1. Attention
Attention은 CS 및 ML에서 중요한 개념중 하나로 여겨집니다. Attention의 매커니즘은 주로 Sequence Data를 처리하거나 생성하는 모델에서 사용됩니다. -> Sequence 입력을 수행하는 머신러닝 학습 방법의 일종
- Attention의 개념은 Decoder에서 출력을 예측하는 매시점(time step)마다, Encoder에서의 전체의 입력 문장을 다시 한번 참고하게 하는 기법입니다.
- 단, 전체 입력 문장을 전부 다 종일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야 할 요소와 연관이 있는 입력 요소 부분을 Attention(집중)해서 보게 합니다.
- 이 방법이 문맥을 파악하는 핵심의 방법이며, 이러한 방식을 DL(딥러닝)모델에 적용한것이 'Attention" 메커니즘입니다.
- 즉, 이말은 Task 수행에 큰 영향을 주는 Element(요소)에 Weight(가중치)를 크게 주고, 그렇지 않은 Weight(가중치)는 낮게 줍니다.
Attention이 등장한 이유?
- Attention 기법이 등장한 이유에 대해서 한번 알아보면 앞서 봤던 글중에 Seq2Seq Model에 대한 글이 있었습니다.
- 개념에 데하여 설명을 해보면, Seq2Seq는 Encoder에서 Input Sequence(입력 시퀀스)를 하나의 고정된 크기의 Vector로 압축합니다. 이를 Context Vector라고 하고, Decoder는 이 Context Vector를 활용해서 Output Sequence(출력 시퀀스)를 만듭니다.
- 근데, Seq2Seq 모델은 RNN 모델에 기반하고 있습니다. 그러면 문제가 발생하는데
- 하나는 Context Vector의 크기가 고정되어 있으므로 고정된 크기의 Vector에 Input으로 들어오는 정보를 압축하려고 하니까 정보손실이 발생할수도 있다는점.
- 다른 하나는 RNN이나 RNN기반 모델들의 고질적인 문제는 Gradient Vanishing(기울기 소실)문제가 존재하기 때문입니다.
- 그래서 Seq2Seq 모델은 Input Sequence(입력 시퀀스)가 길어지면 Output Sequence(출력 시퀀스)의 정확도가 떨어집니다.
- 그래서 정확도를 떨어지는것을 어느정도 방지해주기 위해서 등장한 방법이 Attention 입니다.
Seq2seq, Encoder, Decoder 개념을 정리해 놓은 글을 링크해 놓겠습니다. 참고해주세요!
[NLP] Seq2Seq, Encoder & Decoder
1..sequence-to-sequence 💡 트랜스포머(Transformer) 모델은 기계 번역(machine translation) 등 시퀀스-투-시퀀스(sequence-to-sequence) 과제를 수행하기 위한 모델입니다. sequence: 단어 같은 무언가의 나열을 의미합
daehyun-bigbread.tistory.com
2. Attention Function
- Attention 함수에 데하여 알아보겠습니다. Attention을 함수로 표현하면 다음과 같이 표현됩니다.
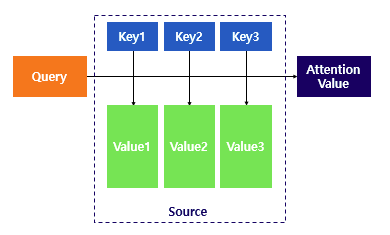
Attention(Q, K, V) = Attention Value
Q = Query : t 시점의 Decoder Cell 에서의 Hidden state(은닉 상태)
K = Keys : 모든 시점의 Encoder Cell 셀의 Hidden state(은닉 상태)들
V = Values : 모든 시점의 Encdoer Cell 셀의 Hidden state(은닉 상태)들- Attention function은 주어진 'Query(쿼리)'에 대해서 모든 'Key(키)'와의 유사도를 각각 구합니다. 그리고 구한 이 유사도를 키와 맵핑 되어있는 각각의 'Value(값)'에 반영합니다.
- 그리고 유사도가 반영된 'Value(값)'들을 더한후 Return합니다. 이 Return한 값은 'Attention Value(어텐션 값)'이라고 합니다. 한번 Attention의 예제들을 보겠습니다. Scaled Dot-Product Attention, Self-Attention, Multi-Head Attention3개를 한번 보겠습니다.
3. Dot-Product Attention
Attention의 종류가 있는데, 그 중의 하나인 Dot-Product Attention에 대해 알아보겠습니다.

- Decoder의 3번째 LSTM Cell에서 출력 단어를 예측할때, Attention 매커니즘을 사용합니다.
- 앞의 Decoder의 첫, 두번째 셀은 이미 Attention 매커니즘을 이용해서 단어를 예측하는 과정을 거쳤습니다.
- Decoder의 3번째 LSTM Cell은 출력 단어를 예측하기 위하여 Encoder의 모든 단어들의 정보를 참고하려고 합니다.
- Encoder의 Softmax 함수를 통해 나온 결과값은 I, am, a, student 단어 각각이 출력이 얼마나 도움이 되는지 정도를 수치화 한 값입니다.
- 여기서는 Softmax 함수위의 있는 직사각형의 크기가 클수록 결과값이 단어 각각의 출력에 도움이 되는 정도를 수치화 한 크기 입니다.
- 각 입력 단어가 Decoder 예측에 도움이 되는 정도를 수치화 하면 이를 하나의 정보로 합친후 Decoder로 보냅니다 (맨 위의 초록색 삼각형) -> 결론은 Decoder는 출력 단어를 더 정확하게 예측할 확률이 높아집니다. 구제적으로 설명해 보겠습니다.
