
반응형
Data Preprocessing (데이터 전처리) 개요
데이터 전처리란?
데이터 전처리는 원시 데이터를 분석 및 모델링에 적합하게 변환하는 과정을 의미합니다.
- 이는 데이터의 정제, 변환, 통합 등을 포함하며, 데이터 품질을 높여 신뢰성 있는 분석을 가능하게 합니다.
데이터 전처리의 중요성 및 필요성
데이터 전처리는 다음과 같은 이유로 매우 중요합니다.
- 데이터 품질 향상: 정확하고 일관된 데이터를 확보하여 분석의 기초를 튼튼히 합니다.
- 모델 성능 최적화: 적절히 전처리된 데이터는 모델의 성능을 향상시키고, 예측 정확도를 높입니다.
- 분석의 신뢰성 향상: 깨끗한 데이터를 사용함으로써 분석 결과의 신뢰성을 높입니다.
- 데이터 활용의 효율성 향상: 데이터 전처리를 통해 분석 작업이 더 효율적으로 수행될 수 있습니다.
데이터 전처리의 주요 단계
- 데이터 정제
- 결측값 처리: 데이터셋 내 누락된 값을 처리합니다. 예를 들어, 평균값으로 대체하거나 해당 데이터를 제거합니다.
- 이상값 탐지 및 수정: 데이터셋에서 비정상적으로 벗어난 값을 찾아내고 수정합니다.
- 중복 데이터 제거: 데이터셋에서 중복된 데이터를 식별하고 제거합니다.
- 데이터 변환
- 데이터 스케일링: 데이터의 범위를 조정하여 모델이 더 잘 학습할 수 있도록 합니다. 예를 들어, 정규화(normalization)나 표준화(standardization)를 적용합니다.
- 데이터 인코딩: 범주형 데이터를 수치형 데이터로 변환합니다. 예를 들어, 원-핫 인코딩(one-hot encoding)을 사용합니다.
- 데이터 통합 및 변형
- 데이터 병합: 여러 데이터셋을 하나로 결합합니다. 예를 들어, 데이터베이스 테이블을 조인(join)합니다.
- 데이터 집계 및 변형: 데이터를 요약하고 변형하여 분석에 적합한 형태로 만듭니다. 예를 들어, 그룹화(grouping)하고 집계(aggregation) 연산을 수행합니다.
데이터 수집 후 전처리 과정
데이터 수집에서 전처리로의 연결
데이터 분석의 첫 번째 단계는 다양한 소스에서 데이터를 수집하는 것입니다.
데이터를 수집하는 방법에는 여러 가지가 있으며, 대표적으로 OpenAPI, 웹 크롤링 등이 있습니다.
- OpenAPI: 누구나 접근할 수 있도록 개방된 API를 통해 데이터를 수집합니다.
- 웹 크롤링: 자동화된 스크립트를 사용하여 웹 페이지를 탐색하고 데이터를 수집합니다.
수집된 데이터의 정제 필요성
수집된 데이터는 대부분 정제가 필요합니다. 이유는 무엇일까요?
- 데이터는 활용을 목적으로 수집 계획을 짠 경우가 거의 없음: 데이터는 종종 다양한 출처에서 수집되며, 이 과정에서 데이터의 형식, 구조, 품질이 일관되지 않을 수 있습니다.
- 데이터 수집이 먼저이고, 수집된 데이터를 어떻게 하면 잘 활용할 수 있을까는 나중에 고려: 수집된 데이터는 원시 상태로 존재하며, 이를 분석 및 모델링에 적합하게 변환하는 과정이 필요합니다.
수집된 데이터의 초기 확인 및 분석
데이터를 수집한 후에는 이를 분석 및 모델링에 적합하게 만들기 위해 초기 확인 및 전처리 과정을 거쳐야 합니다.
- 데이터 불러오기
- 수집된 데이터를 분석 환경으로 불러옵니다. 예를 들어, CSV 파일, 데이터베이스, API 응답 등을 불러올 수 있습니다.
- 기본 정보 확인
- 데이터 구조: 데이터가 어떻게 구성되어 있는지 확인합니다. 예를 들어, 데이터프레임의 행과 열 구조를 파악합니다.
- 데이터 크기: 데이터셋의 크기(행 수와 열 수)를 확인합니다.
