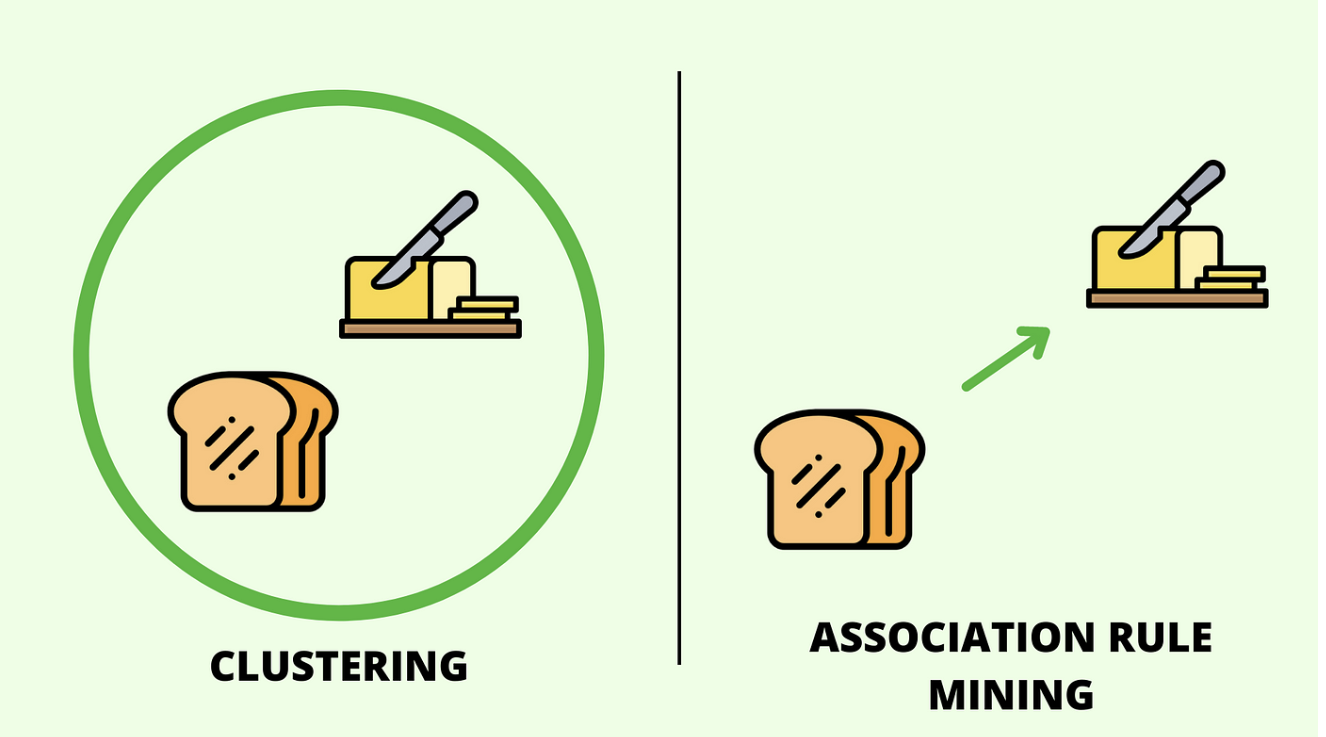
이번에는 연관 규칙 학습 (Association Rule Learning)에 데하여 한번 알아보겠습니다.
연관 규칙 학습은 데이터베이스에서 항목 간의 흥미로운 관계를 찾는 비지도 학습 방법입니다.
이 방법은 특정 항목이 나타날 때 다른 항목이 함께 나타날 확률을 계산하여 유용한 패턴을 도출하는 데 사용됩니다.
주로 Apriori 알고리즘과 FP-Growth 알고리즘이 널리 사용됩니다.
연관 규칙 학습 (Association Rule Learning)의 특징
연관 규칙 학습에 특징들에 데하여 알아보겠습니다.