1. Attention Score 구하기

- Encoder의 Time Step(Encoder의 시점)을 각각 1부터 N까지 라고 했을때 Hidden State(은닉 상태)를 각각 h1, h2, ~ hn이라고 하고, Decoder의 Time Step(현재 시점) t에서의 Decoder의 Hidden State(은닉 상태)를 st라고 합니다.
- 여기서는 Encoder의 Hidden State(은닉 상태), Decoder의 Hidden State(은닉 상태)의 차원이 같다고 가정해보겠습니다.
- 그러면 Encoder, Decoder의 Hidden state(은닉 상태)의 Dimension(차원)은 동일하게 4로 같습니다.
- Attention 메커니즘에서는 출력단어를 예측할때 Attention Value(어텐션 값)을 필요로 합니다. t번째 단어를 예측하기 위한 Decoder의 Cell은 2개의 input값을 필요로 하는데, 이전시점인 t-1의 은닉 상태와 이전 시점 t-1에 나온 출력 단어입니다.
- 그리고 Attention Value(어텐션 값)을 종합하여 Decoder Cell은 현재 시점(t)의 Output을 생성합니다.
+ Hidden state(은닉 상태): RNN(순환신경망), LSTM(장, 단기 메모리)에서 시간적 의존성을 학습 및 모델의 이전정보 유지에 사용되는 내부 상태입니다.
Input Sequence를 한번에 하나씩 처리하면서 내부 상태를 업데이트 하는데, 이때 현재 시점의 input 및 이전시점의 hidden state(은닉 상태)에 영향을 받으며, 이전정보 유지 및 현재 입력에 따라 변화합니다.
한번 현재 시점의 단어인 t번째 단어를 예측하기 위한 Attention 값을 'at'라고 정의해보겠습니다.
- 현재 시점의 단어인 t번째 단어를 예측하기 위한 Attention 값인 'at' 값을 구하려면 Attention Score(어텐션 스코어)를 구해야 합니다.
- 여기서 Attention Score(어텐션 스코어)는 현재 Decoder의 시점 t에서 단어를 예측하기 위해서 Encoder의 모든 Hidden state(은닉 상태) 각각이 Decoder의 현시점의 Hidden state(은닉 상태)값인 'st'와 얼마나 유사한지를 판단하는 값입니다.
- Dot-Product Attention에서는 Score값을 구하기 위하여 Decoder의 현시점의 Hidden state(은닉 상태)값인 'St'를 Transpose(전치)하고 각 Hidden state(은닉 상태)와 Dot Product(내적)을 수행합니다.
- 예를 들어서 'St'와 Encoder의 i번째 Hidden state의 Attention Score의 계산 방법은 아래의 그림과 같습니다.
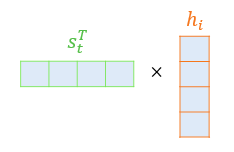
- Attention Score Function(어텐션 스코어 함수)를 정의해보면 아래 왼쪽의 수식과 같습니다.
- 그리고 Decoder의 현시점의 Hidden state(은닉 상태)값인 'st'와 Encoder의 모든 Hidden State(은닉 상태)의 Attention Score의 모음값을 'et'라고하고, 'et'의 수식은 아래의 오른쪽 수식과 같습니다.
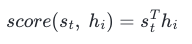

2. Attention Distribution(어텐션 분포) 구하기 by Softmax 함수
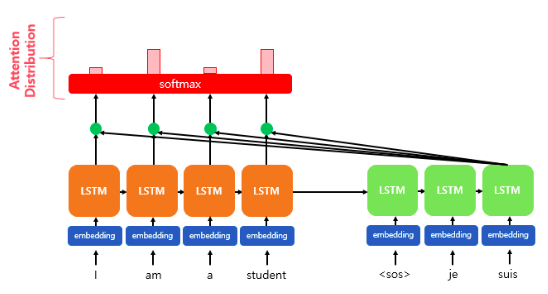
- 'et'에 Softmax Function(Softmax 함수)를 적용하여, 모든 값을 합치면 1이 되는 확률 분포를 얻어냅니다.
- 이를 Attention Distribution(어텐션 분포)라고 하며, 각각의 값은 Attention Weight(어텐션 가중치)라고 합니다.
- 예를 들어서 Softmax Function(Softmax 함수)를 적용하여 얻은 출력값들의 Attention 가중치들의 합은 1입니다.
- 이 그림에서는 각 Encoder의 Hidden State(은닉 상태)에서의 Attention Weight(어텐션 가중치)의 크기를 직사각형의 크기로 시각화 하여, Attention Weight(어텐션 가중치)가 클수록 직사각형이 큽니다.
- Decoder의 시점인 't'에서 Attention Weight(어텐션 가중치)의 모음값인 Attention Distribution(어텐션 분포)를 'at'라고 할 때, 'at'를 식으로 정의하면 아래의 식과 같습니다.

3. 각 Encoder의 Attention 가중치 & Hidden state를 합쳐 어텐션 값 구하기

- Attention의 최종 결과 값을 얻기 위해서는 각 Encoder의 Hidden state(은닉상태), Attention Weight(어텐션 가중치)값들을 곱하고, 모두 더합니다.
- 이러한 과정을 Weight Sum(가중합)이라고 하며, 아래의 식은 Attention의 최종결과인 Attention Value(어텐션 값)에 대한 식을 보여줍니다.
