Getting Data
from collections import Counter
import math, random, csv, json, re
from bs4 import BeautifulSoup
import requests
예를 들어, beautifulsoup 같은, 어떤 모듈이 설치되지 않았다면? 어떻게 해야 할까요?
- googling: 아나콘다 beautifulsoup 설치 방법
- 구글 답변에서 아나콘다 클라우드를 찾으세요. 모듈들이 테스트되고 안전한 곳입니다.
- 이제, 여러분은 부끄러운 정도로 많은 시간을 acquiring(획득), cleaning(정리), and transforming data(데이터 변환)에 할애하게 될 것입니다.
stdin and stdout
Number of lines containing numbers
숫자가 포함된 파일의 행 수를 셀 수 있습니다.
sys.stdin(Keyboard) 및 sys.stdout(Monitor)을 사용하여 데이터를 파이프할 수 있습니다.
import sys, re
# sys.argv는 명령줄 인수의 리스트입니다.
# sys.argv[0]은 프로그램 자체의 이름입니다.
# sys.argv[1]은 명령줄에서 지정한 정규 표현식이 될 것입니다.
regex = sys.argv[1]
# 스크립트에 전달된 각 줄에 대해
for line in sys.stdin:
# 만약 정규 표현식과 일치하는 경우, 그것을 stdout에 씁니다.
if re.search(regex, line): # Regular Expression과 맞는 라인
sys.stdout.write(line)
- 명령줄에서 사용자가 지정한 정규 표현식을 이용하여 입력으로 받은 각 줄에 대해 검색하고, 해당 정규 표현식과 일치하는 경우 해당 줄을 표준 출력에 씁니다.
import sys
count = 0
# sys.stdin에서 각 줄을 읽어들여서
for line in sys.stdin:
# count 변수를 증가시킵니다.
count += 1
# print 함수는 sys.stdout에 출력됩니다.
print(count)
0
# Windows
!type the_bible.txt | python egrep.py "[0-9]" | python line_count.py
/bin/bash: line 1: type: the_bible.txt: not found
python3: can't open file '/content/egrep.py': [Errno 2] No such file or directory
python3: can't open file '/content/line_count.py': [Errno 2] No such file or directory
Most Common Words
입력된 단어를 세어 가장 일반적인 단어를 작성하는 스크립트 입니다.
import sys
from collections import Counter
# 첫 번째 인자로 단어의 수를 전달합니다.
try:
num_words = int(sys.argv[1]) # 명령어 argument -> Command
except:
print("usage: most_common_words.py num_words")
sys.exit(1) # 비정상적 종료 코드는 오류를 나타냅니다.
# 표준 입력에서 각 줄을 읽어들여서
# 소문자로 변환한 단어를 카운트합니다.
counter = Counter(word.lower() # 소문자로 변환된 단어
for line in sys.stdin # 표준 입력으로부터의 각 줄
for word in line.strip().split() # 공백으로 분리된 단어들
if word) # 빈 '단어'는 건너뜁니다.
# 가장 빈도가 높은 단어를 찾아 출력합니다.
for word, count in counter.most_common(num_words):
sys.stdout.write(str(count)) # 빈도를 출력합니다.
sys.stdout.write("\\t") # 탭 문자로 구분합니다.
sys.stdout.write(word) # 단어를 출력합니다.
sys.stdout.write("\\n") # 줄 바꿈 문자로 줄을 바꿉니다.