- 데이터 타입: 각 열의 데이터 타입을 확인하여, 숫자형, 문자열형, 날짜형 등의 타입을 파악합니다.
- 결측치 및 이상치 처리
- 결측치 처리: 데이터셋 내 누락된 값을 확인하고 처리합니다. 결측치를 처리하는 방법으로는 평균값으로 대체, 삭제, 또는 예측 모델을 사용하는 방법 등이 있습니다.
- 이상치 처리: 비정상적으로 벗어난 값을 탐지하고 처리합니다. 이상치를 처리하는 방법으로는 해당 값을 수정하거나 제거하는 방법이 있습니다.
데이터 타입별 전처리 과정
숫자형 데이터 전처리
- 결측값 및 이상값 처리
- 평균값으로 대체: 결측값을 해당 열의 평균값으로 대체합니다.
- 중앙값으로 대체: 결측값을 해당 열의 중앙값으로 대체합니다.
- 이웃값으로 대체: 결측값을 인접한 값으로 대체합니다.
- 제거: 결측값이 포함된 행을 제거합니다.
- 스케일링 및 정규화
- 스케일링: 데이터의 범위를 일정한 크기로 조정합니다. 예를 들어, Min-Max 스케일링은 데이터 값을 0과 1 사이로 변환합니다.
- 정규화: 데이터의 분포를 평균이 0이고 표준편차가 1인 정규 분포로 변환합니다. 이는 모델의 성능을 향상시키는 데 유용합니다.
범주형 데이터 전처리
- 결측값 및 이상값 처리
- 최빈값으로 대체: 결측값을 해당 열에서 가장 빈번하게 나타나는 값으로 대체합니다.
- 레이블 인코딩
- 레이블 인코딩: 범주형 데이터를 숫자형 데이터로 변환합니다. 예를 들어, 'A', 'B', 'C'와 같은 범주를 각각 0, 1, 2로 변환합니다.
- 원-핫 인코딩: 범주형 데이터를 이진 벡터로 변환합니다. 예를 들어, 'A', 'B', 'C'는 [1, 0, 0], [0, 1, 0], [0, 0, 1]로 변환됩니다.
날짜 및 시간 데이터 전처리
- 형식 변환 및 추출
- 형식 변환: 날짜 및 시간 데이터를 표준 형식으로 변환합니다. 예를 들어, 문자열 형태의 날짜를 datetime 객체로 변환합니다.
- 추출: 연도, 월, 일, 시간, 분, 초와 같은 특정 요소를 추출하여 새로운 변수로 생성합니다. 예를 들어, '2023-07-12'에서 연도(2023), 월(7), 일(12)을 추출합니다.
텍스트 데이터 전처리
- 텍스트 정제 및 벡터화
- 텍스트 정제: 불필요한 문자 제거, 소문자 변환, 공백 제거 등의 전처리 과정을 수행합니다.
- 벡터화: 텍스트 데이터를 수치형 데이터로 변환합니다. 예를 들어, 단어 빈도 벡터화(Bag-of-Words), TF-IDF, 워드 임베딩(Word Embedding) 등을 사용하여 텍스트를 벡터로 변환합니다.
데이터 정제 - 결측치의 종류
데이터 결측치의 종류는 아래와 같습니다.

MCAR (Missing Completely at Random)
- 개념: 데이터가 완전히 무작위로 누락된 경우로, 누락된 데이터와 어떤 변수 간에도 상관관계가 없습니다.
- 예시: 설문 조사에서 무작위로 질문을 건너뛴 경우. 이러한 누락은 특정 패턴 없이 발생하며, 전체 데이터셋에 고르게 분포됩니다.
MAR (Missing at Random)
- 개념: 데이터 누락이 다른 관측 가능한 변수와 관련된 경우로, 누락된 데이터 자체와는 상관관계가 없습니다.
- 예시: 나이가 많은 응답자들이 소득 정보를 제공하지 않은 경우. 여기서 나이는 관측 가능한 변수로, 이 변수와 관련하여 소득 정보가 누락됩니다.
MNAR (Missing Not at Random)
- 개념: 데이터 누락이 자체 변수와 관련된 경우로, 누락된 데이터 자체와 상관관계가 있습니다.
- 예시: 높은 소득을 가진 사람들이 소득 정보를 제공하지 않은 경우. 여기서 소득 정보 자체가 누락의 원인이 됩니다.