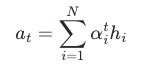
- 이 Attention Value(어텐션 값) 'at'는 종종 Encoder의 문맥을 포함하며, Context Vector(컨텍스트 벡터)라고도 합니다.
- Seq2seq의 Encoder의 마지막 Hidden state(은닉상태)를 Context Vector(컨텍스트 벡터)로 부르는것과 다릅니다.
4. Attention Value & Decoder의 t시점의 Hidden state를 연결 (Attention 매커니즘의 핵심)
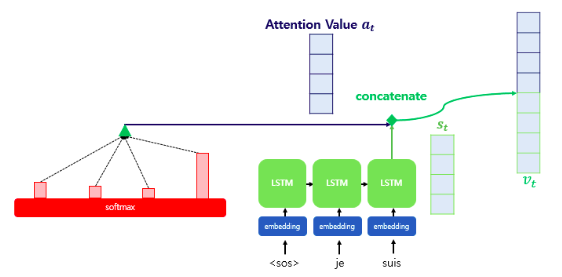
- Attention Value(어텐션 값)'at'가 구해지면 Attention 메커니즘은 'at'를 'st'와 합쳐서(Concentrate) 하나의 Vector로 만듭니다.
- 이 작업의 결과를 'vt'라고 정의하고, 이 'vt'를 y^ 예측 연산의 input으로 사용하여 Encoder에서 얻은 정보를 활용하여 y^를 더 정확하게 예측하는데 도움을 줍니다.
5. Output Layer 연산의 입력값 계산 및 입력으로 사용하기

- 'vt'를 바로 Output Layer(출력층)으로 보내기 전에 출력층 연산을 하는 과정입니다.
- Weight(가중치) 행렬에 곱하고, tanh(하이퍼볼릭탄젠트) 함수를 지나도록 해서 Output Layer 연산을 하기 위한 Vector인 'st'를 얻습니다.
- Seq2seq는 Output Layer(출력층)의 Input(입력)이 t시점의 Hidden State(은닉 상태)인 'st'였지만, Attention 매커니즘 에서는 Output Layer(출력층)의 Input(입력)이 'st'가 됩니다.
- 식으로는 아래의 식과 같습니다. 'Wc'는 학습 가능한 Weight(가중치) 행렬, 'bc'는 bias(편향)입니다.
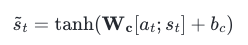
- 'st'를 Output Layer(출력층)의 Input(입력)으로 사용하여 Predict Vector(예측 벡터)를 얻습니다.
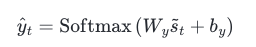
Dot-Product Attention Model Example Code
TF(Tensorflow)로 구현한 코드입니다.
import tensorflow as tf
def scaled_dot_product_attention(q, k, v, mask):
# Query와 Key 간의 dot product 계산
matmul_qk = tf.matmul(q, k, transpose_b=True) # (..., seq_len_q, seq_len_k)
# dot product를 정규화하기 위해 스케일링
dk = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
# 만약 mask가 제공되었다면, 유효한 부분에 대해서만 -1e9로 마스킹
if mask is not None:
scaled_attention_logits += (mask * -1e9)
# 어텐션 가중치 계산 (소프트맥스 함수 적용)
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1) # (..., seq_len_q, seq_len_k)
# 어텐션 가중 평균을 사용하여 값을 계산
output = tf.matmul(attention_weights, v) # (..., seq_len_q, depth_v)
return output, attention_weights
- 이 코드는 Dot-Product Attention을 구현한 코드입니다.
- 순서는 주어진 Query(쿼리, 'q'), Key(키, 'k') 간의 Product를 Key행렬을 전치하여 Dot Product를 계산합니다.
- Dot Product를 Key의 차원수로 나눠주어 정규화 합니다.
- Scaling을 통해 Gradient Vanishing / Exploding (기울기 손실, 폭팔)을 방지합니다.
- Masking은 유효한 부분에만 'Attention'을 적용합니다. -> 선택적으로 어텐션 마스크를 적용하며, 유효하지 않은 부분에는 -1e9를 더하여 마스킹 합니다.
- Softmax 함수를 적용하여 Attention Weight(어텐션 가중치)를 계산합니다. 여기서 Weight(가중치)는 Query(쿼리), Key(키)간의 중요성을 나타냅니다.
- Attention Weight(가중치)를 사용하여 Value(밸류)행렬과 평균값을 계산하고 'output'을 출력합니다.
- 'output'은 Query에 대한 Attention 가중 평균 값입니다. 그리고 'output'과 Attention Weight(가중치)를 반환합니다.
4. Self-Attention
Self-Attention 기법은 Attention 기법을 말 그대로 자기 자신에게 수행하는 Attention 기법입니다.
- Input Sequence 내의 각 요소간의 상대적인 중요도를 계산하는 매커니즘이며, Sequence의 다양한 위치간의 서로 다른 관계를 학습할 수 있습니다.
- Sequence 요소 가운데 Task 수행에 중요한 Element(요소)에 집중하고 그렇지 않은 Element(요소)는 무시합니다.
- 이러면 Task가 수행하는 성능이 상승할 뿐더러 Decoding 할때 Source Sequence 가운데 중요한 Element(요소)들만 추립니다.
- 문맥에 따라 집중할 단어를 결정하는 방식을 의미 -> 중요한 단어에만 집중을 하고 나머지는 그냥 읽습니다.
- 이 방법이 문맥을 파악하는 핵심이며, 이러한 방식을 Deep Learning 모델에 적용한것이 'Attention' 매커니즘이며, 이 매커니즘을 자기 자신에게 적용한것이 'Self-Attention' 입니다. 한번 매커니즘을 예시를 들어서 설명해 보겠습니다.
