predict_tokens = list()
for t in range(0, MAX_SEQUENCE):
dec_output, _ = self.decoder(tar, enc_output, look_ahead_mask, dec_padding_mask)
final_output = self.final_layer(dec_output)
outputs = tf.argmax(final_output, -1).numpy()
pred_token = outputs[0][-1]
if pred_token == self.end_token_idx:
break
predict_tokens.append(pred_token)
tar = tf.expand_dims([STD_INDEX] + predict_tokens, 0)
_, look_ahead_mask, dec_padding_mask = create_masks(inp, tar)
return predict_tokens'📝 NLP (자연어처리) > 📕 Natural Language Processing' 카테고리의 다른 글
| [NLP] 통계 기반 기법 개선하기 (0) | 2024.05.20 |
|---|---|
| [NLP] Thesaurus(시소러스), Co-occurence Matrix(동시발생 행렬) (0) | 2024.05.18 |
| [NLP] 합성곱, 순환신경망, Encoder, Decoder에서 수행하는 Self-Attention (0) | 2024.03.01 |
| [NLP] Attention - 어텐션 (0) | 2024.02.17 |
| [NLP] Word Embedding - 워드 임베딩 (0) | 2024.02.12 |