데이터 정제 - 결측값의 원인
또한 결측값의 원인은 3가지 원인이 있습니다.
데이터 입력 오류
- 개념: 수동 입력 과정에서 발생하는 실수로 인해 데이터가 누락됩니다.
- 예시: 데이터 입력자가 실수로 값을 입력하지 않거나, 잘못된 값을 입력하여 누락이 발생하는 경우.
응답자의 미응답
- 개념: 설문 조사나 인터뷰에서 특정 질문에 대한 응답이 누락되는 경우입니다.
- 예시: 응답자가 민감한 질문에 답변을 피하거나, 특정 질문을 건너뛰는 경우.
데이터 수집 과정의 문제
- 개념: 데이터 수집 과정에서 발생하는 기술적 문제로 인해 데이터가 누락됩니다.
- 예시: 센서 오작동, 통신 오류, 데이터베이스 저장 문제 등으로 인해 데이터가 제대로 수집되지 않는 경우.
데이터 정제 - 이상치(Outlier)
Outlier(이상치)는 데이터 분포에서 벗어난 극단적인 값을 의미합니다.
이는 데이터 세트에서 다른 값들과 비교했을 때 현저히 크거나 작은 값을 가리킵니다.
- Outlier(이상치)는 통계적 분석과 모델 성능에 큰 영향을 줄 수 있습니다.
- 예를 들어, 평균 값을 왜곡하거나, 회귀 분석의 결과를 부정확하게 만들 수 있습니다.
Outlier(이상치)의 원인
데이터 입력 오류
- 개념: 수동 및 자동화된 시스템에서 발생할 수 있는 오류로 인해 이상치가 발생합니다.
- 예시: 수동 데이터 입력 시 실수로 잘못된 값을 입력하거나, 센서 오작동으로 인해 비정상적인 데이터가 수집되는 경우.
데이터 수집 문제
- 개념: 잘못된 수집 방법이나 전송 과정에서의 오류로 인해 이상치가 발생할 수 있습니다.
- 예시: 데이터 전송 중 네트워크 문제로 인한 값의 손상 또는 데이터 수집 장비의 오작동으로 인한 오류.
이질적인 데이터
- 개념: 서로 다른 특성을 가진 그룹의 혼합이나 드문 이벤트로 인해 발생하는 이상치입니다.
- 예시: 서로 다른 연령대의 데이터가 하나의 데이터셋에 포함되어 평균 연령을 왜곡시키는 경우.
자연적 변동성
- 개념: 데이터의 자연스러운 변동성으로 인해 이상치가 발생할 수 있습니다.
- 예시: 일일 기온 데이터에서 자연스럽게 발생하는 극단적인 기온 변화.
특이한 상황 또는 조건
- 개념: 특정 상황에서만 발생하는 예외적인 값으로 인해 이상치가 발생합니다.
- 예시: 특정 날에만 발생하는 극단적인 판매량 증가, 예를 들어 블랙 프라이데이 같은 이벤트.
데이터 변환
Scaling (스케일링)
스케일링은 데이터의 범위를 임의로 조정해주는 과정입니다.
- 이는 모델 학습 시 다양한 특성의 단위 차이를 없애고, 동일한 스케일로 조정하여 학습을 더 효과적으로 할 수 있도록 돕습니다.
Standardization (표준화)
표준화는 데이터의 평균을 0, 표준편차를 1로 변환하여 데이터의 분포를 표준정규 분포로 만드는 과정입니다.

- 이를 통해 데이터의 중심을 0으로 맞추고, 분포를 일정하게 합니다.
- 예를 들어, 키와 몸무게 데이터를 표준화하면, 각 데이터 포인트는 평균에서 얼마나 떨어져 있는지, 표준편차 단위로 표현됩니다.
Normalization (정규화)
정규화는 데이터를 특정 범위로 변환하는 과정입니다.

- 주로 0에서 1 사이의 범위로 변환하며, 이는 regularization(규제화)와는 다릅니다.
- 예를 들어, 가격 데이터가 0에서 1 사이로 정규화되면, 모든 가격 값이 해당 범위 내에 위치하게 됩니다.
데이터 변환의 이유
그러면 우리가 데이터 분석을 할때 데이터 변환을 하는 이유는 무엇일까요?
