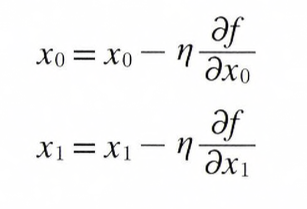그러면 모든 편미분을 벡터로 정리를 해야 하는데, 그 정리한것을 Grdient(기울기)라고 합니다.
예를 들어서 아래의 코드와 같이 구현할 수 있습니다.
def numerical_gradient(f, x):
h = 1e-4
grad = np.zeros_like(x) # x와 형상이 같은 배열을 생성
for idx in range(x.size):
tmp_val = x[idx]
# f(x+h) 계산
x[idx] = tmp_val + h
fxh1 = f(x)
# f(x-h) 계산
x[idx] = tmp_val - h
fxh2 = f(x)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val
return grad
numerical_gradient(f, x) 함수의 구현은 좀 복잡하게 보이지만, 동작 방식은 변수가 하나일때의 수치 미분과 거이 같습니다.
참고로, np.zeros_like(x)는x와 형상이 같고 그 원소가 모두 0인 배열을 만듭니다.
numerical_gradient(f, x) 함수의 인수인 f는 함수이고 x는Numpy 배열이므로, Numpy 배열 x의 각 원소에 대해서 수치 미분을 구합니다.
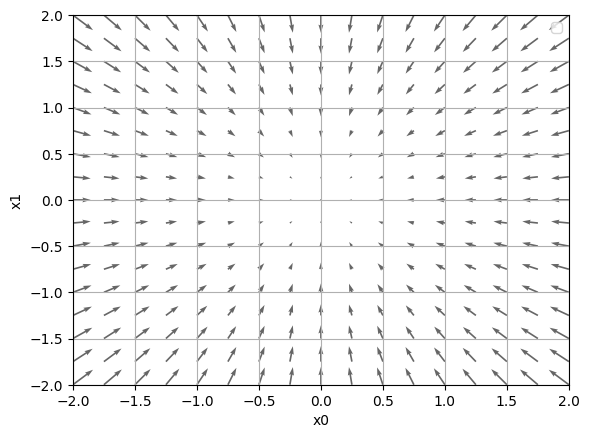
근데, 그러면 Gradient(기울기)가 의미 하는게 무엇일까요? 그림으로 한번 보겠습니다.
위의 수식의 기울기를 나타낸 그림.
이 그림은 Gradient(기울기)의 결과에 마이너스를 붙인 벡터입니다.
Gradient(기울기)그림은'가장 낮은 장소(최소값)'을 가리키는거 같습니다. 마치 나침반처럼 화살표들은 한점을 향하고 있습니다.
그리고'가장 낮은곳'에서 멀어질수록 화살표의 크기가 커짐을 알 수 있습니다.
그리고 기울기는각 지점에서 낮아지는 방향을 가리킵니다.
정확히 말하면,기울기가 가리키는 쪽은 각 장소에서 함수의 출력 값을 가장 크게 줄이는 방향입니다. 이건 중요한 점입니다!
Gradient Descent (경사법 - 경사하강법)
손실 함수가 최솟값이 될 때의 매개변수 값을 구해야 하는데,기울기를 활용해서 함수의 최솟값을 찾을 수 있습니다.
Gradient(기울기)가기울어진 방향으로 나아가가는 것을 반복해서 함수의 값을 점차 줄이는 것을Gradient Method(경사법)이라고 합니다.
근데,Gradient(기울기)가 가리키는 곳에 정말 함수의 최소값이 있는지? 그쪽이 나아갈 방향인지는 보장할 수 없습니다.
실제로 복잡한 함수에서는 기울기가 가리키는 방향에 최소값이 없는 경우가 대부분이기 때문입니다. 이때Gradient Method(경사법)을 사용합니다.
한번 Gradient Method(경사법)을 수식으로 나타내 보겠습니다.
경사법(Gradient Method)의 수식
위의 식에서n기호(에타)는 갱신하는 양을 나타냅니다. 이를 신경망에서는Learning Rate(학습률)이라고 합니다.
1번의 학습으로 얼마만큼 학습해야 할지, 즉, 매개변수 값을 얼마나 갱신하느냐를 정하는 것이Learning Rate(학습률)입니다.
그리고 위의 수식은 1회에 해당하는 갱신이고, 이단계를 반복해서 서서이 함수의 값을 줄이는 것입니다.
또한 Learning Rate(학습률)의 값은 미리특정 값으로 정해놔야 합니다. 일반적으로 값이 너무 크거나 작으면'좋은 장소'를 찾아갈 수 없습니다.
Gradient Descent(경사하강법)은 아래의 코드로 간단하게 구현할 수 있습니다.
def gradient_descent(f, init_x, lr=0.01, step_num=100):
x = init_x
for i in range(step_num):
grad = numerical_gradient(f, x)
x -= lr * grad
return x
코드를 한번 설명해 보겠습니다
인수f는 최적화하려는 함수,init_x는 초깃값,lr은 learning rate를 의미하는 학습률,step_num은 경사법에 따른 반복 횟수입니다.
numerical_gradient(f, x)로 함수의 Gradient(기울기)를 구합니다.