- 빈발 항목 집합 기반: 연관 규칙 학습은 빈발 항목 집합을 기반으로 유의미한 연관 규칙을 도출합니다. 빈발 항목 집합은 일정 빈도 이상 나타나는 항목들의 집합을 의미합니다.
- 계산 효율성: Apriori와 FP-Growth 알고리즘을 통해 대규모 데이터셋에서도 연관 규칙을 효율적으로 탐색할 수 있습니다.
- 응용 가능성: 연관 규칙 학습은 마케팅, 상품 배치, 추천 시스템 등 다양한 분야에서 유용하게 활용됩니다.
연관 규칙 학습 (Association Rule Learning)의 주요용어
- 항목 (Item): 데이터베이스 내의 단일 항목, 예를 들어 슈퍼마켓에서 특정 상품을 의미합니다.
- 항목 집합 (Itemset): 여러 항목으로 구성된 집합으로, 예를 들어 장바구니에 담긴 여러 상품들이 항목 집합을 구성합니다.
- 거래 (Transaction): 항목 집합을 포함하는 단일 데이터 행을 의미하며, 한 번의 구매 내역이 하나의 거래로 간주됩니다.
- 빈발 항목 집합 (Frequent Itemset): 특정 지지도 기준을 충족하는 항목 집합으로, 예를 들어 자주 함께 구매되는 상품들의 집합입니다.
- 지지도 (Support): 특정 항목 집합이 데이터베이스에서 나타나는 빈도로, 항목 집합의 인기를 나타냅니다.
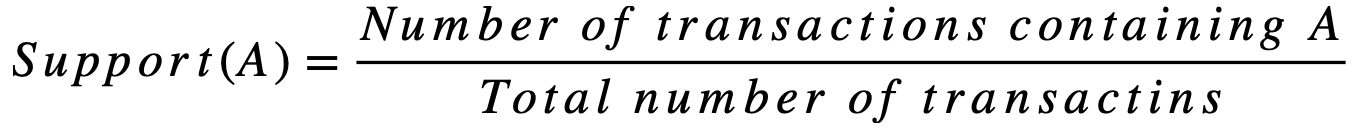
- 신뢰도 (Confidence): 항목 집합 A가 주어졌을 때 항목 집합 B가 발생할 확률로, 연관 규칙의 강도를 나타냅니다.
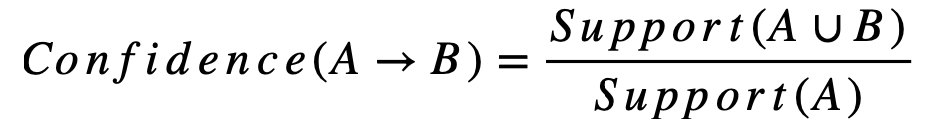
- 향상도 (Lift): 항목 집합 A와 B가 독립적일 때에 비해 실제로 얼마나 더 자주 함께 나타나는지를 나타냅니다. 향상도는 규칙의 유의미성을 평가하는 데 사용됩니다.
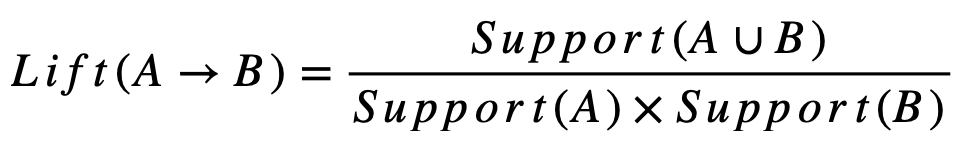
연관 규칙 학습 (Association Rule Learning)의 기본 원리
그러면 연관 규칙 학습의 기본 원리는 어떠한 것들이 있을까요?
빈발 항목 집합 탐색
- 최소 지지도 설정: 분석의 기준이 되는 최소 지지도를 설정하여, 얼마나 자주 등장해야 의미 있는 패턴으로 간주할지를 결정합니다.