- 단위 차이 제거
- 다양한 특성의 단위 차이를 없애고, 동일한 스케일로 조정하여 모델 학습에 도움을 줍니다.
- 예를 들어, 키(cm)와 몸무게(kg)의 단위 차이를 제거합니다.
- 계산의 안정성과 속도 향상
- 데이터를 일정한 범위로 조정하여 계산의 안정성과 속도를 향상시킵니다.
- 이는 특히 Gradient Descent(경사 하강법)과 같은 최적화 알고리즘에서 중요합니다.
- 모델 성능 향상
- 스케일링된 데이터는 모델이 더 빠르고 정확하게 수렴하도록 도와줍니다.
- 이는 특히 신경망과 같은 복잡한 모델에서 중요한 역할을 합니다.
Data Encoding (데이터 인코딩)
Label Encoding (레이블 인코딩)
레이블 인코딩은 범주형 데이터를 숫자로 변환하는 기법입니다. 각 범주를 고유한 정수로 매핑하여 수치형 데이터로 변환합니다.
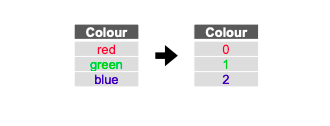
- 변환 방식: 각 범주를 고유한 정수 값으로 변환합니다. 예를 들어, ['사과', '바나나', '체리']를 [0, 1, 2]로 변환합니다.
- 장점: 단순하고, 메모리 사용량이 적습니다.
- 단점: 범주 간 순서가 없는 경우, 모델이 잘못된 관계를 학습할 수 있습니다.
- 예를 들어, '사과', '바나나', '체리'가 0, 1, 2로 변환되면, 모델이 '사과'와 '바나나' 사이에 순서 관계가 있다고 오인할 수 있습니다.
Label Encoding Example
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
labels = ['사과', '바나나', '체리']
encoded_labels = le.fit_transform(labels)
print(encoded_labels) # Output: [0, 1, 2]
One-Hot Encoding (원-핫 인코딩)
원-핫 인코딩은 범주형 데이터를 이진 벡터로 변환하는 기법입니다. 각 범주는 이진 벡터의 고유한 위치에 1로 표시됩니다.
이를 통해 범주 간 순서가 없는 데이터를 처리할 때 유용합니다.
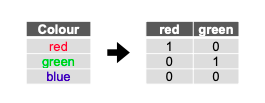
- 변환 방식: 각 범주를 이진 벡터로 변환합니다. 예를 들어, ['사과', '바나나', '체리']를 [[1, 0, 0], [0, 1, 0], [0, 0, 1]]로 변환합니다.
- 장점: 범주 간 순서 관계가 없음을 명확히 표현할 수 있습니다.
- 단점: 많은 범주가 있는 경우, 고차원 데이터로 변환되어 메모리 사용량이 증가할 수 있습니다.
One-Hot Encoding Example
from sklearn.preprocessing import OneHotEncoder
import numpy as np
ohe = OneHotEncoder(sparse=False)
labels = np.array(['사과', '바나나', '체리']).reshape(-1, 1)
encoded_labels = ohe.fit_transform(labels)
print(encoded_labels)
# Output: [[1. 0. 0.]
# [0. 1. 0.]
# [0. 0. 1.]]
날씨 & 시간 데이터 변환
형식 변환이란?
형식 변환은 문자열 형식의 날짜 데이터를 'datetime' 형식으로 변환하는 과정을 의미합니다.
- 날짜 연산 및 비교를 쉽게 수행할 수 있도록 하기 위해 진행됩니다.
- 필요성: 날짜 데이터를 datetime 형식으로 변환하면, 날짜 간의 차이를 계산하거나 특정 날짜를 기준으로 데이터를 정렬하는 등의 작업이 간편해집니다.
- 예시: "2023-07-12"와 같은 문자열 형식의 날짜를 datetime 객체로 변환하여 다양한 날짜 연산을 수행할 수 있습니다.
형식 변환 Example
import pandas as pd
# 문자열 형식의 날짜 데이터
date_str = "2023-07-12"
# datetime 형식으로 변환
date_dt = pd.to_datetime(date_str)
print(date_dt)
# Output: 2023-07-12 00:00:00
추출
추출은 'datetime' 객체에서 특정 정보(연도, 월, 일 등)를 추출하는 과정을 의미합니다.
- 날짜 데이터에서 특정 정보를 추출하여 분석에 활용하기 위해 진행됩니다.
