본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다. (https://fastcampus.info/4oKQD6b)
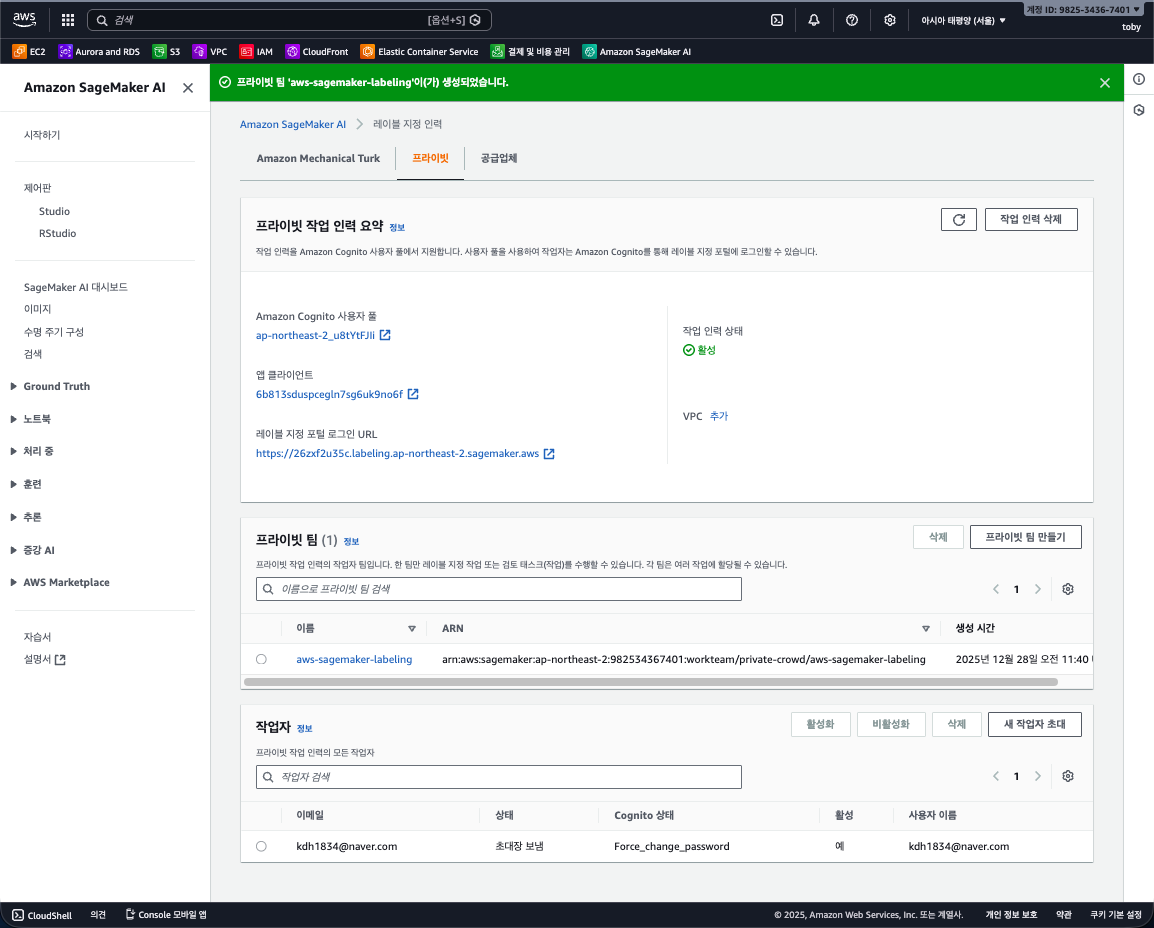
오늘은 MLOps 구축을 위해 주로 사용되는 플랫폼들 중에서 AWS에서 직접 제공하는 완전 관리형 서비스, Fully Managed 서비스인 Amazon SageMaker를 활용하기 위해 첫 단계인 데이터를 준비하고 정제하는 과정을 통해 과정을 효율화 하는 내용에서 데이터를 저장하고, 라벨링 작업을 할당하는 내용까지 실습해 보았습니다.
일단, 먼저 고품질의 학습 데이터가 없으면 아무리 좋은 모델이여도 의미가 없습니다. 데이터를 수집, 정제, 그리고 정확한 라벨링 작업이 선행이 되어야 하고, 이건 매우 중요하다고 생각했습니다. 그러면서 SageMaker에 대한 도메인, 기초 환경 설정을 해보고 대규모 데이터셋에 대한 라벨링 작업을 효율적으로 할 수 있는 SageMaker Ground Truth에 대해서 한번 알아 보았습니다.
또한 Workforce 관리에 대해서 한번 보았는데, 이건 라벨링 작업을 수행할 인력을 Amazon Mechanical Tunk(불특정 다수 팀), Private (사내 팀), Vendor(전문 업체)들 중 하나를 선택하여 할당할수 있다는 점을 알았습니다. 그리고 초기에는 데이터셋을 사람이 직접 라벨링하지만, 어느정도의 일정 데이터가 쌓이면 모델이 알아서 학습하여, 쉬운 데이터는 자동으로 라벨링 하고, 어려운 데이터만 사람에게 직접 라벨링을 할 수 있게 하는 Active Learning 기법을 지원한다고 배웠습니다.
이렇게 활용해보면서 직접적으로 일일이 데이터를 구축하는 것이 아닌, SageMaker의 내부 기능을 활용하여 데이터 라벨링 작업의 효율화, 지정한 팀 인원에게 작업을 할당해서 관리하는 솔류션도 매우 효율적이라고 느껴졌으며, 회사에서 대규모의 데이터셋 구축 작업을 할때 인원을 지정해서 라벨링, 작업의 효율화를 이끌어 낼 수 있는 좋은 솔루션이라고 생각했습니다.