- 단일 항목 집합 탐색: 각 단일 항목의 지지도를 계산하고, 최소 지지도를 충족하는 항목을 선택합니다.
- 조합 항목 집합 탐색: 두 개 이상의 항목을 조합하여 새로운 항목 집합을 생성하고, 지지도를 계산합니다. 최소 지지도를 충족하는 항목 집합만을 남기고 나머지를 삭제합니다.
- 반복: 더 이상 최소 지지도를 충족하는 항목 집합이 없을 때까지 이 단계를 반복합니다.
연관 규칙 생성
- 빈발 항목 집합 기반 규칙 생성: 빈발 항목 집합에서 가능한 모든 연관 규칙을 생성합니다. 예를 들어, {A, B}에서 A→B와 B→A를 생성할 수 있습니다.
- 신뢰도와 향상도 계산: 생성된 규칙에 대해 신뢰도와 향상도를 계산하여 규칙의 유의미성을 평가합니다.
- 최소 신뢰도 및 향상도 기준 설정: 최소 신뢰도와 향상도를 설정하여 의미 있는 규칙만을 선택합니다.
연관 규칙 학습 (Association Rule Learning)의 장, 단점
연관 규칙 학습의 장점
- 유용한 패턴 발견: 데이터에서 유용한 패턴과 규칙을 발견하여 비즈니스 전략 수립에 도움을 줄 수 있습니다. 예를 들어, 마케팅 전략이나 상품 배치 등에 활용할 수 있습니다.
- 다양한 응용 분야: 연관 규칙 학습은 마케팅, 추천 시스템, 이상 탐지 등 다양한 분야에서 적용 가능성이 높습니다.
- 단순성과 이해 용이성: 생성된 규칙이 명확하고 쉽게 해석될 수 있어, 비전문가도 쉽게 이해하고 활용할 수 있습니다.
연관 규칙 학습의 단점
- 대규모 데이터셋에서의 계산 복잡성: 대규모 데이터셋에서 빈발 항목 집합을 탐색하는 데 많은 계산이 필요하며, 이로 인해 성능 저하가 발생할 수 있습니다.
- 희소성 문제: 데이터가 희소한 경우 유의미한 규칙을 찾기 어려울 수 있습니다. 이는 데이터가 충분히 큰 경우에만 좋은 결과를 기대할 수 있음을 의미합니다.
- 과적합: 너무 많은 규칙이 생성될 경우, 모델이 데이터에 과적합되어 일반화 성능이 떨어질 수 있습니다.
연관 규칙 학습의 개선 방법
- 알고리즘 최적화
- Apriori 알고리즘의 경우, 후보 항목 집합 생성을 최소화하여 효율성을 높일 수 있습니다.
- FP-Growth 알고리즘의 경우, FP-Tree 구조를 최적화하여 탐색 속도를 향상시킬 수 있습니다.
- 데이터 전처리
- 데이터 정규화, 중복 제거 등의 전처리 과정을 통해 데이터의 품질을 향상시킬 수 있습니다. 이는 더 의미 있는 규칙을 도출하는 데 도움이 됩니다.
- 평가 지표 다양화
- 신뢰도와 향상도 외에도 흥미도(Interestingness), 신뢰도 제곱(Confidence Squared) 등의 다양한 평가 지표를 사용하여 규칙의 유의미성을 평가할 수 있습니다. 이를 통해 더 정확하고 유의미한 규칙을 도출할 수 있습니다.
'📈 Data Engineering > 📇 Machine Learning' 카테고리의 다른 글
| [ML] Recommender System (추천시스템) (0) | 2024.08.26 |
|---|---|
| [ML] Emsemble Methods (앙상블 기법) (0) | 2024.08.23 |
| [ML] t-SNE (t-Distributed Stochastic Neighbor Embedding) (0) | 2024.08.20 |
| [ML] Isomap (아이소맵) (0) | 2024.08.20 |
| [ML] Principal Component Analysis (PCA - 주성분 분석) (0) | 2024.08.18 |