- 필요성: 분석 목적에 따라 연도, 월, 일, 시간 등의 특정 정보를 추출하여 사용해야 하는 경우가 많습니다. 예를 들어, 월별 판매량을 분석하거나 특정 기간 동안의 변화를 파악할 수 있습니다.
- 예시: datetime 객체에서 연도, 월, 일을 추출하여 새로운 변수를 생성할 수 있습니다.
추출 Example
import pandas as pd
# datetime 형식의 날짜 데이터
date_dt = pd.to_datetime("2023-07-12")
# 연도, 월, 일 추출
year = date_dt.year
month = date_dt.month
day = date_dt.day
print(f"Year: {year}, Month: {month}, Day: {day}")
# Output: Year: 2023, Month: 7, Day: 12데이터 통합 및 변환
데이터 합치기
데이터 합치기는 여러 데이터를 하나로 결합하는 과정을 의미합니다.
공통된 키 또는 인덱스를 사용하여 데이터 간의 관계를 바탕으로 데이터를 결합합니다.
- 예시: 고객 정보 데이터와 거래 내역 데이터를 결합하여 고객 행동을 분석할 수 있습니다.
import pandas as pd
# 예시 데이터프레임
customer_data = pd.DataFrame({
'customer_id': [1, 2, 3],
'name': ['Alice', 'Bob', 'Charlie']
})
transaction_data = pd.DataFrame({
'customer_id': [1, 2, 1, 3],
'purchase_amount': [100, 150, 200, 50]
})
# 데이터 합치기
merged_data = pd.merge(customer_data, transaction_data, on='customer_id')
print(merged_data) customer_id name purchase_amount
0 1 Alice 100
1 1 Alice 200
2 2 Bob 150
3 3 Charlie 50
데이터 집계
데이터 집계는 데이터의 특정 열을 기준으로 합계, 평균 등의 요약 통계를 계산하는 과정을 의미합니다. 그룹별로 데이터를 요약합니다.
- 예시: 월별 매출 데이터에서 각 월의 총 매출을 계산할 수 있습니다.
import pandas as pd
# 예시 데이터프레임
sales_data = pd.DataFrame({
'month': ['Jan', 'Feb', 'Jan', 'Feb', 'Mar'],
'sales': [200, 150, 300, 200, 250]
})
# 월별 총 매출 계산
monthly_sales = sales_data.groupby('month').sum()
print(monthly_sales) sales
month
Feb 350
Jan 500
Mar 250
데이터 그룹화
데이터 그룹화는 특정 열을 기준으로 데이터를 그룹화하여 집계하는 과정을 의미합니다.
- 예시: 각 제품군별 평균 판매량을 계산할 수 있습니다.
import pandas as pd
# 예시 데이터프레임
product_data = pd.DataFrame({
'product': ['A', 'B', 'A', 'B', 'C'],
'sales': [100, 200, 150, 250, 300]
})
# 제품군별 평균 판매량 계산
product_sales = product_data.groupby('product').mean()
print(product_sales) sales
product
A 125.0
B 225.0
C 300.0
데이터 변경 (재구조화)
데이터 변형은 데이터프레임의 형태를 변경하는 다양한 기법을 의미합니다. 데이터를 요약하거나 분석 목적에 맞게 재구성합니다.
- 예시: 긴 형식의 데이터를 넓은 형식으로 변환할 수 있습니다.
import pandas as pd
# 예시 데이터프레임
long_data = pd.DataFrame({
'date': ['2023-07-01', '2023-07-01', '2023-07-02'],
'variable': ['A', 'B', 'A'],
'value': [10, 20, 15]
})
# 넓은 형식으로 변환
wide_data = long_data.pivot(index='date', columns='variable', values='value')
print(wide_data)ariable A B
date
2023-07-01 10.0 20.0
2023-07-02 15.0 NaN
데이터 피벗
데이터 피벗은 데이터프레임의 행과 열을 변환하여 데이터를 요약하는 과정을 의미합니다.
특정 열을 인덱스로 사용하고, 다른 열을 새로운 열로 변환합니다.
