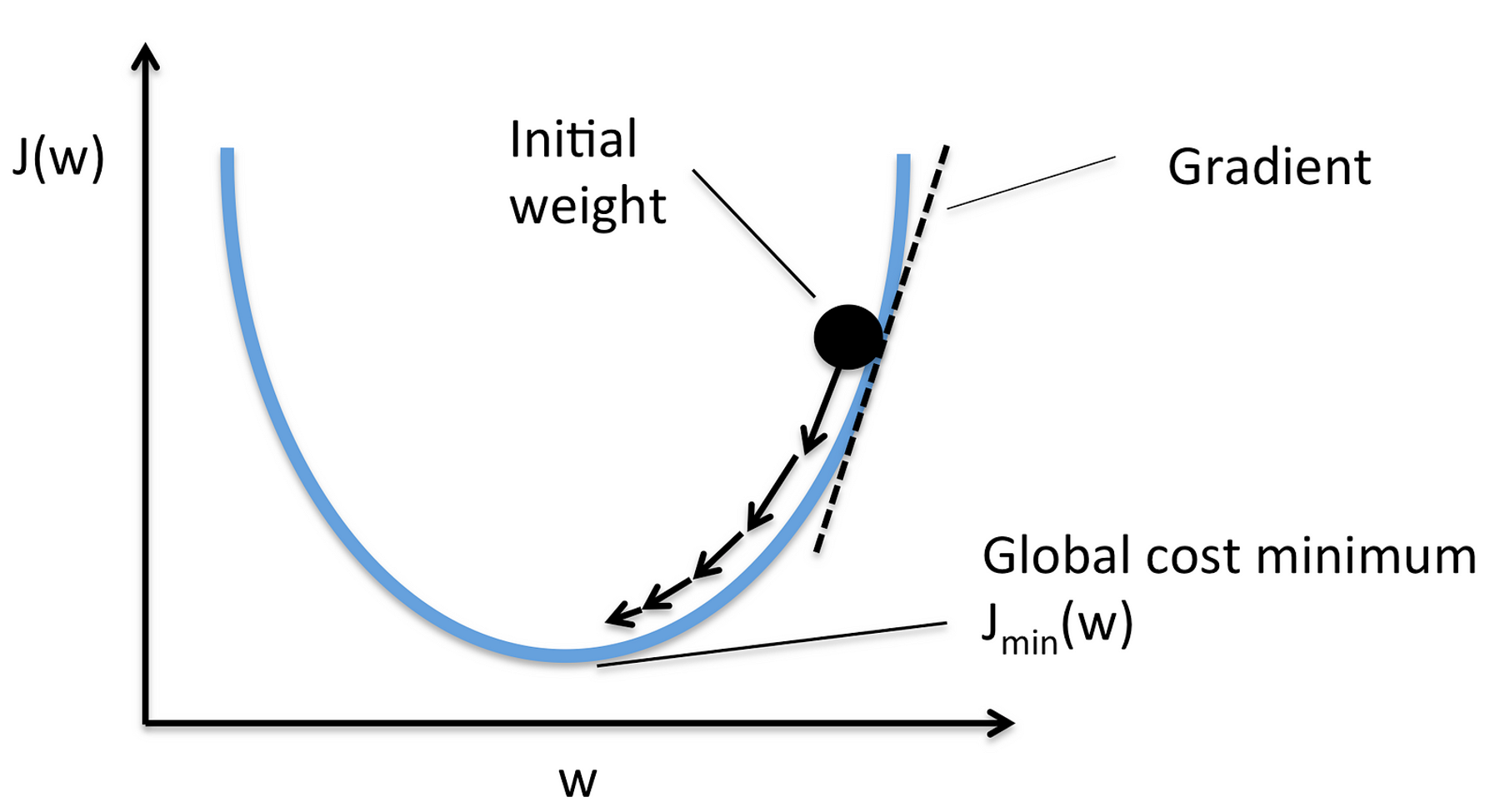
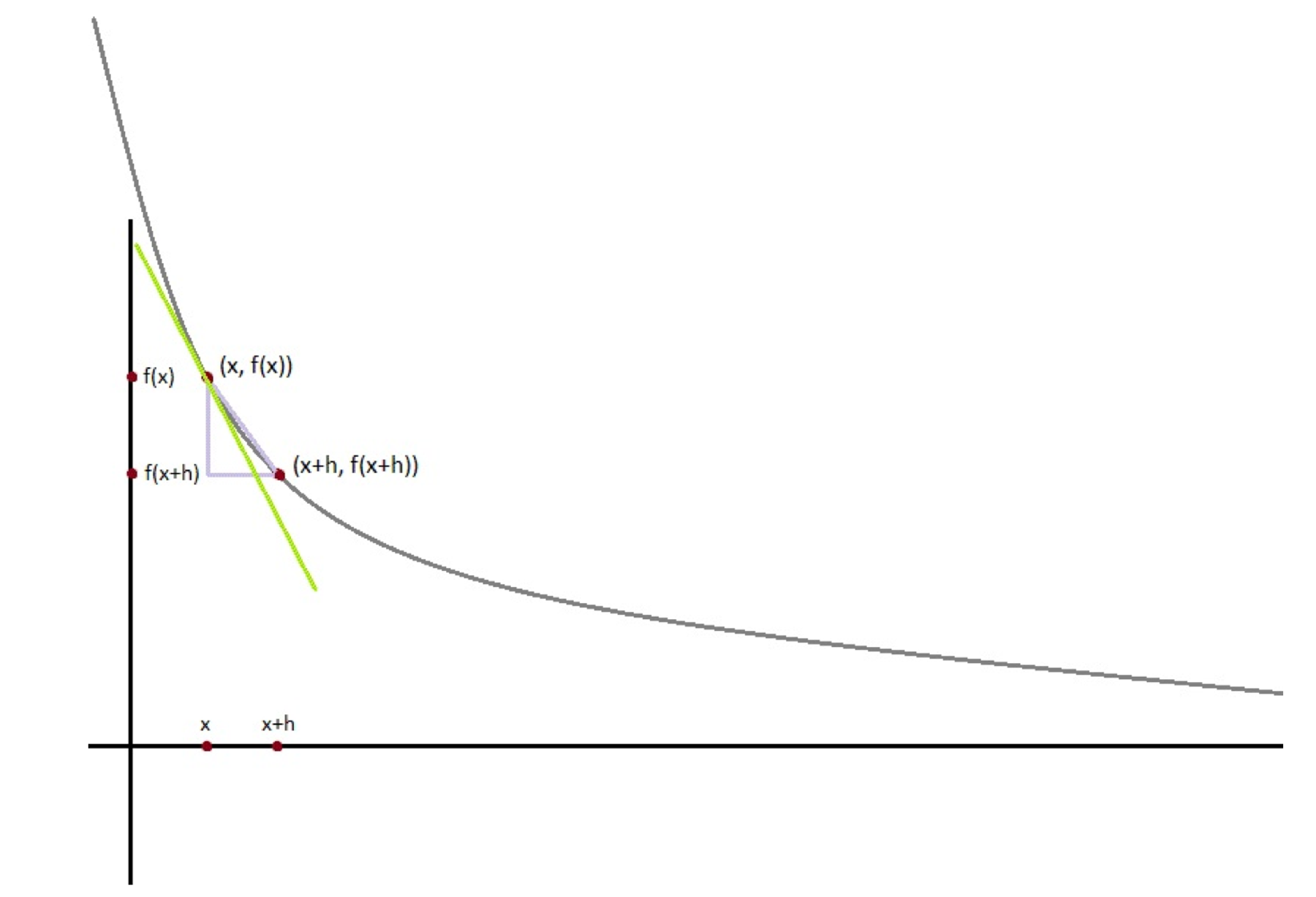
f가 한 변수의 함수라면, 점 x에서의 도함수는 우리가 x로 아주 작은 변화를 만들 때 f(x)가 어떻게 변하는지 측정합니다.