# Windows
!type the_bible.txt | python most_common_words.py 10
64193 the
51380 and
34753 of
13643 to
12799 that
12560 in
10263 he
9840 shall
8987 unto
8836 for
Reading Files
The Basics of Text Files
# 'r'은 읽기 전용을 의미합니다.
file_for_reading = open('reading_file.txt', 'r')
# 'w'는 쓰기를 의미합니다 — 이미 파일이 존재하면 파일을 파괴합니다!
file_for_writing = open('writing_file.txt', 'w')
# 'a'는 추가를 의미합니다 — 파일 끝에 추가합니다.
file_for_appending = open('appending_file.txt', 'a')
# 파일을 사용한 후에는 파일을 꼭 닫아야 합니다.
file_for_writing.close() # Why? Open file 개수가 정해져 있기 떼문
- 파일을 닫는 것을 잊기 쉽기 때문에 항상 블록과 함께 사용해야 하며, 블록이 끝나면 자동으로 닫힙니다.
with open(filename, 'r') as f:
# 'f'를 통해 데이터를 가져오는 함수를 호출하여 데이터를 가져옵니다.
data = function_that_gets_data_from(f)
# 이 시점에서 'f'는 이미 닫혔으므로 사용하지 마십시오.
# 가져온 데이터를 처리합니다.
process(data)
starts_with_hash = 0
# 'input.txt' 파일을 읽기 모드로 엽니다.
with open('input.txt', 'r') as f:
# 파일의 각 줄을 확인합니다.
for line in f: # 파일의 각 줄을 확인합니다.
if re.match("^#", line): # 정규식을 사용하여 줄이 '#'로 시작하는지 확인합니다.
starts_with_hash += 1 # 만약 그렇다면, 카운트에 1을 더합니다.
def get_domain(email_address):
"""'@'를 기준으로 분할하고 마지막 부분을 반환합니다."""
return email_address.lower().split("@")[-1]
# 'email_addresses.txt' 파일을 읽기 모드로 엽니다.
with open('email_addresses.txt', 'r') as f:
# 파일의 각 줄에 대해 도메인을 가져와서 카운트합니다.
# 주소에 '@'가 있는 줄만 처리합니다.
domain_counts = Counter(get_domain(line.strip()) # 각 줄의 도메인을 가져와서
for line in f # 파일의 각 줄에 대해
if "@" in line) # '@'가 있는 줄만 처리합니다.
Delimited Files
csv 파일 : 이러한 파일은 쉼표로 구분되거나 탭으로 구분되는 경우가 많습니다.
!type tab_delimited_stock_prices.txt
6/20/2014 AAPL 90.91
6/20/2014 MSFT 41.68
6/20/2014 FB 64.5
6/19/2014 AAPL 91.86
6/19/2014 MSFT 41.51
6/19/2014 FB 64.34
- csv.reader는 줄 단위 튜플 생성기입니다.
- 탭으로 구분된 텍스트 파일을 읽어들여서 각 행의 날짜, 기호 및 종가를 추출하고 출력합니다.
- CSV 모듈의 csv.reader() 함수를 사용하여 파일을 탭으로 구분하여 읽습니다.
import csv
# 'tab_delimited_stock_prices.txt' 파일을 읽기 모드로 엽니다.
with open('tab_delimited_stock_prices.txt', 'r') as f:
# 파일을 탭으로 구분하여 읽는 CSV 리더를 생성합니다.
reader = csv.reader(f, delimiter='\\t')
# CSV 파일의 각 행을 반복하면서
for row in reader:
# 각 행의 열을 추출합니다.
date = row[0] # 첫 번째 열: 날짜
symbol = row[1] # 두 번째 열: 기호
closing_price = float(row[2]) # 세 번째 열: 종가 (부동 소수점으로 변환)
# 날짜, 기호 및 종가를 출력합니다.
print(date, symbol, closing_price)
6/20/2014 AAPL 90.91
6/20/2014 MSFT 41.68
6/20/2014 FB 64.5
6/19/2014 AAPL 91.86
6/19/2014 MSFT 41.51
6/19/2014 FB 64.34
%%bash
cat colon_delimited_stock_prices.txt
date:symbol:closing_price
6/20/2014:AAPL:90.91
6/20/2014:MSFT:41.68
6/20/2014:FB:64.5
- 콜론으로 구분된 텍스트 파일을 읽어들여서 각 행의 날짜, 기호 및 종가를 추출하고 출력합니다.
