Batch Normalization - 배치 정규화
Batch Normalization (배치 정규화)의 개념은 2015년에 제안된 방법입니다.
- 일단, Batch Normalization(배치 정규화)가 주목받는 이유는 다음의 이유들과 같습니다.
- Training(학습)을 빨리 할 수 있습니다. 즉, Training(학습) 속도를 개선하는 효과가 있습니다.
- 초깃값에 크게 의존하지 않는다는 특징이 있습니다.
- 그리고 Overiftting을 억제하는 특징이 있습니다. 즉, Dropout등의 필요성이 감소합니다.
- Batch Normalization(배치 정규화)의 기본 아이디어는 앞에서 말했듯이 각 Layer(층)에서의 Activation Value(활성화 값)이 적당히 분포가 되도록 조정하는 것입니다. 한번 예시를 보겠습니다.
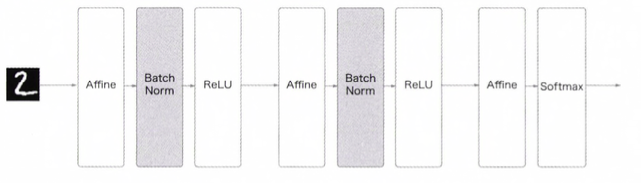 Batch Normalization(배치 정규화)를 사용한 Neural Network(신경망)의 예시
Batch Normalization(배치 정규화)를 사용한 Neural Network(신경망)의 예시
- Batch Normalization(배치 정규화)는 그 이름과 같이 학습시 Mini-Batch를 단위로 정규화를 합니다.
미니 배치(mini-batch)는 데이터셋을 작은 크기의 일부로 나누어 네트워크를 학습시키는 방법입니다.
전체 데이터셋을 한 번에 모두 사용하는 것이 아니라 데이터를 작은 배치로 나누어 각 배치에 대해 순차적으로 학습을 진행합니다.
- 구체적으로는 Mean(평균)이 0, Variance(분산)이 1이 되도록 정규화합니다. 수식으로는 아래의 식과 같습니다.
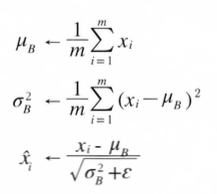
- 위 수식은 Mini-Batch B = B=x1, x2 , ... ,xm m개의 입력 데이터의 집합에 대헤 평균 μB와 분산 σB²을 구합니다.
- 그리고 입력 데이터를 Mean(평균)이 0, Variance(분산)이 1이 되게 Normalization(정규화) 하고, ε은 0으로 나누는 사태를 예방하는 역할을 합니다.
- 또 Batch Normalization(배치 정규화) Layer 마다 이 정규화된 데이터에 고유한 확대 scale와 이동 shift 변환을 수행합니다.
- 수식으로는 아래와 같습니다.

- γ : 확대, β : 이동을 담당합니다.
- 두 값은 처음에는 γ=1, β=0 (1배 확대, 이동 없음=원본 그대로)에서 시작해서 학습하며 적합한 값으로 조정해갑니다.
- 이것이 Batch Normalization(배치 정규화)의 알고리즘입니다. 설명한 내용을 아래의 그래프로 나타낼 수 있습니다.
 Batch Normalization(배치 정규화)의 계산 그래프
Batch Normalization(배치 정규화)의 계산 그래프
Batch Normalization (배치 정규화)의 효과
한번 Batch Normalization(배치 정규화) 계층을 사용한 실험을 한번 Mnist Dataset을 사용하여 Batch Normalization Layer를 사용할때, 사용하지 않을때의 학습 진도가 어떻게 달라지는지를 보겠습니다.