defdifference_quotient(f, x, h):
# 함수 f의 x에서의 차분 근사값을 계산합니다.return (f(x + h) - f(x)) / h
주어진 함수 f에 대해, 특정 점 x에서의 도함수(미분값)를 근사하는 방법을 구현합니다.
함수 f, 점 x, 그리고 아주 작은 값 h를 입력으로 받아, f의 x에서의 기울기를 근사화
함수의 정의에 따라, (f(x + h) - f(x)) / h 계산은 x에서 h만큼 변화했을 때, 함수 f의 출력값이 얼마나 변하는지를 측정합니다.
이는 x에서 함수 f의 즉시 변화율이나 기울기를 근사하는 것과 동일합니다. h가 0에 가까워질수록, 이 근사값은 f의 x에서의 실제 도함수 값에 가까워집니다.
도함수는 함수의 변화율을 나타내며, 함수 그래프 상의 특정 점에서의 접선의 기울기에 해당합니다.
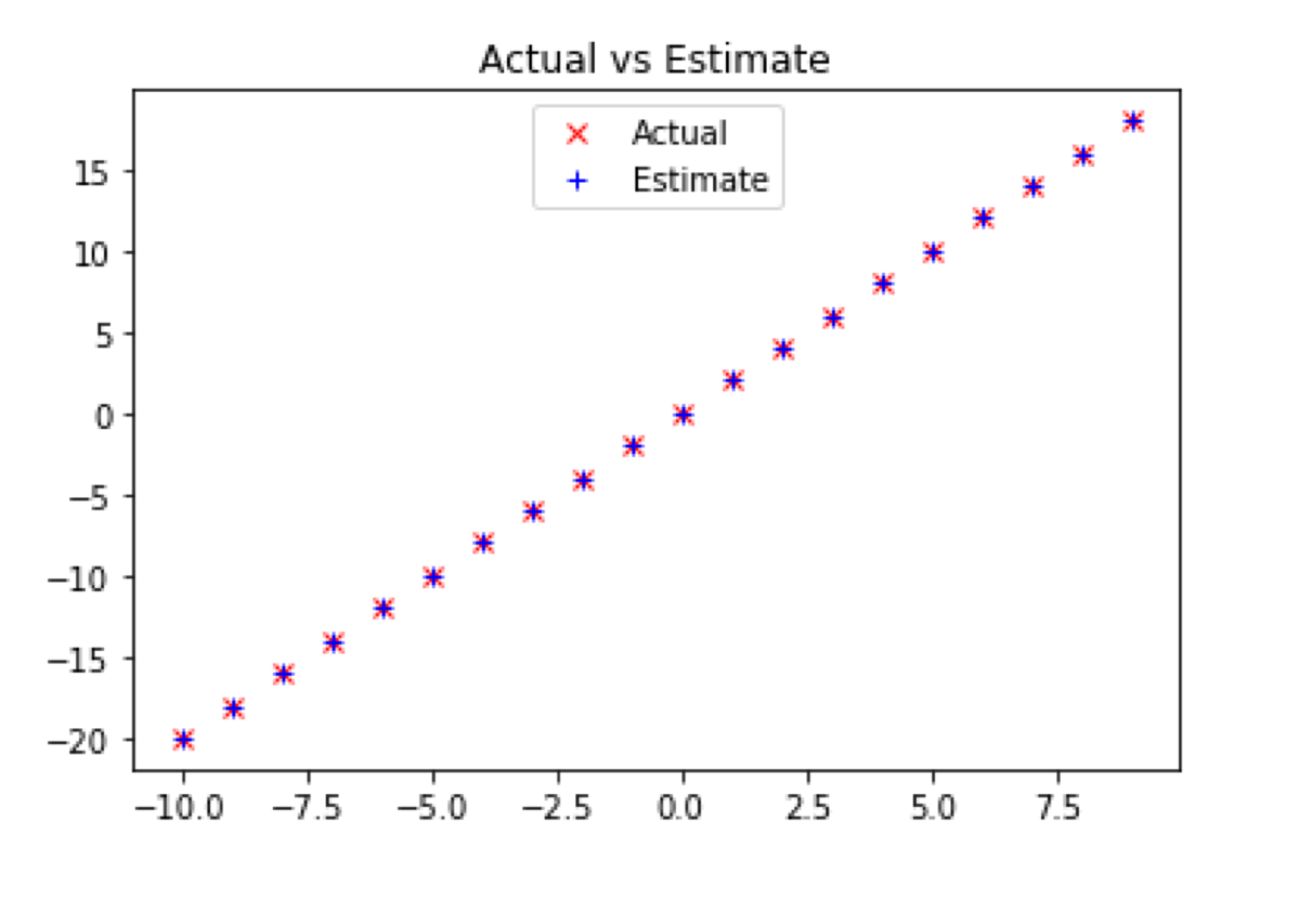
defplot_estimated_derivative():# 실제 함수 정의defsquare(x):"""x의 제곱을 반환"""return x * x
# 실제 도함수(미분값) 정의defderivative(x):"""square 함수의 도함수인 2x를 반환"""return2 * x
# 근사 도함수 계산을 위한 람다 함수
derivative_estimate = lambda x: difference_quotient(square, x, h=10)
# 실제 도함수와 근사 도함수를 그래프로 비교import matplotlib.pyplot as plt
x = range(-10, 10)
# 실제 도함수 그래프 (빨간색 x로 표시)
plt.plot(x, list(map(derivative, x)), 'rx', label='Actual')
# 근사 도함수 그래프 (파란색 +로 표시)
plt.plot(x, list(map(derivative_estimate, x)), 'b+', label='Estimate')
# 범례 위치 설정 (9는 상단 중앙을 의미)
plt.legend(loc=9)
plt.title('Actual vs Estimate')
plt.show()
square 함수는 입력값의 제곱을 반환하며, 이 함수의 실제 도함수는 2x입니다.
근사 도함수는 difference_quotient 함수를 사용하여 계산되며, 여기서 h는 근사 계산에 사용되는 매우 작은 값입니다.