- CSV 모듈의 csv.DictReader() 함수를 사용하여 파일을 읽고, 각 행을 딕셔너리로 나타냅니다.
import csv
# 'colon_delimited_stock_prices.txt' 파일을 읽기 모드로 엽니다.
with open('colon_delimited_stock_prices.txt', 'r') as f:
# 파일을 콜론으로 구분하여 읽는 CSV 딕셔너리 리더를 생성합니다.
reader = csv.DictReader(f, delimiter=':')
# CSV 파일의 각 행을 반복하면서
for row in reader:
# 각 행의 필드 값을 딕셔너리에서 추출합니다.
date = row["date"] # 'date' 필드
symbol = row["symbol"] # 'symbol' 필드
closing_price = float(row["closing_price"]) # 'closing_price' 필드 (부동 소수점으로 변환)
# 날짜, 기호 및 종가를 출력합니다.
print(date, symbol, closing_price)
6/20/2014 AAPL 90.91
6/20/2014 MSFT 41.68
6/20/2014 FB 64.5
%%bash
cat comma_delimited_stock_prices.txt
FB,64.5
MSFT,41.68
AAPL,90.91
- 오늘의 주가를 나타내는 딕셔너리를 콤마로 구분된 텍스트 파일에 쓰는 예제입니다.
- CSV 모듈의 csv.writer() 함수를 사용하여 파일을 쓰고, 각 주식과 가격을 리스트로 만들어서 파일에 씁니다.
import csv
# 오늘의 주가를 나타내는 딕셔너리입니다.
today_prices = {'AAPL': 90.91, 'MSFT': 41.68, 'FB': 64.5}
# 'comma_delimited_stock_prices_1.txt' 파일을 쓰기 모드로 엽니다.
with open('comma_delimited_stock_prices_1.txt', 'w') as f:
# 파일을 콤마로 구분하여 쓰는 CSV 라이터를 생성합니다.
writer = csv.writer(f, delimiter=',')
# 오늘의 주가 딕셔너리에서 각 주식과 가격을 가져와서 파일에 쓰기합니다.
for stock, price in today_prices.items():
# 각 주식과 가격을 리스트로 만들어서 쓰기합니다.
writer.writerow([stock, price])
%%bash
cat comma_delimited_stock_prices_1.txt
AAPL,90.91
MSFT,41.68
FB,64.5
results = [["test1", "success", "Monday"],
["test2", "success, kind of", "Tuesday"],
["test3", "failure, kind of", "Wednesday"],
["test4", "failure, utter", "Thursday"]]
# don't do this!
with open('bad_csv.txt', 'w') as f:
for row in results:
f.write(",".join(map(str, row))) # might have too many commas in it!
f.write("\\n") # row might have newlines as well!
%%bash
cat bad_csv.txt
test1,success,Monday
test2,success, kind of,Tuesday
test3,failure, kind of,Wednesday
test4,failure, utter,Thursday
Scraping the Web
데이터를 얻는 또 다른 방법은 웹 페이지에서 스크랩하는 것입니다
HTML & Parsing
<html>
<head>
<title>A web page</title>
</head>
<body>
<p id="author">Joel Grus</p>
<p id="subject">Data Science</p>
</body>
</html>
- for python3:
!pip install html5lib
!pip install beautifulsoup4- for anaconda
conda install -c anaconda html5lib
conda install -c anaconda beautifulsoup4
Html5Lib :: Anaconda.org
Description html5lib is a pure-python library for parsing HTML. It is designed to conform to the WHATWG HTML specification, as is implemented by all major web browsers.
anaconda.org
Login :: Anaconda.org
Sign in to Anaconda.org I forgot my password. I forgot my username. Register for an account.