그리고 Gradient(기울기)에 학습률을 곱한 값으로 갱신하는 처리를step_num만큼 반복합니다.
Neural Network(신경망)에서의 Gradient(기울기)
신경망 학습에서도 Gradient(기울기)를 구해야 합니다. 여기서 말하는Gradient(기울기)는 Weight Parameter(가중치 매개변수)에 대한 Loss Function(손실함수)의 Gradient(기울기)입니다.
그러면 간단한 신겸망을 예를 들어서 실제로 Gradient(기울기)를 구현하는 코드를 구현해보겠습니다. (by Python)
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록 설정
import numpy as np
from common.functions import softmax, cross_entropy_error
from common.gradient import numerical_gradient
class simpleNet:
def __init__(self):
self.W = np.random.randn(2,3) # 정규분포로 초기화
def predict(self, x):
return np.dot(x, self.W)
def loss(self, x, t):
z = self.predict(x)
y = softmax(z)
loss = cross_entropy_error(y, t)
return loss
x = np.array([0.6, 0.9])
t = np.array([0, 0, 1])
net = simpleNet()
f = lambda w: net.loss(x, t)
dW = numerical_gradient(f, net.W)
print(dW)
Training Data(훈련 데이터)에 포함된 Image만 제대로 구분하고, 그렇지 않은 이미지는 제대로 식별 할 수 없습니다.
import numpy as np
from dataset.mnist import load_mnist
from two_layer_net import TwoLayerNet
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
train_loss_list = []
# 하이퍼파라미터
iters_num = 10000 # 반복 횟수
train_size = x_train.shape[0]
batch_size = 100 # 미니배치 크기
learning_rate = 0.1
train_loss_list = []
train_acc_list = []
test_acc_list = []
# 1에폭당 반복 수
iter_per_epoch = max(train_size / batch_size, 1)
for i in range(iters_num):
# 미니배치 획득
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 기울기 계산
grad = network.gradient(x_batch, t_batch)
# 매개변수 갱신
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
# 학습 경과 기록
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
# 1에폭 당 정확도 계산
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print("train acc, test acc | "+ str(train_acc) + ", +str(test_acc))
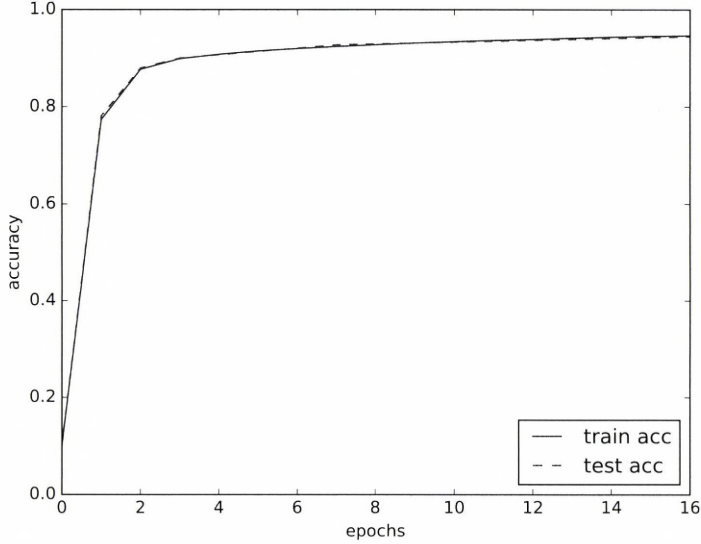
1 epoch마다 모든 훈련 데이터와 시험 데이터에 대한 정확도를 계산 및 결과를 기록합니다.
여기서 우리가 알 수 있는건, 학습(epoch)을 수행 할때 마자 정확도가 좋아집니다.
즉, Overfitting이 일어나지 않습니다.
Summary(정리)
- 기계학습에서 사용하는 데이터셋은 훈련 데이터와 시험 데이터로 나눠 사용한다. - 훈련 데이터로 학습한 모델의 범용 능력을 시험 데이터로 평가한다. - 신경망 학습은 손실 함수의 지표로, 손실 함수의 값이 작아지는 방향으로 가중치 매개변수를 갱신한다. - 가중치 매개변수를 갱신할 때는 가중치 매개변수의 기울기를 이용하고, 기울어진 방향으로 가중치의 값을 갱신하는 작업을 반복한다. - 아주 작은 값을 주었을 때의 차분으로 미분하는 것을 수치 미분이라고 한다. - 수치 미분을 이용해 가중치 매개변수의 기울기를 구할 수 있다. - 수치 미분을 이용한 계산에는 시간이 걸리지만, 그 구현은 간단하다. 한편, 다음 장에서 구현하는 오차역전파법은 기울기를 고속으로 구할 수 있다.