%matplotlib inline
plot_estimated_derivative()
자동 미분은 그라데이션을 올바르게 계산합니다. (automatic differentiation computes the gradient correctly)
!pip install autograd
# autograd 라이브러리를 사용하여 자동 미분을 수행하는 예제입니다.import autograd.numpy as np
from autograd import grad
# f라는 함수를 정의합니다. 이 함수는 입력 x에 대해 x^2의 값을 반환합니다.deff(x):return x * x
# f 함수의 도함수(미분 함수)를 자동으로 생성합니다.
df_dx = grad(f)
# 생성된 도함수를 이용하여 x=5.0일 때의 도함수 값(미분 값)을 계산하고 출력합니다.# f(x) = x^2의 도함수는 2x이므로, x=5일 때 도함수의 값은 10입니다.print(df_dx(5.0))
# 시그모이드 함수를 정의합니다. 시그모이드 함수는 일반적으로# 머신러닝과 딥러닝에서 활성화 함수로 많이 사용됩니다.defsigmoid(x):return1./(1. + np.exp(-x))
# 시그모이드 함수의 도함수를 자동으로 생성합니다.
dsigmoid_dx = grad(sigmoid)
# 생성된 도함수를 이용하여 x=0일 때의 도함수 값(미분 값)을 계산하고 출력합니다.# 시그모이드 함수의 미분 값은 sigmoid(x) * (1 - sigmoid(x))이고,# x=0일 때, 이 값은 0.25입니다.print(dsigmoid_dx(0.))
# 시그모이드 함수의 x=0일 때의 함수 값 자체를 계산하고 출력합니다.# 시그모이드 함수는 x=0에서 0.5의 값을 가집니다.print(sigmoid(0))
10.00.250.5
import autograd.numpy as np
from autograd import grad
# 함수 정의: h(x, y) = x^2 + ydef h(x, y):
return x**2 + y
# x에 대한 h의 편미분 함수 생성dh_dx = grad(h, argnum=0)
# y에 대한 h의 편미분 함수 생성dh_dy = grad(h, argnum=1)
# x=2, y=2에서의 편미분 값 계산 및 배열로 반환np.array([dh_dx(2., 2.), dh_dy(2., 2.)])
array([4., 1.])
자동 미분을 사용하여 x=0.5에서 f(x) = exp(2x) / (1 + sin(x^2))
함수를 다음과 같이 일련의 기본 연산으로 분해할 수 있습니다:
Step1: Let z1 = 2x
Step2: Let z2 = exp(z1)
Step3: Let z3 = x^2Step4: Let z4 = sin(z3)
Step5: Let z5 = 1 + z4
Step6: Let z6 = z2 / z5
다시 각 단계에서 x에 대한 함수와 그 도함수의 값을 추적합니다.
먼저 그 자체에 대한 출력의 도함수를 1로 설정한 다음 연쇄법칙을 사용하여
x에 대한 각 중간변수의 도함수를 계산합니다.
dz1/dx = 2
dz2/dx = dz1/dx * exp(z1)
dz3/dx = 2x
dz4/dx = cos(z3) * dz3/dx
dz5/dx = dz4/dx
dz6/dx = (dz2/dx * z5 - z2 * dz5/dx) / z5^2
Numerical gradient
f가 많은 변수의 함수일 때, f는 여러 개의 편미분을 가지며, 각각은 입력 변수 중 하나에서 작은 변화를 만들 때 f가 어떻게 변하는지 나타냅니다.
우리는 다른 변수들을 고정한 채로 i번째 변수만의 함수로 취급하여 i번째 편미분을 계산합니다.
defpartial_difference_quotient(f, v, i, h):
# 주어진 함수 f의 i번째 변수에 대한 중앙 차분법을 사용하여 편미분을 근사하는 함수# v에서 i번째 변수에만 h를 더합니다.
w = [v_j + (h if j == i else0)
for j, v_j in enumerate(v)]
# w와 v에서의 함수 값의 차이를 h로 나누어 편미분을 근사합니다.return (f(w) - f(v)) / h
함수 f의 i번째 변수에 대한 편미분을 근사하는 중앙 차분법을 사용합니다.
𝑣에서의 i번째 변수에만 작은 변화 h를 추가한 w를 만듭니다.
w와 v에서의 함수 값의 차이를 h로 나누어 편미분을 근사합니다.
defestimate_gradient(f, v, h=0.00001):
# 주어진 함수 f의 그래디언트(기울기)를 중앙 차분법을 사용하여 근사하는 함수# 각 변수에 대해 partial_difference_quotient 함수(중앙 차분법)를 사용하여 그래디언트를 계산.return [partial_difference_quotient(f, v, i, h)
for i, _ in enumerate(v)]
import numpy as np
defestimate_gradient_np(f, v, h=0.00001):# f: 미분하고자 하는 다변수 함수# v: 함수 f에 대한 입력 벡터# h: 미분 계산을 위한 아주 작은 값, 기본값은 0.00001# np.eye(v.shape[0])는 v의 차원에 맞는 단위행렬을 생성합니다.# v + h * np.eye(v.shape[0])는 각 변수에 대해 h만큼 증가시킨 새로운 벡터들을 생성합니다.# np.apply_along_axis는 생성된 각 벡터에 대해 함수 f를 적용합니다.