Self-Attention의 계산 예시
Self-Attention은 Query(쿼리), Key(키), Value(밸류) 3가지 요소가 서로 영향을 주고 받는 구조입니다.
- 문장내 각 단어가 Vector(벡터) 형태로 input(입력)을 받습니다.
* Vector: 숫자의 나열 정도
- 각 단어의 Vector는 3가지 과정을 거쳐서 반환이 됩니다.
- Query(쿼리) - 내가 찾고 정보를 요청하는것 입니다.
- Key(키) - 내가 찾는 정보가 있는 찾아보는 과정입니다.
- Value(밸류) - 찾아서 제공된 정보가 가치 있는지 판단하는 과정입니다.

- 위의 그림을 보면 입력되는 문장 "어제 카페 갔었어 거기 사람 많더라" 이 6개 단어로 구성되어 있다면?
- 여기서의 Self-Attention 계산 대상은 Query(쿼리) Vector 6개, Key(키) Vector 6개, Value(밸류) Vector 6개등 모두 18개가 됩니다.

- 위의 표는 더 세부적으로 나타낸것입니다. Self-Attention은 Query 단어 각각에 대해 모든 Key 단어와 얼마나 유기적인 관계를 맺고 있는지의 확률값들의 합이 1인 확률값으로 나타냅니다.
- 이것을 보면 Self-Attention 모듈은 Value(밸류) Vector들을 Weighted Sum(가중합)하는 방식으로 계산을 마무리 합니다.
- 확률값이 가장 높은 키 단어가 쿼리 단어와 가장 관련이 높은 단어라고 할 수 있습니다.

- 여기서는 '카페'에 대해서만 계산 예시를 들었지만, 이러한 방식으로 나머지 단어들오 Self-Attention을 각각 수행합니다.
Self-Attention의 동작 방식
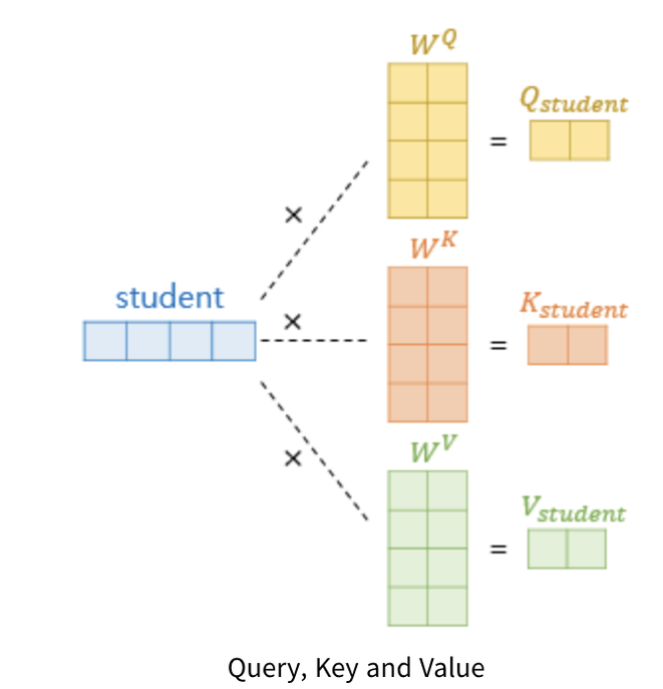
Self-Attention에서 가장 중요한 개념은 Query(쿼리), Key(키), Value(밸류)의 시작값이 동일하다는 점입니다.
- 그렇다고 Query(쿼리), Key(키), Value(밸류)가 동일 하다는 말이 이닙니다.
- 그림을 보면 가중치 Weight W값에 의해서 최종적인 Query(쿼리), Key(키), Value(밸류)값은 서로 달라집니다.

Attention을 구하는 공식을 보겠습니다.
- 일단 Query(쿼리)랑 Key(키)를 내적해줍니다. 이렇게 내적을 해주는 이유는 둘 사이의 연관성을 계산하기 위해서입니다.
- 이 내적된 값을 "Attention Score"라고 합니다. Dot-Product Attention 부분에서 자세히 설명 했지만 이번에는 간단하게 설명해 보겠습니다.
- 만약, Query(쿼리)랑 Key(키)의 Dimension(차원)이 커지면, 내적 값의 Attention Score가 커지게 되어서 모델이 학습하는데 어려움이 생깁니다.
- 이 문제를 해결하기 위해서 차원 d_k의 루트만큼 나누어주는 Scaling 작업을 진행합니다. 이과정을 "Scaled Dot-Product Attention" 이라고 합니다.
- 그리고 Scaled Dot-Product Attention"을 진행한 값을 정규화를 진행해주기 위해서 Softmax 함수를 거쳐서 보정을 위해 계산된 score행렬, value행렬을 내적합니다. 그러면 최종적으로 Attention 행렬을 얻을 수 있게 됩니다. 예시 문장을 들어서 설명해 보겠습니다.
"I am a student"라는 문장으로 예시를 들어보겠습니다.

- Self-Attention은 Query(쿼리), Key(키), Value(밸류) 3개 요소 사이의 문맥적 관계성을 추출합니다.
Q = X * Wq, K = X * Wk, W = X * Wv
- 위의 수식처럼 Input Vector Sequence(입력 벡터 시퀀스) X에 Query(쿼리), Key(키), Value(밸류)를 만들어주는 행렬(W)를 각각 곱해줍니다.