# coding: utf-8
import sys
import os
import numpy as np
import matplotlib.pyplot as plt
sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록 설정
from dataset.mnist import load_mnist # MNIST 데이터셋을 불러오는 함수
from common.multi_layer_net_extend import MultiLayerNetExtend # 다층 신경망 모델 클래스
from common.optimizer import SGD, Adam # 최적화 알고리즘 클래스
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
# 학습 데이터를 줄임
x_train = x_train[:1000]
t_train = t_train[:1000]
max_epochs = 20
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.01
# 가중치 초기화 표준편차 설정 및 학습 함수 정의
def __train(weight_init_std):
# 배치 정규화를 적용한 신경망 모델과 적용하지 않은 신경망 모델 생성
bn_network = MultiLayerNetExtend(input_size=784,
hidden_size_list=[100, 100, 100, 100, 100],
output_size=10,
weight_init_std=weight_init_std,
use_batchnorm=True) # 배치 정규화 사용
network = MultiLayerNetExtend(input_size=784,
hidden_size_list=[100, 100, 100, 100, 100],
output_size=10,
weight_init_std=weight_init_std) # 배치 정규화 미사용
optimizer = SGD(lr=learning_rate) # 확률적 경사 하강법
train_acc_list = [] # 학습 정확도 기록 리스트
bn_train_acc_list = [] # 배치 정규화 적용 학습 정확도 기록 리스트
iter_per_epoch = max(train_size / batch_size, 1)
epoch_cnt = 0
for i in range(1000000000):
batch_mask = np.random.choice(train_size, batch_size) # 무작위 배치 샘플링
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
for _network in (bn_network, network):
grads = _network.gradient(x_batch, t_batch) # 기울기 계산
optimizer.update(_network.params, grads) # 가중치 업데이트
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train) # 정확도 계산
bn_train_acc = bn_network.accuracy(x_train, t_train) # 배치 정규화 적용 정확도 계산
train_acc_list.append(train_acc)
bn_train_acc_list.append(bn_train_acc)
print("epoch:" + str(epoch_cnt) + " | " + str(train_acc) + " - "
+ str(bn_train_acc))
epoch_cnt += 1
if epoch_cnt >= max_epochs:
break
return train_acc_list, bn_train_acc_list
# 그래프 그리기==========
weight_scale_list = np.logspace(0, -4, num=16)
x = np.arange(max_epochs)
for i, w in enumerate(weight_scale_list):
print("============== " + str(i+1) + "/16" + " =============
 Batch Normalization 효과: Batch Normalization가 학습 속도를 높인다.
Batch Normalization 효과: Batch Normalization가 학습 속도를 높인다.
- 보면 Batch Normalization (배치 정규화)가 학습을 빨리 진전시키고 있습니다.
- 그러면 Weight 초깃값의 표준편차를 다양하게 봐꿔가면서 학습 경과를 관찰한 그래프 입니다.
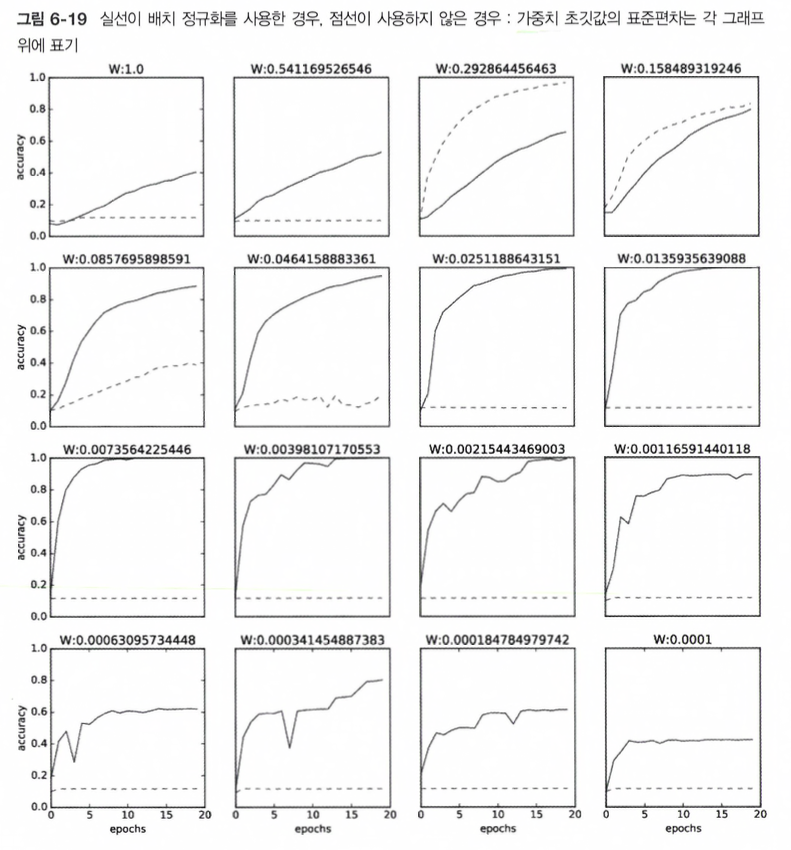
- 거이 모든 경우에서 Batch Normalization(배치 정규화)를 사용할 때의 Training(학습) 속도가 빠른 것으로 나타납니다.
- 실제로 Batch Normalization(배치 정규화)를 이용하지 않는 경우에는 초갓값이 잘 분포되어 있지 않으면 Training(학습)이 전혀 진행되지 않은 모습도 확인할 수 있습니다.
Summary: Batch Normalization(배치 정규화)를 사용하면 Training(학습)이 빨리자면, Weight(가중치) 초깃값에 크게 의존 하지 않아도 된다는 특징이 있습니다.