gradients = np.apply_along_axis(f, 1, v + h * np.eye(v.shape[0])) - f(v)
# 계산된 차이를 h로 나누어 각 변수에 대한 함수 f의 그래디언트를 추정합니다.return gradients / h
v + h * np.eye(v.shape[0]) → Numpy Broadcasting (v1+h …. vn)
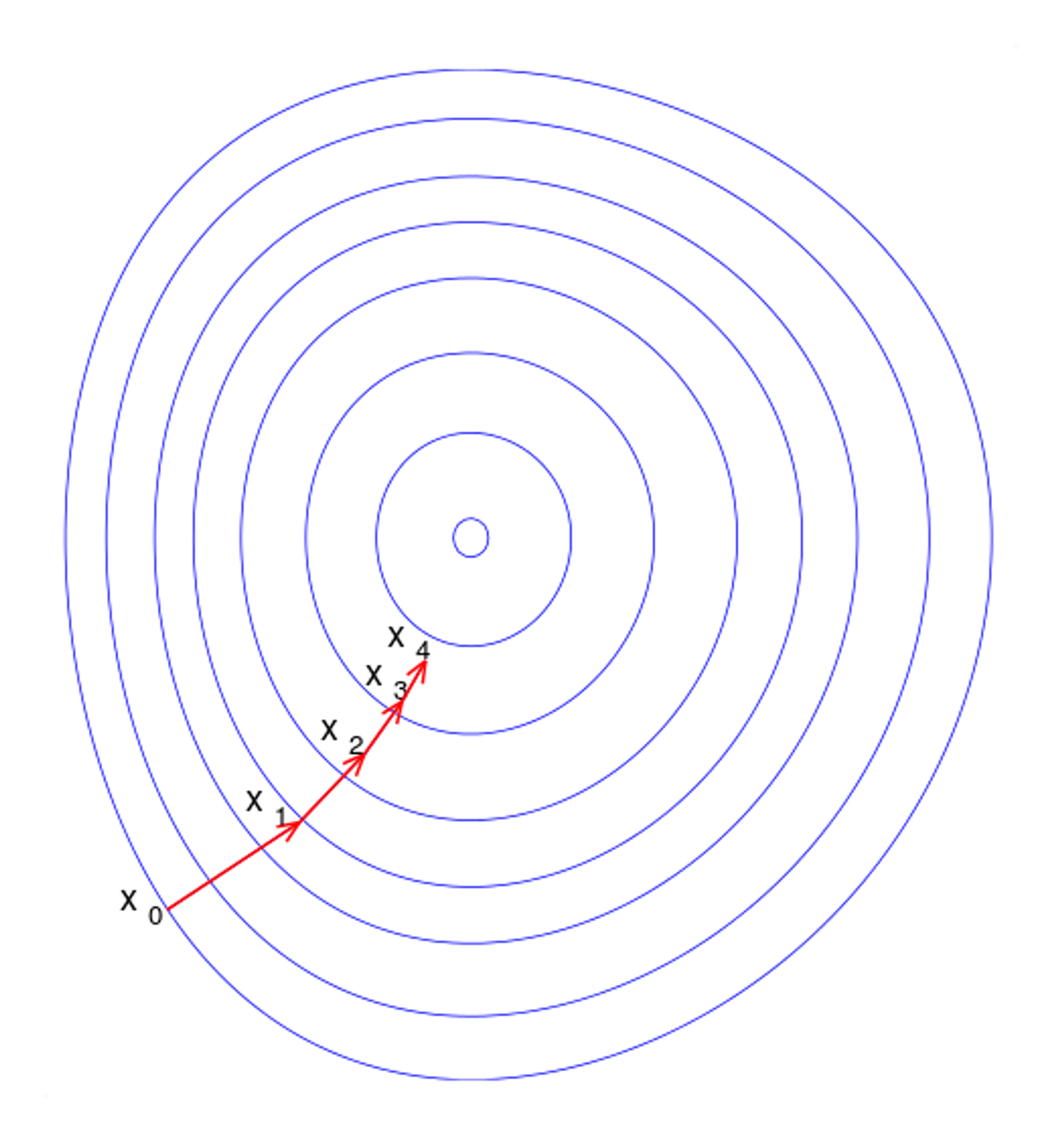
(기울기 하강법) 그래디언트를 사용하여 모든 3차원 벡터 중 최소값을 찾아봅시다. 우리는 임의의 시작점을 선택한 다음 그래디언트가 매우 작은 지점에 도달할 때까지 그래디언트의 반대 방향으로 아주 작은 단계를 밟을 것입니다
defstep(v, direction, step_size):"""move step_size in the direction from v"""return [v_i + step_size * direction_i
for v_i, direction_i inzip(v, direction)]
step 함수는 주어진 방향 direction으로 step_size만큼 이동하는 기능
v: 현재 위치를 나타내는 벡터.
direction: 이동하고자 하는 방향을 나타내는 벡터. 이 방향은 보통 목표 함수의 기울기에 의해 결정됩니다.
step_size: 한 번에 이동할 거리. 즉, 이동의 크기를 결정합니다.
반환값: 새로운 위치를 나타내는 벡터.
defsum_of_squares_gradient(v):
return [2 * v_i for v_i in v]
주어진 벡터 v에 대해 sum_of_squares 함수의 기울기를 계산
매개변수:v: 기울기를 계산하고자 하는 위치를 나타내는 벡터.반환값:
sum_of_squares 함수의 v에서의 기울기 벡터. 각 요소는 2 * v_i로, sum_of_squares 함수는 각 변수의 제곱의 합으로 이루어져 있기 때문에, 그 미분값은 2 * v_i가 됩니다.
defstep(v, direction, step_size):"""v에서 direction 방향으로 step_size만큼 이동"""return [v_i + step_size * direction_i
for v_i, direction_i inzip(v, direction)]
defsum_of_squares_gradient(v):"""v의 제곱합 함수의 기울기(gradient) 계산"""return [2 * v_i for v_i in v]
step 함수
현재 위치 v에서 주어진 direction 방향으로 step_size만큼 이동한 새로운 위치를 계산합니다.
v: 현재 위치를 나타내는 벡터입니다.
direction: 이동할 방향을 나타내는 벡터입니다. 보통 최적화하려는 함수의 기울기(gradient) 반대 방향이 됩니다.
step_size: 한 번에 이동할 거리를 나타냅니다. 이 값이 너무 크면 최적점을 넘어서게 되고, 너무 작으면 최적화 과정이 매우 느려질 수 있습니다.반환값: 새로운 위치를 나타내는 벡터입니다. 이는 v의 각 요소에 direction의 해당 요소와 step_size를 곱한 값을 더해서 계산됩니다.
sum_of_squares_gradient 함수
주어진 벡터 v에 대해 제곱합 함수의 기울기를 계산합니다. 제곱합 함수는 모든 요소의 제곱을 더한 것이며, 이 함수는 최적화에서 자주 사용되는 간단한 예시입니다.
파라미터:v: 기울기를 계산할 벡터입니다.반환값: 제곱합 함수의 기울기를 나타내는 벡터입니다. 제곱합 함수의 각 변수에 대한 편미분은 2 * v_i이므로, 결과 벡터는 입력 벡터 v의 각 요소에 2를 곱한 값으로 구성됩니다.
이 두 함수는 경사하강법(gradient descent) 알고리즘의 기본 구성 요소입니다. 경사하강법은 함수의 최소값을 찾기 위해 기울기(또는 그래디언트) 정보를 사용하여 반복적으로 현재 위치를 업데이트하는 방법입니다.
sum_of_squares_gradient 함수는 최적화하려는 함수의 기울기를 계산하고, step 함수는 이 기울기를 사용하여 다음 위치로 이동합니다.
print("using the gradient")
# try range(n) n = 1,2,3,4,5,...
v = [random.randint(-10,10) for i inrange(2)] # 임의의 초기 벡터 v 생성
tolerance = 0.0000001# 수렴 기준 값 (10**-5, 10의 -5승 까지)whileTrue:
#print(v, sum_of_squares(v))
gradient = sum_of_squares_gradient(v) # v에서의 기울기 계산
next_v = step(v, gradient, -0.01) # 음의 기울기 방향으로 한 걸음 이동if distance(next_v, v) < tolerance: # 이전 v와 현재 v의 거리가 tolerance보다 작으면 중단break
v = next_v # 아니면 계속print("minimum v", v) # 최소화된 v 출력print("minimum value", sum_of_squares(v)) # 최소화된 값 출력
v: 최적화를 시작할 임의의 벡터입니다. 여기서는 2차원 벡터를 사용합니다.
tolerance: 알고리즘이 수렴했다고 판단하는 기준입니다. v의 연속된 두 값의 차이가 이 값보다 작으면 반복을 멈춥니다.
while True 루프: 알고리즘이 수렴 조건을 만족할 때까지 반복합니다.
gradient = sum_of_squares_gradient(v): 현재 위치 v에서 목적 함수의 기울기를 계산합니다. → Gradient Step Size 만큼 걸어다면 다음 Step Size
next_v = step(v, gradient, -0.01): 계산된 기울기의 반대 방향(최소화 방향)으로 작은 걸음(-0.01)을 이동하여 새로운 위치를 계산합니다.
if distance(next_v, v) < tolerance: 새로운 위치와 이전 위치 사이의 거리가 tolerance보다 작으면, 즉 변화가 충분히 작아 수렴했다고 판단하면 반복을 멈춥니다.