- Input Vector Sequence(입력 벡터 시퀀스)가 4개이면 왼쪽에 있는 행렬을 적용하면 Query(쿼리), Key(키), Value(밸류) 각각 4개씩, 총 12개가 나옵니다.
* Word Embedding: 단어를 Vector로 변환해서 Dense(밀집)한 Vector공간에 Mapping 하여 실수 Vector로 표현합니다.
- 각 단어에 데하여 Word Embedding(단어 임베딩)을 합니다. 단어 'i'의 Embedding이 [1,1,1,1]이라고 했을 때, 처음 'i'의 처음 Query(쿼리), Key(키), Value(밸류)를 각각 'Q_i, original', 'K_i, original', 'V_i, original', 라고 합니다.
- Embedding의 값이 다 [1,1,1,1]로 같은 이유는 Self-Attention 매커니즘에서는 같아야 하기 때문에 모두 [1,1,1,1]이라고 동일합니다.
- 학습된 Weight(가중치)값이 'WQ', 'WK', 'WV'라고 할때 Original 값들과 점곱을 해주면 최종적으로 'Q', 'K', 'V'값이 도출됩니다.
- 'Q', 'K', 'V'값을 이용해서 위에서 설정한 보정된 'Attention Score'를 곱해주면 아래의 왼쪽식과 같이 1.5라는 값이 나옵니다.
- 행렬 'Q', 'K'는 서로 점곱 계산해주고, 여기서 행렬 'Q', 'K', 'V'의 Dimension(차원)은 4이므로 루트 4로 나누어줍니다.
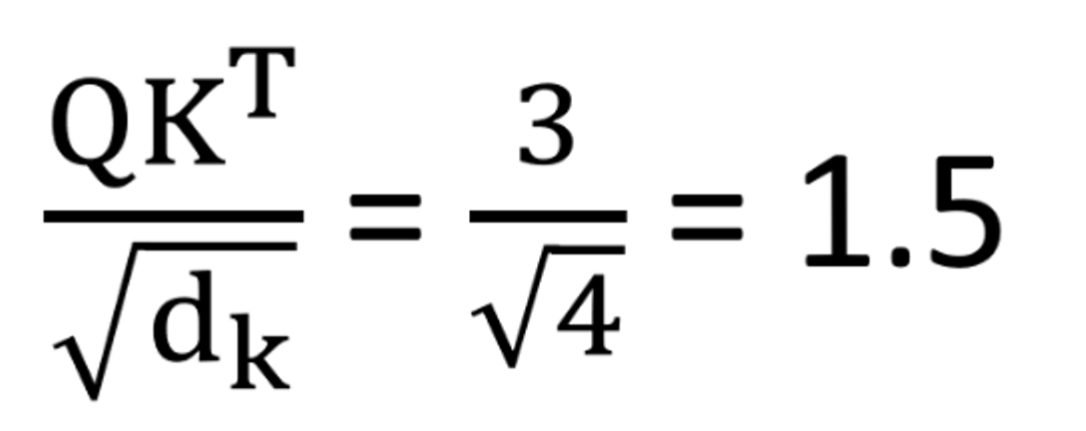
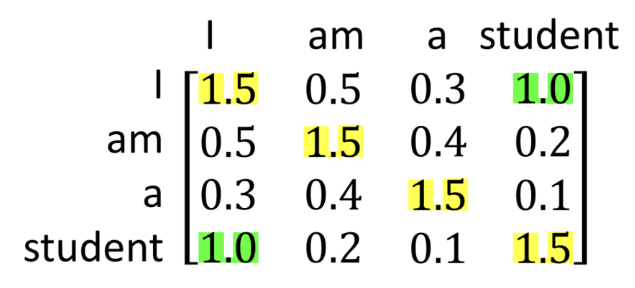
- 'i' 뿐만 아니라 모든 단어간의 'Self-Attention'을 해주면 위의 오른쪽 행렬과 같은 결과가 나옵니다.
- 가운데 노락색 부분은 자기 자신에 대한 'Attention'이므로 당연히 값이 제일 크고, 양쪽 초록색 부분을 보면 점수가 높습니다.

- 위의 그림은 단어 하나하나의 'Attention'을 구하는 과정을 도식화 한 그림입니다.
- 실제로는 여러 단어를 위의 그림과 같이 병렬 처리를 해서 계산을 합니다.
- 병렬처리를 하면 연산속도가 빨리지는 이점이 있기 때문입니다. 간단히 'Self-Attention' 과정을 요약해서 설명해보겠습니다.
Self-Attention 과정 Summary
1. 원하는 문장을 임베딩하고 학습을 통해 각 Query, Key, Value에 맞는 weight들을 구해줌.
2. 각 단어의 임베딩의 Query, Key, Value(Query = Key = Value)와 weight를 점곱(내적)해 최종 Q, K, V를 구함.
3. Attention score 공식을 통해 각 단어별 Self Attention value를 도출
4. Self Attention value의 내부를 비교하면서 상관관계가 높은 단어들을 도출
Self-Attention Example Code
PyTorch 라이브러리를 불러와서 한번 예제 코드를 돌려보겠습니다.
import torch1. 변수정의
- PyTorch 라이브러리를 활용해서 코드로 보겠습니다. 우선 Input Vector Sequence X와 Query(쿼리), Key(키), Value(밸류)구축에 필요한 행렬들을 정의합니다.
x = torch.tensor([
[1.0, 0.0, 1.0, 0.0],
[0.0, 2.0, 0.0, 2.0],
[1.0, 1.0, 1.0, 1.0],
])
w_query = torch.tensor([
[1.0, 0.0, 1.0],
[1.0, 0.0, 0.0],
[0.0, 0.0, 1.0],
[0.0, 1.0, 1.0]
])
w_key = torch.tensor([
[0.0, 0.0, 1.0],
[1.0, 1.0, 0.0],
[0.0, 1.0, 0.0],
[1.0, 1.0, 0.0]
])
w_value = torch.tensor([
[0.0, 2.0, 0.0],
[0.0, 3.0, 0.0],
[1.0, 0.0, 3.0],
[1.0, 1.0, 0.0]
])2. Query(쿼리), Key(키), Value(밸류) 만들기
- Vector Sequence로 Query(쿼리), Key(키), Value(밸류)를 만듭니다.