- 예시: 월별 제품 판매 데이터를 피벗하여 각 제품의 월별 판매량을 열로 변환할 수 있습니다.
import pandas as pd
# 예시 데이터프레임
sales_data = pd.DataFrame({
'month': ['Jan', 'Jan', 'Feb', 'Feb', 'Mar'],
'product': ['A', 'B', 'A', 'B', 'A'],
'sales': [100, 150, 200, 250, 300]
})
# 데이터 피벗
pivot_data = sales_data.pivot(index='month', columns='product', values='sales')
print(pivot_data)product A B
month
Feb 200.0 250.0
Jan 100.0 150.0
Mar 300.0 NaN데이터 전처리 Advanced
파생변수 생성
파생 변수 생성은 기존 데이터에서 새로운 변수를 생성하는 과정을 의미합니다.
- 이는 기존 변수 간의 상호작용, 계산 또는 변환을 통해 새로운 정보를 추출하여 데이터의 정보량을 증가시킵니다.
- 또한 분석 및 모델링 성능을 향상시킵니다.
- 날짜 데이터에서 파생 변수 추출
- 예시: 연도, 월, 일, 요일 등을 추출하여 분석의 깊이를 더할 수 있습니다.
import pandas as pd
# 날짜 데이터
df = pd.DataFrame({'date': pd.to_datetime(['2023-07-12', '2023-07-13'])})
df['year'] = df['date'].dt.year
df['month'] = df['date'].dt.month
df['day'] = df['date'].dt.day
df['weekday'] = df['date'].dt.weekday
print(df)
- 텍스트 데이터에서 파생 변수 생성
- 예시: 텍스트 길이, 단어 수 등을 파생 변수로 생성할 수 있습니다.
df = pd.DataFrame({'text': ['This is a sentence.', 'Another sentence here.']})
df['text_length'] = df['text'].apply(len)
df['word_count'] = df['text'].apply(lambda x: len(x.split()))
print(df)
- 키와 몸무게를 이용한 BMI 데이터 생성
- 예시: BMI = 몸무게 / (키/100)^2
df = pd.DataFrame({'height': [170, 180], 'weight': [70, 80]})
df['BMI'] = df['weight'] / (df['height'] / 100) ** 2
print(df)
Data Sampling (데이터 샘플링)
데이터 샘플링은 전체 데이터셋에서 일부 데이터를 선택하여 분석이나 모델링에 사용하는 과정을 의미합니다.
이는 모집단의 특성을 대표하는 샘플을 추출하여 분석의 신속성을 높이고, 대용량 데이터 처리 시간과 비용을 절감할 수 있습니다.
- 랜덤 샘플링: 데이터셋에서 무작위로 샘플을 추출합니다.
df = pd.DataFrame({'data': range(100)})
sample = df.sample(n=10)
print(sample)- 층화 샘플링: 모집단을 여러 층으로 나누고 각 층에서 샘플을 추출합니다.
from sklearn.model_selection import train_test_split
df = pd.DataFrame({'data': range(100), 'group': [0, 1] * 50})
train, test = train_test_split(df, test_size=0.2, stratify=df['group'])
print(train['group'].value_counts())
print(test['group'].value_counts())
PCA (차원 축소 기법)
차원 축소 기법은 고차원 데이터를 저차원으로 변환하여 데이터의 복잡성을 줄이는 과정을 의미합니다.
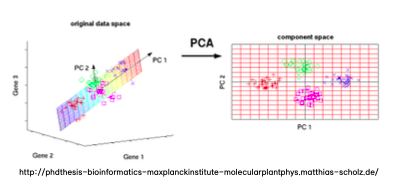
- 이는 데이터의 변동성을 최대한 보존하면서 주요 특성을 추출하여 데이터의 시각화와 이해를 용이하게 하고, 모델의 과적합을 방지하며 계산 효율성을 향상시킵니다.
- PCA (Principal Component Analysis): 데이터의 분산을 최대한 보존하는 새로운 축을 찾아 데이터를 변환합니다.
from sklearn.decomposition import PCA
import numpy as np
# 예시 데이터
data = np.random.rand(100, 5)
pca = PCA(n_components=2)
reduced_data = pca.fit_transform(data)
print(reduced_data)
- t-SNE (t-distributed Stochastic Neighbor Embedding): 고차원 데이터를 저차원으로 변환하여 데이터의 구조를 시각화하는 데 유용한 기법입니다.
from sklearn.manifold import TSNE
# 예시 데이터
data = np.random.rand(100, 5)
tsne = TSNE(n_components=2)
reduced_data = tsne.fit_transform(data)
print(reduced_data)데이터 전처리 최적화
전처리 작업의 자동화
전처리 작업의 자동화는 반복적이고 일관된 전처리 작업을 자동으로 수행하여 효율성을 높이는 과정을 의미합니다.