anaconda.org
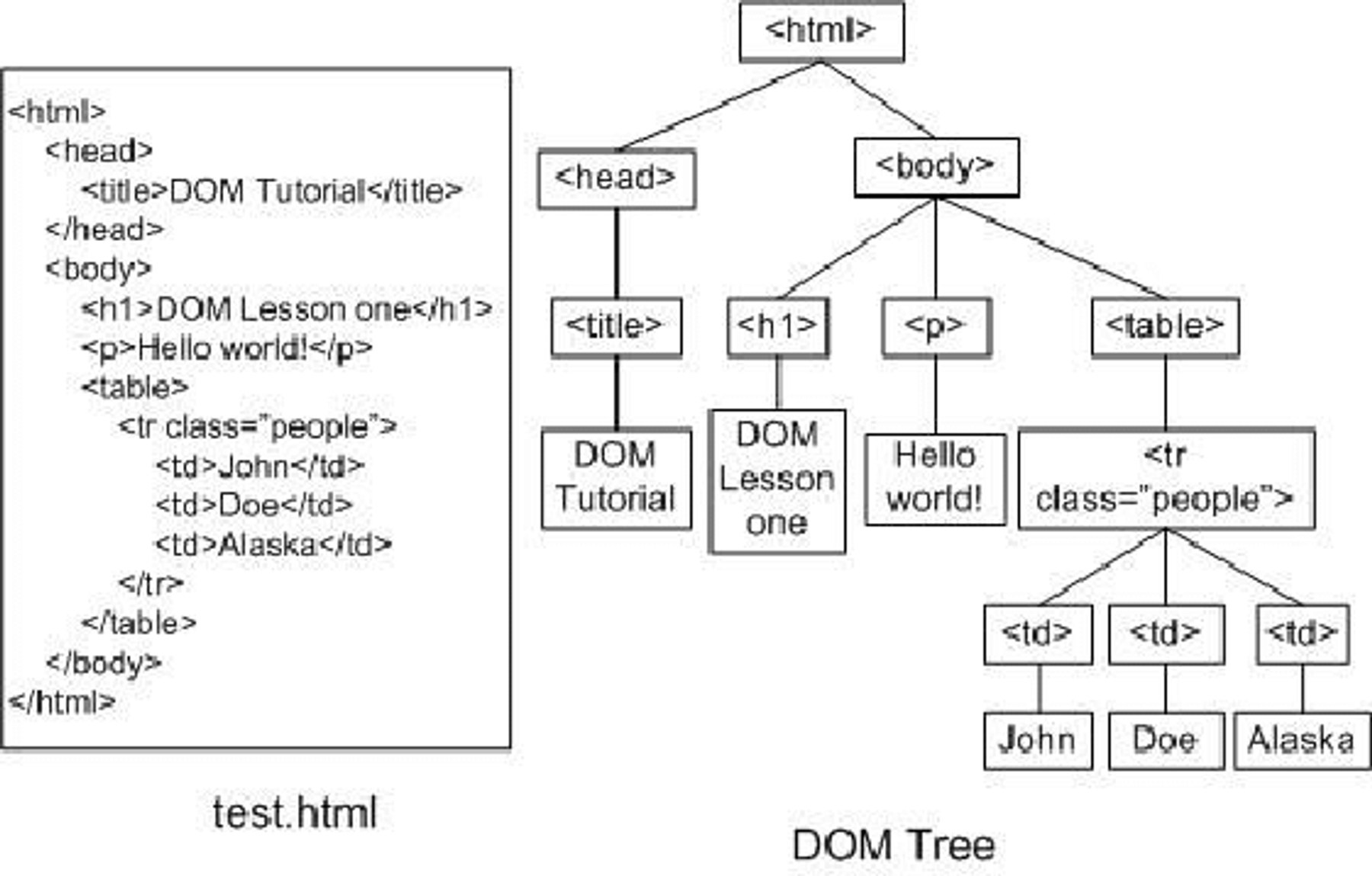
DOM Lesson One
- Hello World! - John | Doe | Alaska
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>A web page</title>
</head>
<body>
<p id="author">Joel Grus</p>
<p id="subject">Data Science</p>
<p class="price">30</p>
</body>
</html>"""
soup = BeautifulSoup(html, 'html5lib')
중요: Tag, Attribute, Text
soup = BeautifulSoup(html, 'html5lib')→ Parsing 해서 자료구조화 합니다.(Dict 화)
Query 1: Find title (제목 찾기)
soup.title.text
# 'A web page'
Query 2: Find title's text (제목 텍스트 찾기)
soup.title.text
# 'A web page'
Query 3: Find p of body (p의 본문 찾기)
soup.body.p
# <p id="author">Joel Grus</p>
Query 4: Find all p under body (p아래 본문 찾기)
soup.body('p')
[<p id="author">Joel Grus</p>,
<p id="subject">Data Science</p>,
<p class="price">30</p>]
Query 5: Find second p's text of body (두 번째 p의 본문 찾기)
soup.body('p')[1].text
# 'Data Science'
Query 6: Find last p of body (p의 마지막 부분 찾기)
soup.body('p')[-1]
# <p class="price">30</p>
Query 7: Loop over all p of body (p의 모든 부분에 루프를 씌우기)
for i, p in enumerate(soup.body('p')):
print('paragraph {}: {}'.format(i, p.text))
paragraph 0: Joel Grus
paragraph 1: Data Science
paragraph 2: 30
Query 8: Find first p's id attribute's value (첫 번째 p의 ID 속성 값 찾기)
soup.p['id']
# 'author'
Query 9: Find all p whose attribute id is 'author' (속성 ID가 '저자'인 모든 p 찾기)
soup('p', {'id':'author'})