- 여기서 torch.matmul은 행렬곱을 수행하는 함수입니다.
keys = torch.matmul(x, w_key)
querys = torch.matmul(x, w_query)
values = torch.matmul(x, w_value)3. Attention Score 만들기
- 위에서 만든 Query(쿼리), Key(키) Vector들을 행렬곱해서 Attention Score를 만드는 과정입니다.
- 여기서 keys.T는 Key(키) Vector들을 Transpose(전치)한 행렬입니다.
attn_scores = torch.matmul(querys, keys.T)
attn_scorestensor([[ 2., 4., 4.],
[ 4., 16., 12.],
[ 4., 12., 10.]])4. Softmax 확률값 만들기
- Key(키) Vector의 차우너수의 제곱근으로 나눠준뒤 Softmax를 취하는 과정입니다.
import numpy as np
from torch.nn.functional import softmax
key_dim_sqrt = np.sqrt(keys.shape[-1])
attn_scores_softmax = softmax(attn_scores / key_dim_sqrt, dim=-1)- keys는 Attention 메커니즘에서 사용되는 키(key) 값들을 나타내는 Tensor입니다.
- keys.shape[-1]는 keys Tensor의 마지막 Dimension(차원)의 크기, 즉 키의 차원(dimension) 수를 나타냅니다.
- key_dim_sqrt는 키 차원의 제곱근에 대한 값으로, 어텐션 스코어를 정규화하는 데 사용됩니다.
- 정규화는 어텐션 스코어를 키 차원의 제곱근으로 나누어주는 과정입니다.
- 이렇게 함으로써 어텐션의 크기에 따라 정규화가 이루어지며, 수렴을 도모하고 안정성을 제공합니다.
attn_scores_softmaxtensor([[1.3613e-01, 4.3194e-01, 4.3194e-01],
[8.9045e-04, 9.0884e-01, 9.0267e-02],
[7.4449e-03, 7.5471e-01, 2.3785e-01]])5. Softmax 확률, Value를 가중합하기
- Softmax 확률과 Value Vector들을 가중합 하는 과정입니다.
- Self-Attention의 학습 대상은 Query(쿼리), Key(키) Value(밸류)를 만드는 Weight(가중치) 행렬입니다.
- 코드에서는 'w_query', 'w_key', 'w_value' 입니다.
- 이들은 Task(예: 기계번역)를 가장 잘 수행하는 방향으로 학습 과정에서 업데이트 됩니다.
weighted_values = torch.matmul(attn_scores_softmax, values)
weighted_valuestensor([[1.8639, 6.3194, 1.7042],
[1.9991, 7.8141, 0.2735],
[1.9926, 7.4796, 0.7359]])Self-Attention Model Example Code
PyTorch를 사용하여 Self-Attention으로 구현하였습니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size # 임베딩 차원
self.heads = heads # 헤드 수
self.head_dim = embed_size // heads # 헤드 당 임베딩 차원
assert (
self.head_dim * heads == embed_size
),
# 값, 키, 쿼리를 위한 선형 레이어
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
# 어텐션 이후 최종 출력을 위한 선형 레이어
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query, mask):
# 훈련 예제 수 확인
N = query.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
# 임베딩을 헤드 당 다른 부분으로 나누기
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = query.reshape(N, query_len, self.heads, self.head_dim)
# 값, 키, 쿼리에 대한 선형 프로젝션
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
# 에너지(어텐션 스코어) 계산을 위해 Einsum 사용
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
# 마스크 적용 여부 확인
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
# 소프트맥스를 적용하여 어텐션 스코어 정규화
attention = torch.nn.functional.softmax(energy / (self.embed_size ** (1 / 2)), dim=3)
# 어텐션 스코어를 사용하여 값의 가중 평균 계산
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
# 최종 출력을 위한 선형 레이어 적용
out = self.fc_out(out)
return out
- 이 코드는 Self-Attention 모델을 구현한 코드입니다.
- 순서는 각각의 Query, Key, Value에 대해 선형 레이어를 통해 적절한 차원으로 매핑합니다.
- 각 Head에 대한 부분으로 Embedding을 나누어서 관리합니다.
- Attention Score 계산을 위해서 Einsum을 사용합니다. - Query(쿼리), Key(키)간의 Attention Score 계산.
- 선택적으로 적용된 'Attention Score'를 사용하여 유효하지 않은 부분에 masking 합니다.
- Attention Score를 Softmax 함수를 사용하여 정규화하고, Value(밸류)이 가중 평균을 계산합니다.
- 그리고 계산된 결과에 대해서 선형 레이어를 적용하여 최종 출력을 얻어서 반환합니다.
5. Multi-Head Attention
Multi-Head Attention은 여러개의 'Attention Head'를 가지고 있습니다. 여기서 각 'Head Attention'에서 나온 값을 연결해 사용하는 방식입니다.