최종적으로, 수렴한 위치 v와 그 때의 목적 함수 값 sum_of_squares(v)를 출력합니다.
using the gradient
minimum v [-4.157730989669425e-06, -2.7718206597796163e-06]minimum value 2.4969716752438604e-11
Choosing the Right Step Size (or Learning rate)
올바른 스텝 크기(또는 학습 속도) 선택
gradient에 역행하여 움직일 수 있는 근거는 분명하지만, 얼마나 멀리 움직일 것인지는 명확하지 않습니다. 실제로 올바른 스텝 크기를 선택하는 것은 과학이라기보다는 예술에 가깝습니다. 인기 있는 옵션은 다음과 같습니다:
고정 스텝 크기 사용 (Using a fixed step size)
시간이 지남에 따라 단계 크기가 점차 축소됨 (Gradually shrinking the step size over time)
각 단계에서 목적 함수의 값을 최소화하는 단계 크기 선택 (At each step, choosing the step size that minimizes the value of the objective function)
마지막은 최적인 것처럼 들리지만 실제로는 비용이 많이 드는 계산입니다. 우리는 다양한 단계 크기를 시도하고 목적 함수의 값이 가장 작은 단계를 선택함으로써 그 근사치를 구할 수 있습니다.
Experiment with various learning rates (다양한 Learning Rate로 실험)
# in class, changes lr = 10, 1.1, 1, 0.1, 0.01# 10 : diverge# 1.1: diverge# 1: oscilliating# 0.1: good pace# 0.01 : two slow
import numpy as np
import matplotlib.pyplot as plt
defsum_of_squares_gradient_np(v):"""제곱합 함수의 그래디언트를 계산합니다."""return2 * v
defgradient_descent(gradient_f, init_x, lr=0.01, step_num=10000, tolerance=0.0000001):"""그래디언트 하강법을 사용해 최소값을 찾습니다."""
x = init_x
x_history = []
for i inrange(step_num):
x_history.append(x.copy())
x_prev = x.copy()
x -= lr * gradient_f(x) # 그래디언트 스텝if np.linalg.norm(x - x_prev) < tolerance: # 수렴 조건breakreturn x, x_history
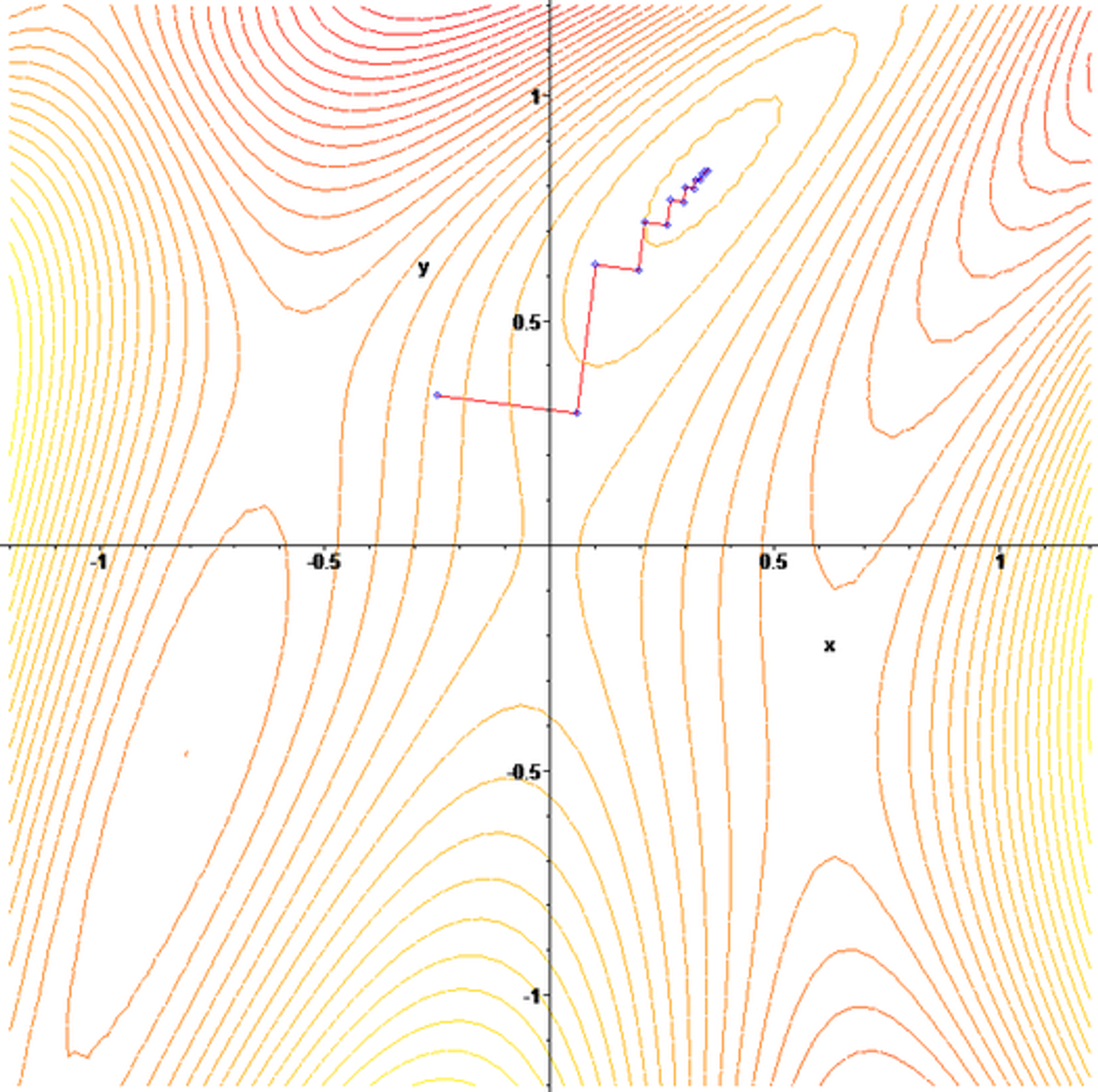
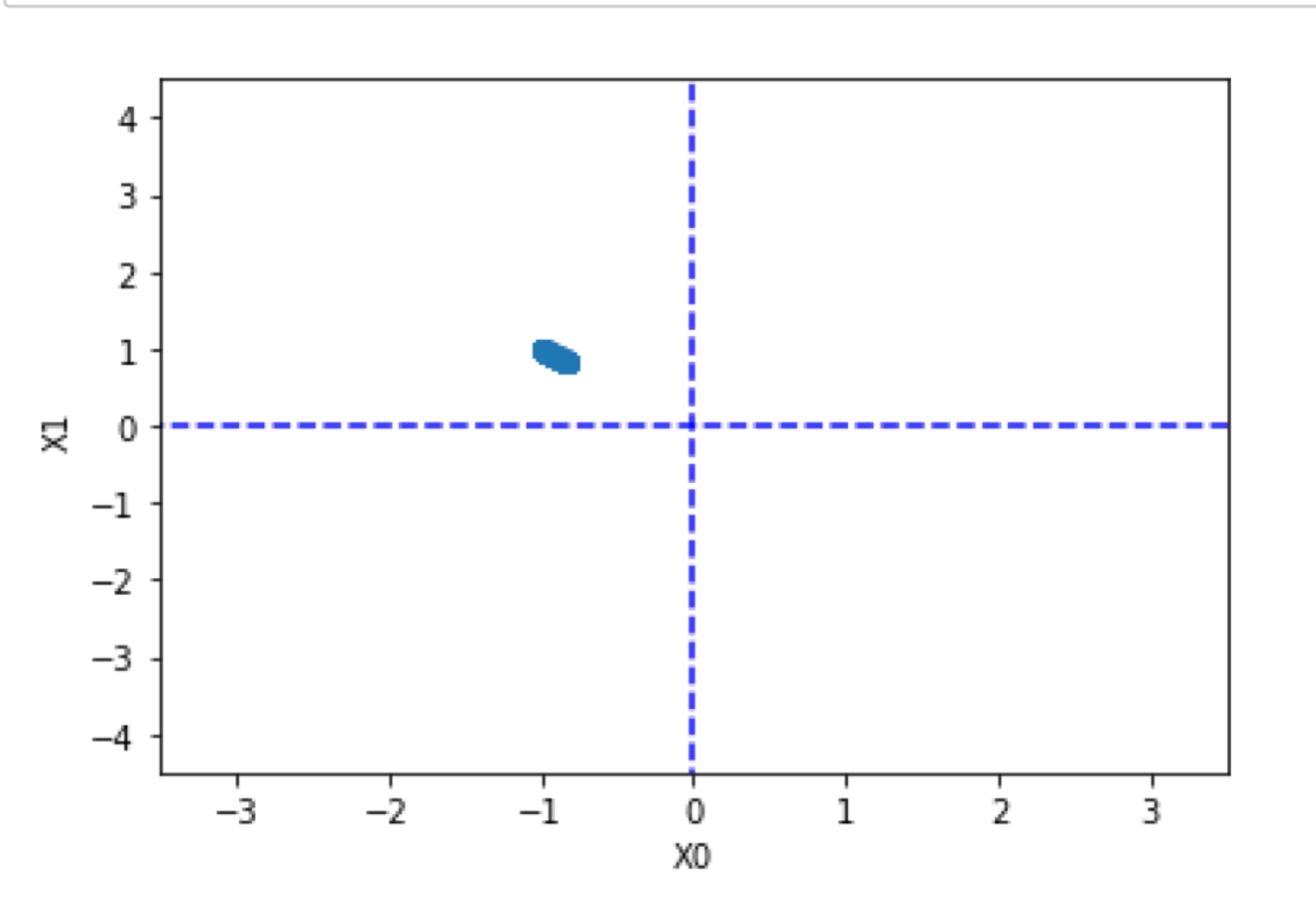
init_x = np.array([-1.0, 1.0])
lr = 1.1# 학습률, # try with 10, 1.1, 1, 0.1, 0.01
step_num = 100
x, x_history = gradient_descent(sum_of_squares_gradient_np, init_x, lr=lr, step_num=step_num)
# 시각화
plt.plot( [-5, 5], [0,0], '--b')
plt.plot( [0,0], [-5, 5], '--b')
x_history = np.array(x_history)
plt.plot(x_history[:,0], x_history[:,1], 'o')
plt.xlim(-3.5, 3.5)
plt.ylim(-4.5, 4.5)
plt.xlabel("X0")
plt.ylabel("X1")
plt.axis('equal')
plt.show()
이 코드는 초기 점(init_x)에서 시작하여 제곱합 함수의 최소값을 찾기 위한 경로를 시각화합니다.