이는 스크립트 및 파이프라인을 사용하여 전처리 작업을 자동으로 실행합니다.
- 효율성: 수동 작업의 오류를 줄이고, 작업 시간을 단축하며, 일관성을 유지할 수 있습니다.
- 자동화 도구: 스크립트와 파이프라인을 활용하여 전처리 작업을 자동화합니다.
파이프라인 구축
파이프라인 구축은 일련의 전처리 단계를 순차적으로 자동으로 실행하는 과정을 의미합니다.
각 단계별로 전처리 작업을 정의하고 이를 파이프라인으로 연결하여 전처리 작업의 일관성과 재현성을 보장합니다.
- 실제 코드상의 파이프라인: 코딩을 통해 전처리 파이프라인을 작성하여 자동화를 구현합니다.
- 의미/구조상의 파이프라인: 전처리 작업의 순서를 의미적으로 정의하여 구조적으로 연결합니다.
예시 코드
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.impute import SimpleImputer
# 수치형 및 범주형 변수의 전처리 파이프라인 구성
numeric_features = ['age', 'salary']
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler())
])
categorical_features = ['gender', 'department']
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
# 전체 데이터 전처리 파이프라인 구성
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
]
)
대용량 데이터 처리
대용량 데이터를 효율적으로 처리하기 위한 전략과 기법을 의미합니다.
이는 분산 처리, 병렬 처리, 메모리 관리 등의 기법을 사용하여 데이터 처리의 효율성을 높입니다.
- 분산 처리: 데이터를 여러 노드에 분산하여 동시에 처리합니다. Hadoop, Spark 등의 분산 처리 프레임워크를 사용합니다.
- 병렬 처리: 데이터를 여러 프로세스에서 동시에 처리합니다. multiprocessing, Dask 등의 병렬 처리 라이브러리를 사용합니다.
- 메모리 관리: 메모리 사용을 최적화하여 대용량 데이터를 효율적으로 처리합니다. 데이터 타입 최적화, 청크(chunk) 단위 처리를 통해 메모리 사용을 줄입니다.
# Dask를 사용한 병렬 처리 예시
import dask.dataframe as dd
# CSV 파일을 Dask DataFrame으로 로드
df = dd.read_csv('large_dataset.csv')
# 데이터 처리
df = df[df['value'] > 0]
result = df.groupby('category').mean().compute()
print(result)
전처리 과정의 효율성 향상?
전처리 과정의 속도와 효율성을 높이기 위한 다양한 기법을 의미합니다.
최적화된 알고리즘, 코딩 스타일 개선, 적절한 데이터 구조 사용 등을 통해 데이터 전처리 시간을 단축하고, 리소스 사용을 최적화합니다.
- 최적화된 알고리즘: 알고리즘을 최적화하여 데이터 처리 속도를 높입니다.
- 코딩 스타일 개선: 효율적인 코딩 스타일을 통해 전처리 작업의 속도와 가독성을 높입니다.
- 적절한 데이터 구조 사용: 작업에 적합한 데이터 구조를 사용하여 효율성을 높입니다. pandas, NumPy, Dask 등의 라이브러리를 적절히 활용합니다.
import pandas as pd
import numpy as np
# pandas를 사용한 효율적인 데이터 처리
df = pd.DataFrame({'A': range(1, 100001), 'B': range(100001, 200001)})
# 벡터화 연산을 사용한 효율적인 계산
df['C'] = df['A'] + df['B']반응형
'📊 Data Analysis' 카테고리의 다른 글
| [Data Analysis] 기초 통계, 상관 & 인과관계 (0) | 2024.07.18 |
|---|---|
| [Data Analysis] 데이터의 종류와 속성 & 데이터 탐색 (EDA) (0) | 2024.07.18 |
| [Data Analysis] Data Analysis - 데이터 분석 (0) | 2024.07.17 |
| [Data Analysis] 데이터 수집 (Crawling, Scrapping) (0) | 2024.07.12 |
| [Data Analysis] 데이터의 활용 및 구현 (0) | 2024.07.12 |