- 한번의 'Attention'을 이용하여 학습을 시키는것 보다는 'Attention'을 병렬로 여러개 사용하는 방식입니다.
- 순서는 원래의 Query(쿼리), Key(키) Value(밸류) 행렬 값을 Head수 만큼 분할합니다.
- 분할한 행렬 값을 통해, 각 'Attention' Value값들을 도출합니다.
- 도출된 'Attention value'값들을 concatenate(쌓아 합치기)하여서 최종 'Attention Value'를 도출합니다.
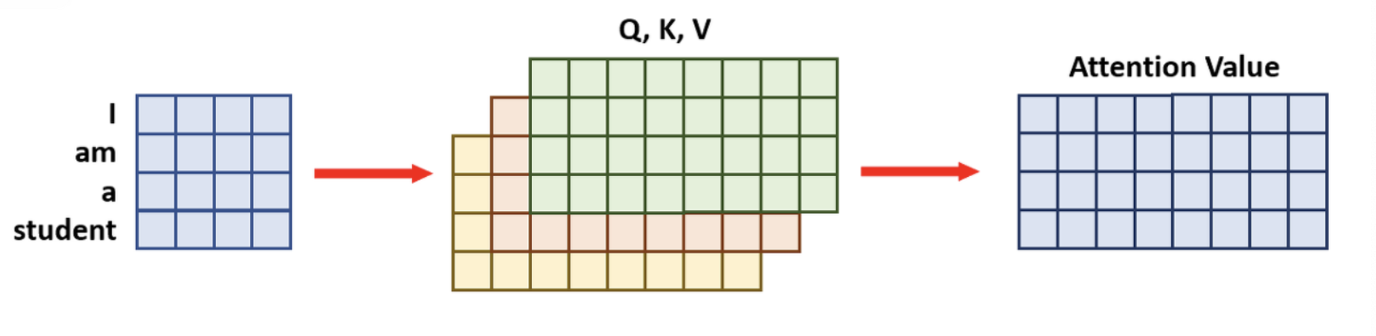
- [4x4] 크기의 문장 Embedding Vector와 [4x8]의 Query(쿼리), Key(키) Value(밸류)가 있을 때, 일반적인 한 번에 계산하는 Attention 메커니즘은 [4x4]*[4x8]=[4x8]의 'Attention Value'가 한 번에 도출됩니다.
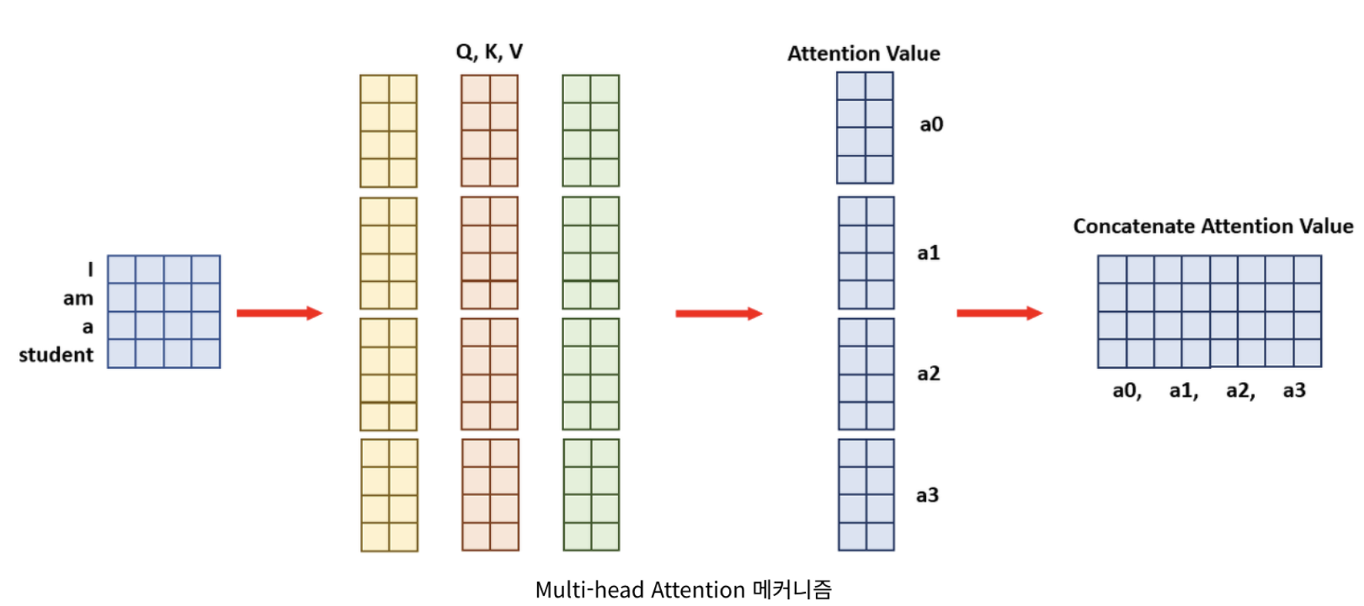
- 'Multi-Head Attention' 매커니즘으로 보면 여기서 Head는 4개 입니다. 'I, am, a, student'
- Head가 4개 이므로 각 연산과정이 1/4만큼 필요합니다.
- 위의 그림으로 보면 크기가 [4x8]이었던, Query(쿼리), Key(키) Value(밸류)를 4등분 하여 [4x2]로 만듭니다. 그러면 여기서의 'Attention Value'는 [4x2]가 됩니다.