경사 하강법 함수(gradient_descent)는 주어진 그래디언트 함수(gradient_f), 초기 점(init_x), 학습률(lr), 최대 스텝 수(step_num), 그리고 수렴 기준(tolerance)을 인자로 받아 최소값을 찾는 과정을 수행합니다.
학습률(lr)은 경사 하강법에서 매우 중요한 하이퍼파라미터입니다. 너무 크면 발산할 수 있고, 너무 작으면 수렴이 매우 느려질 수 있습니다.
이 예제에서 lr 값을 다양하게 변경해보며 그 영향을 시각적으로 관찰할 수 있습니다.
x -= lr * gradient_f(x) → x의 Gradient Function (Gradient의 반대방향으로 걷는다.)
(Out of function domain) 특정 스텝 크기로 인해 함수에 대한 입력이 잘못되었습니다.
따라서 잘못된 입력에 대해 무한대를 반환하는 "안전 적용" 함수를 만들어야 합니다.
defsafe(f):"""f 함수를 안전하게 실행하는 새로운 함수를 반환한다."""defsafe_f(*args, **kwargs):try:
return f(*args, **kwargs) # f를 실행해봄 -> 모든 인자, keyword & argumentexcept:
returnfloat('inf') # 예외가 발생하면 무한대를 반환return safe_f
함수 f 를 받아, 해당 함수를 실행할 때 예외가 발생하면 프로그램이 중단되지 않고 대신 무한대(float('inf'))를 반환하는 새로운 함수 safe_f 를 반환합니다.
Putting It All Together
일반적인 경우에는 최소화하려는 target_fn이 있고, gradient_fn도 있습니다.
예를 들어 target_fn은 모델의 오류를 매개변수의 함수로 나타낼 수 있으며, 오류를 가능한 작게 만드는 매개변수를 찾고자 할 수 있습니다.
defminimize_batch(target_fn, gradient_fn, theta_0, tolerance=0.000001):"""경사 하강법을 사용하여 목표 함수를 최소화하는 theta를 찾습니다."""# tolerance -> f값이 이것보다 낮아지면 끝.# 각 단계 크기를 설정합니다.
step_sizes = [100, 10, 1, 0.1, 0.01, 0.001, 0.0001, 0.00001]
# theta를 초기 값으로 설정합니다.
theta = theta_0
# target_fn의 안전 버전을 만듭니다.
target_fn = safe(target_fn)
# 최소화할 값을 설정합니다.
value = target_fn(theta)
whileTrue:
# 현재 theta에서의 기울기를 계산합니다.
gradient = gradient_fn(theta)
# 다음 단계 후보를 생성합니다.
next_thetas = [step(theta, gradient, -step_size)
for step_size in step_sizes]
# 오차 함수를 최소화하는 것을 선택합니다.
next_theta = min(next_thetas, key=target_fn) # target function 최소값 구함
next_value = target_fn(next_theta) # value & next value의 차이# 수렴하는 경우 멈춥니다.ifabs(value - next_value) < tolerance:
return theta
else:
theta, value = next_theta, next_value
def myf(v):
# 주어진 벡터 v의 각 요소와 3, 2 각각을 뺀 후 제곱하여 반환합니다.return (v[0]-3)**2 + (v[1]-2)**2def myf_gradient(v):
# 주어진 벡터 v의 각 요소에 2를 곱하고, 각각에 6 또는 4를 뺀 결과를 리스트로 반환합니다.return [2.0*v[0]-6, 2.0*v[1]-4]# minimize_batch 함수를 호출하여 myf 함수를 최소화합니다.minimize_batch(myf, myf_gradient, [5000., 50.])