# [<p id="author">Joel Grus</p>]
Query 10: Find all p whose attribute class is 'price' (속성 클래스가 '가격'인 모든 p 찾기)
soup('p', 'price')
#soup('p', {'class':'price'})
[<p class="price">30</p>]
Query 11: Find all texts (모든 텍스트 찾기)
soup.text # List
# '\\n A web page\\n \\n \\n Joel Grus\\n Data Science\\n 30\\n \\n'
first_paragraph = soup.find('p') # 또는 soup.p
print(first_paragraph) # 첫 번째 <p> 태그의 내용을 출력합니다.
print(type(first_paragraph)) # 결과의 타입을 출력합니다.
<p id="author">Joel Grus</p>
<class 'bs4.element.Tag'>
- 첫 번째 <p> 태그의 내용이 들어 있을 것이며, <p> 태그 내용의 타입은 BeautifulSoup의 특수한 타입인 Tag 입니다.
first_paragraph_text = soup.p.text
first_paragraph_text
# 'Joel Grus'
first_paragraph_words = soup.p.text.split()
first_paragraph_words
# ['Joel', 'Grus']
- 첫 번째 <p> 태그의 텍스트 내용을 추출한 후, .split() 메서드를 사용하여 공백을 기준으로 단어 단위로 분할합니다.
first_paragraph_id = soup.p['id'] # 'id' 속성이 없으면 KeyError를 발생시킵니다.
first_paragraph_id
#type(soup.p)
# Result: 'author'
- soup에서 첫 번째 <p> 태그의 id 속성 값을 가져와서 first_paragraph_id 변수에 할당합니다.
- 만약 해당 태그에 id 속성이 없다면 KeyError가 발생합니다.
first_paragraph_id2 = soup.p.get('id') # 'id' 속성이 없으면 None을 반환합니다.
print(first_paragraph_id2)
# Result: 'author'
- soup에서 첫 번째 <p> 태그의 id 속성 값을 가져와서 first_paragraph_id2 변수에 할당합니다.
- 만약 해당 태그에 id 속성이 없다면 None을 반환합니다.
all_paragraphs = soup.find_all('p') # 또는 soup('p')로도 가능합니다.
print(all_paragraphs)
[<p id="author">Joel Grus</p>, <p id="subject">Data Science</p>]
- soup에서 모든 <p> 태그를 찾아서 all_paragraphs 변수에 할당합니다.