- 이 'Attention Value'들을 마지막으로 Concatenate(합쳐준다)합쳐주면, 크기가 [4x8]가 되어 일반적인 Attention 매커니즘의 결과값과 동일하게 됩니다. 예시를 한번 들어보겠습니다.
Summary: Query(쿼리), Key(키), Value(밸류)값을 한 번에 계산하지 않고 head 수만큼 나눠 계산 후 나중에 Attention Value들을 합치는 메커니즘. 한마디로 분할 계산 후 합산하는 방식.
Multi-Head Attention Example

- 입력 단어 수는 2개, 밸류의 차원수는 3, 헤드는 8개인 멀티-헤드 어텐션을 나타낸 그림 입니다.
- 개별 헤드의 셀프 어텐션 수행 결과는 ‘입력 단어 수 ×, 밸류 차원수’, 즉 2×3 크기를 갖는 행렬입니다.
- 8개 헤드의 셀프 어텐션 수행 결과를 다음 그림의 ①처럼 이어 붙이면 2×24 의 행렬이 됩니다.
- Multi-Head Attention의 최종 수행 결과는 '입력 단어 수' x '목표 차원 수' 이며, Encoder, Decoder Block 모두에 적용됩니다.
Multi-Head Attention은 개별 Head의 Self-Attention 수행 결과를 이어 붙인 행렬 (①)에 W0를 행렬곱해서 마무리 된다.
→ 셀프 어텐션 수행 결과 행렬의 열(column)의 수 × 목표 차원수
Multi-Head Attention Model Example Code
Multi-Head Attention Model 예제 코드입니다. TF(Tensorflow)로 구현했습니다.
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, **kargs):
super(MultiHeadAttention, self).__init__()
self.num_heads = kargs['num_heads']
self.d_model = kargs['d_model']
assert self.d_model % self.num_heads == 0
self.depth = self.d_model // self.num_heads
# Query, Key, Value에 대한 가중치 행렬 초기화
self.wq = tf.keras.layers.Dense(kargs['d_model']) # Query에 대한 가중치
self.wk = tf.keras.layers.Dense(kargs['d_model']) # Key에 대한 가중치
self.wv = tf.keras.layers.Dense(kargs['d_model']) # Value에 대한 가중치
# 최종 출력을 위한 가중치 행렬 초기화
self.dense = tf.keras.layers.Dense(kargs['d_model'])
def split_heads(self, x, batch_size):
# 마지막 차원을 (num_heads, depth)로 나누고 결과를 (batch_size, num_heads, seq_len, depth)로 변환
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, v, k, q, mask):
batch_size = tf.shape(q)[0]
# Query, Key, Value에 대한 가중치 행렬 적용
q = self.wq(q) # Query에 대한 가중치 적용
k = self.wk(k) # Key에 대한 가중치 적용
v = self.wv(v) # Value에 대한 가중치 적용
# 각 헤드로 임베딩을 나누기
q = self.split_heads(q, batch_size) # (batch_size, num_heads, seq_len_q, depth)
k = self.split_heads(k, batch_size) # (batch_size, num_heads, seq_len_k, depth)
v = self.split_heads(v, batch_size) # (batch_size, num_heads, seq_len_v, depth)
# Scaled Dot-Product Attention 수행
# scaled_attention.shape == (batch_size, num_heads, seq_len_q, depth)
# attention_weights.shape == (batch_size, num_heads, seq_len_q, seq_len_k)
scaled_attention, attention_weights = scaled_dot_product_attention(
q, k, v, mask)
# 어텐션 헤드를 다시 합치고 최종 출력으로 변환
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3]) # (batch_size, seq_len_q, num_heads, depth)
concat_attention = tf.reshape(scaled_attention,
(batch_size, -1, self.d_model)) # (batch_size, seq_len_q, d_model)
# 최종 출력 계산
output = self.dense(concat_attention) # (batch_size, seq_len_q, d_model)
return output, attention_weights- 이 코드는 Multi-Head Attention Model을 구현한 코드입니다.
- 클래스를 초기화하면서 필요한 파라미터들을 설정하고, 각각의 Query, Key, Value, 최종 출력에 사용될 가중치들을 정의합니다.
- 입력 텐서의 마지막 차원을 여러 Heads로 나누고, 결과를 적절하게 변환하여 Heads의 차원을 앞으로 가져옵니다.
- Query, Key, Value에 각각의 가중치를 적용하고, Heads로 분할합니다.
- Scaled Dot-Product Attention을 호출하고, 결과를 처리합니다.
- 최종 출력을 계산하고 반환합니다.
- Ps. 이렇게 Attention에 데해서 설명한 글을 썼는데, 내용도 더 쓸게 있지만 너무 길어질거 같아서 여기까지만 쓰고 다음 글로 넘기겠습니다.
- 다음글에는 합성곱, 순환 신경망이랑 비교한거랑, Encoder, Decoder에서 수행하는 Self-Attention에 데하여 알아보겠습니다.
'📝 NLP (자연어처리) > 📕 Natural Language Processing' 카테고리의 다른 글
| [NLP] Transformer Model - 트랜스포머 모델 알아보기 (0) | 2024.03.07 |
|---|---|
| [NLP] 합성곱, 순환신경망, Encoder, Decoder에서 수행하는 Self-Attention (0) | 2024.03.01 |
| [NLP] Word Embedding - 워드 임베딩 (0) | 2024.02.12 |
| [NLP] Word2Vec, CBOW, Skip-Gram - 개념 & Model (0) | 2024.02.03 |
| [NLP] GRU Model - LSTM Model을 가볍게 만든 모델 (0) | 2024.01.30 |