[3.0016059738814325, 2.000015426605225]
myf_gradient 함수를 그래디언트로 사용하여 경사 하강법을 수행합니다.
초기 theta 값은 [5000., 50.]으로 설정되어 있습니다.
이 값은 사용자가 문제에 따라 적절하게 설정해야 합니다.
from functools import partial
def f1(x, c):
# 주어진 벡터 x와 상수 벡터 c의 차이를 제곱하여 합산한 결과를 반환합니다.
x = np.array(x)
c = np.array(c)
return np.sum((x - c)**2) # x, c 사이 거리
def f1_gradient(x, c):
# 주어진 벡터 x와 상수 벡터 c에 각각 2를 곱하고, 각각에 상수 벡터 c를 뺀 결과를 반환합니다.
x = np.array(x)
c = np.array(c)
return2*x - 2*c
def numerical_gradient(v, f, h=0.00001):
# 중앙 차분법을 사용하여 주어진 벡터 v에서 함수 f의 그래디언트를 계산합니다.return (np.apply_along_axis(f, 1, v + h * np.eye(len(v))) - f(v)) / h
c = np.array([7,70,7,4])
# f1 함수를 상수 c를 고정시켜 부분 함수로 생성합니다 -> f function에 인자 먼저
f = partial(f1, c=c)
# f1_gradient 함수를 상수 c를 고정시켜 부분 함수로 생성합니다.
gradient_f = partial(f1_gradient, c=c)
# minimize_batch 함수를 호출하여 f를 최소화합니다.# gradient_f를 그래디언트로 사용하여 경사 하강법을 수행합니다.# 초기 theta 값은 [0,0,0,0]으로 설정되어 있습니다.
minimize_batch(f, gradient_f, [0,0,0,0])
f1 함수와 f1_gradient 함수에서는 주어진 벡터 x와 상수 벡터 c에 대해 각각 함수 값을 계산하고 그래디언트를 반환합니다.
functools 모듈의 partial 함수를 사용하여 c를 고정시킨 부분 함수를 생성합니다.
이렇게 생성된 부분 함수들을 minimize_batch 함수의 인수로 전달하여 최적화를 수행합니다.
때로는 함수의 음의 기울기를 최소화함 으로써 함수를 최대화할 수도 있습니다. (해당 음의 기울기를 가짐)
defnegate(f):"""주어진 함수 f에 대해 -f(x)를 반환하는 함수를 반환합니다."""returnlambda *args, **kwargs: -f(*args, **kwargs)
defnegate_all(f):"""리스트를 반환하는 함수 f의 각 결과에 대해 음수를 취한 리스트를 반환하는 함수를 반환합니다."""returnlambda *args, **kwargs: [-y for y in f(*args, **kwargs)] # -y: 반대 - function화defmaximize_batch(target_fn, gradient_fn, theta_0, tolerance=0.000001):# minimize_batch 함수를 호출하여 목표 함수를 최대화하는 theta 값을 찾습니다.# negate 함수를 사용하여 목표 함수를 음수로 변환하고, gradient_fn의 결과를 음수로 변환하는 negate_all 함수를 사용합니다.return minimize_batch(negate(target_fn),
negate_all(gradient_fn),
theta_0,
tolerance)
minimize_batch 함수를 호출하여 주어진 목표 함수를 최대화하는 theta 값을 찾습니다.
maximize_batch 함수는 주어진 목표 함수와 그래디언트 함수를 negate 함수와 negate_all 함수를 사용하여 음수로 변환한 후 minimize_batch 함수에 전달합니다.
Maximizing batch Example
정규 pdf를 최대화하는 변수를 찾습니다.
normal pdf의 도함수는 ... (deriv 가능)
from functools import partial
def normal_pdf(npx, mu, sigma):
# 정규 분포의 확률 밀도 함수를 계산합니다.x = npx[0]
return ((1/(np.sqrt(2*np.pi)*sigma)*np.exp(-(x-mu)**2/(2*sigma**2))))
def numerical_gradient(v, f, h=0.00001):
# 주어진 함수 f의 그래디언트를 중앙 차분법을 사용하여 근사하는 함수입니다.return (np.apply_along_axis(f, 1, v + h * np.eye(len(v))) - f(v)) / h
# normal_pdf 함수에 대한 부분 함수를 생성합니다. mu=1, sigma=1로 고정됩니다.f = partial(normal_pdf, mu=1, sigma=1)
# numerical_gradient 함수에 대한 부분 함수를 생성합니다.gradient_f = partial(numerical_gradient, f=f)
# 초기값을 설정합니다.init_x = np.array([1.])
# maximize_batch 함수를 호출하여 normal_pdf 함수를 최대화합니다.# gradient_f를 그래디언트로 사용하여 경사 하강법을 수행합니다.maximize_batch(f, gradient_f, init_x)
array([1.])
maximize_batch 함수를 사용하여 주어진 함수 normal_pdf를 최대화하는 예제입니다.
주어진 함수 normal_pdf는 정규 분포의 확률 밀도 함수를 계산합니다.
이 함수에 대한 그래디언트는 numerical_gradient 함수를 사용하여 근사합니다.
초기값은 init_x로 설정되어 있습니다. 최종적으로 maximize_batch 함수를 호출하여 최대화된 값을 찾습니다.
확률적 경사 하강법 (Stochastic Gradient Descent)
배치 경사 하강
배치 접근 방식에서 각 그라데이션 단계는 예측을 수행하고 전체 데이터 세트에 대한 그라데이션을 계산해야 하므로 각 단계에 오랜 시간이 걸립니다.
일반적으로 오차 함수는 가산적이며, 이는 전체 데이터 세트에 대한 예측 오차가 단순히 각 데이터 포인트에 대한 예측 오차의 합이라는 것을 의미합니다.
확률적 경사 하강
확률적 경사 하강법은 한 번에 한 점에 대해서만 경사도를 계산합니다(그리고 단계를 밟습니다).
정지 지점에 도달할 때까지 데이터를 반복적으로 순환합니다. 매 주기 동안 우리는 데이터를 무작위 순서로 반복하기를 원할 것입니다.