- 그 결과는 리스트 형태로 반환됩니다.
soup('p')
# [<p id="author">Joel Grus</p>, <p id="subject">Data Science</p>]
soup('p', {'id':'subject'})
# [<p id="subject">Data Science</p>]
- id 속성이 'subject'인 모든 <p> 태그를 찾는 예시입니다.
- 결과는 해당 조건에 맞는 <p> 태그들을 포함하는 리스트로 반환합니다.
- soup에서 id 속성이 'subject' 인 모든 <p> 태그를 찾아 반환합니다.
- 두 번째 인자로는 딕셔너리를 사용하여 원하는 속성과 그 값의 조건을 지정합니다.
paragraphs_with_ids = [p for p in soup('p') if p.get('id')]
paragraphs_with_ids
[<p id="author">Joel Grus</p>, <p id="subject">Data Science</p>]
- BeautifulSoup 객체 soup에서 모든 <p> 태그를 찾은 후, 리스트 컴프리헨션을 사용하여 id 속성을 가진 태그들만 모아서 paragraphs_with_ids 리스트에 저장합니다.
- 결과는 id 속성을 가진 <p> 태그들의 리스트로 반환됩니다.
important_paragraphs = soup('p', {'class': 'important'})
# [<p id="author">Joel Grus</p>, <p id="subject">Data Science</p>]
- soup에서 클래스가 'important'인 모든 <p> 태그를 찾아 반환합니다.
- 두 번째 인자로는 딕셔너리를 사용하여 원하는 클래스와 그 값의 조건을 지정합니다.
# 네이버 홈페이지의 HTML을 가져옵니다.
html = requests.get("<http://www.naver.com>").text
# HTML을 BeautifulSoup으로 파싱합니다.
soup = BeautifulSoup(html, 'html5lib')
- requests 모듈을 사용하여 네이버 홈페이지에 GET 요청을 보내고, 해당 페이지의 HTML을 가져옵니다.
- 그 후, BeautifulSoup을 사용하여 HTML을 파싱하여 객체로 저장합니다.
- 이렇게 하면 웹 페이지의 구조를 탐색하고 원하는 정보를 추출합니다.
# 경고: 만약 <span>이 여러 개의 <div> 안에 있는 경우, 같은 <span>을 여러 번 반환할 수 있습니다.
# 만약 그렇다면 좀 더 똑똑하게 처리해야 합니다.
spans_inside_divs = [span # <span>을 각각 리스트에 추가합니다.
for div in soup('div') # 페이지의 각 <div>에 대해
for span in div('span')] # 그 안에 있는 각 <span>을 찾습니다.
- soup에서 모든 <div> 태그를 찾은 후, 각 <div> 태그 안에 있는 모든 <span> 태그를 찾아 리스트에 추가합니다.
- 그러나 만약 <span> 태그가 여러 개의 <div> 태그 안에 존재하는 경우, 동일한 <span>을 여러 번 반환합니다.
spans_inside_divs
- spans_inside_divs 변수에는 모든 <div> 태그 안에 있는 모든 <span> 태그가 포함된 리스트가 저장되어 있을 것입니다.
- 이 리스트는 각 <div> 태그에 대해 그 안에 있는 모든 <span> 태그를 포함하고 있습니다.
- 이 리스트를 출력하면 해당 정보를 확인합니다.
'📈 Data Engineering > 📝 Data Mining' 카테고리의 다른 글
| [Data Mining] Gradient Descent (경사 하강법) (0) | 2024.07.23 |
|---|---|
| [Data Mining] Statistics (통계학) (0) | 2024.07.14 |
| [Data Mining] Linear Algebra (선형대수) (0) | 2024.07.09 |
| [Data Mining] Introduction to Numpy part.2 (0) | 2024.07.05 |
| [Data Mining] Introduction to Numpy part.1 (0) | 2024.06.26 |