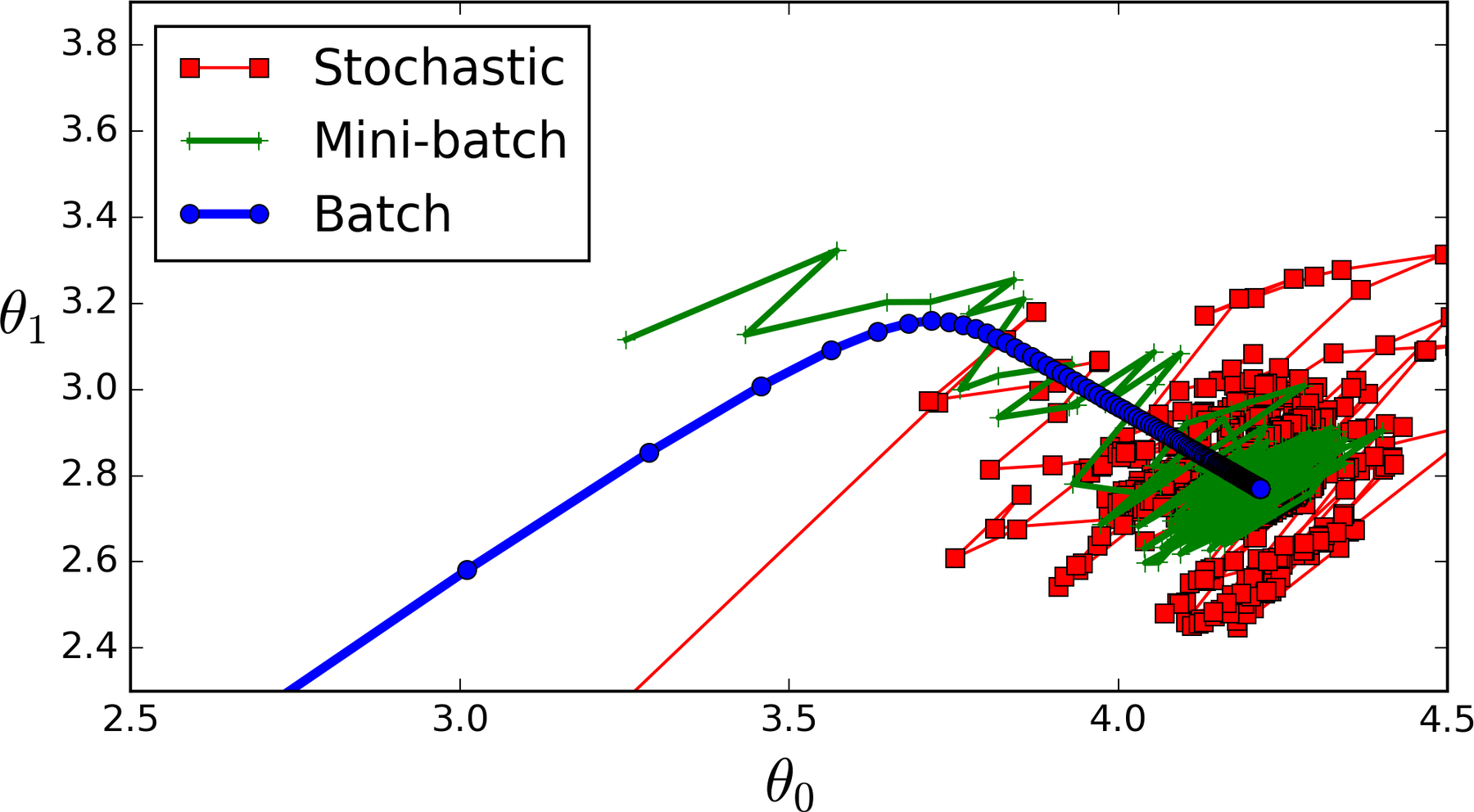
Batch vs SGD vs Mini-batch
전체 Error = 부분 에러의 합 → 1개 씩만 본다.
방법
설명
장점
단점
Batch
전체 학습 데이터셋에서 기울기를 계산함
정확함
데이터 크기가 매우 크면 1) 느림, 2) 메모리에 맞추기 어려움
SGD
하나의 샘플에서 기울기를 계산하고 업데이트
빠름
과도한 오버슈팅 및 수렴이 어려움 (학습률 감소로 해결 가능)
Mini-batch
n개의 샘플의 미니배치에서 기울기를 계산하고 업데이트
분산 감소, 안정적인 업데이트
빠른 계산, (하드웨어/소프트웨어의 강점을 활용). 이것은 신경망을 훈련하는 알고리즘입니다.
NeuralNet Terminology: Epoch
한 epoch는 전체 데이터 세트가 훈련을 위해 소비되는 경우입니다.
import random
defin_random_order(data):# 주어진 데이터를 무작위 순서로 반환하는 제너레이터입니다.# Args: data: 무작위로 반환할 데이터, Returns: 무작위로 섞인 데이터
indexes = [i for i, _ inenumerate(data)] # 데이터의 인덱스 목록을 생성합니다.
random.shuffle(indexes) # 인덱스를 섞습니다.for i in indexes: # 해당 순서대로 데이터를 반환합니다.yield data[i]
in_random_order 제너레이터 함수를 정의합니다. 이 함수는 주어진 데이터를 무작위 순서로 반환합니다.
enumerate 함수를 사용하여 데이터의 인덱스 목록을 생성하고, random.shuffle 함수를 사용하여 인덱스를 섞습니다.
그런 다음 섞인 인덱스에 따라 데이터를 반환합니다.
Understanding SGD Code
x는 Training 데이터 세트입니다. y는 Lavel(또는 클래스) 집합입니다.
def minimize_stochastic(target_fn, gradient_fn, x, y, theta_0, alpha_0=0.01):
data = list(zip(x, y))
theta = theta_0 # 초기 추정값
alpha = alpha_0 # 초기 스텝 크기
min_theta, min_value = None, float("inf") # 현재까지의 최솟값
iterations_with_no_improvement = 0# 100회 반복하여 개선 없으면 종료while iterations_with_no_improvement < 100: # Total Error
value = sum(target_fn(x_i, y_i, theta) for x_i, y_i in data)
if value < min_value:
# 새로운 최솟값을 찾았으면 기억하고 초기 스텝 크기로 돌아감min_theta, min_value = theta, value
iterations_with_no_improvement = 0alpha = alpha_0else:
# 개선이 없다면 스텝 크기를 줄여봄iterations_with_no_improvement += 1alpha *= 0.9# 각 데이터 포인트에 대해 그래디언트 스텝을 취함for x_i, y_i in in_random_order(data):
gradient_i = gradient_fn(x_i, y_i, theta)
theta = vector_subtract(theta, scalar_multiply(alpha, gradient_i))
return min_theta
target_fn: 목표 함수
gradient_fn: 목표 함수의 그래디언트(기울기)
x: 입력 데이터
y: 출력 데이터
theta_0: 초기 theta 값
alpha_0: 초기 학습률 (기본값: 0.01)
Returns: 최대값을 가지는 theta 값
defmaximize_stochastic(target_fn, gradient_fn, x, y, theta_0, alpha_0=0.01):"""
확률적 경사 상승법을 사용하여 목표 함수를 최대화하는 함수입니다.
"""return minimize_stochastic(negate(target_fn),
negate_all(gradient_fn),
x, y, theta_0, alpha_0)
target_fn은 목표 함수이고, gradient_fn은 목표 함수의 그래디언트(기울기) 함수입니다.
x는 입력 데이터, y는 출력 데이터, theta_0은 초기 추정값입니다.
alpha_0은 초기 학습률로, 기본값은 0.01입니다. 최적화된 theta 값을 반환합니다.