확률적 경사 하강법(Stochastic Gradient Descent)은 점진적 학습 알고리즘 중 하나입니다.
그 전에 점진적 학습 알고리즘에 대하여 설명을 드리면, 이전에 훈련한 모델을 버리고 새로운 모델을 훈련하는 것이 아닌, 기존의 훈련한 모델은 그대로 두고, 새로운 데이터에 데한 훈련을 기존의 모델을 이용하여 학습 하는 알고리즘 입니다.
그래서 본론으로 돌아오면, 확률적 경사 하강법에서 확률적이란 말은 '무작위하게' 혹은 '랜덤하게' 의 기술적인 표현입니다.
그리고 경사는, 기울기를 의미합니다. 즉, 그러면 확률적 경사 하강법은 경사를 따라 내려가는 방법입니다.
경사하강법의 특징은 가장 가파른 경사를 따라 원하는 지점에 도달하는것을 목표로 삼고있습니다. 다만, 가파른 경사를 내려갈때에는 일반적으로 천천히 조금씩 내려와야합니다. 이러한 방식으로 경사 하강법 모델을 훈련합니다.
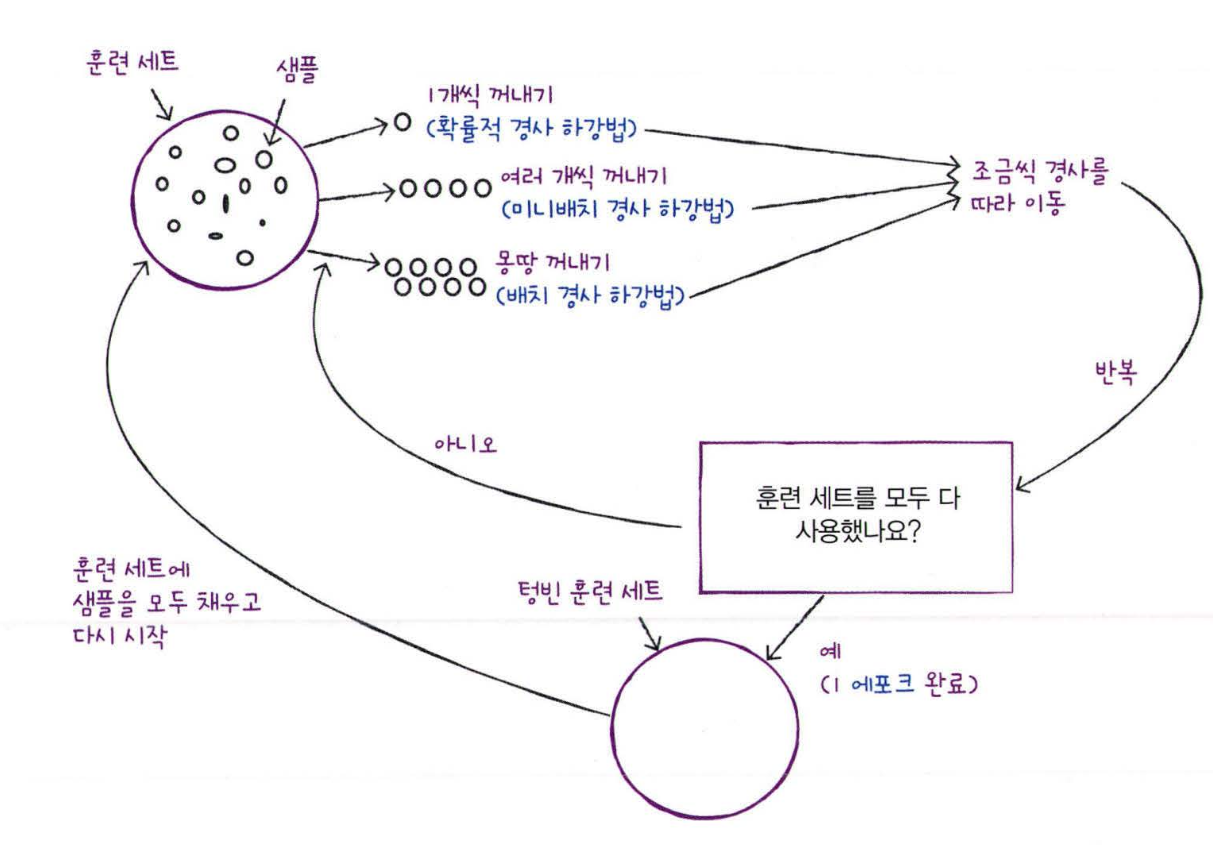
앞의 확률적 이라는 말은 경사 하강법으로 내려올때, 훈련 세트를 사용해서 모델을 훈련하기 때문에 경사하강법도 당연히 훈련세트를 이용해 가장 가파른 경사를 찾을것입니다. 그렇지만, 전체 샘플을 사용하지 않고 하나의 샘플을 훈련세트에서 랜덤하게 골라서 가장 가파른 길을 찾습니다.
즉, 간략히 하면 훈련세트에서 랜덤하게 하나의 샘플을 골라서 가파른 경사를 가진 길을 찾는 방법이 확률적 경사 하강법 입니다.
만약에 경사를 내려가면서 모든 샘플을 다 사용했으면 어떻게 할까요? 그러면 훈련세트에 모든 샘플을 다시 채워 넣습니다. 그리고 다시 랜덤하게 하나의 샘플을 선택해서 다시 경사를 내려갑니다.
여기 확률적 경사 하강법 에서 훈련세트를 모두 사용하는 과정을 에포크(Epoch)라고 부릅니다. 그리고 일반적으로 경사 하강법에서는 수십, 수백번 Epoch를 수행합니다.
그런데, 무작위로 샘플을 선택해서 산을 내려가면 무슨 문제가 생길수도 있습니다. 그래서 아주 조금씩 내려가야합니다.
근데, 우리가 걱정하는것보단 확률적 경사하강법은 잘 작동합니다. 그래도 걱정되면 무작위로 여러개의 샘플을 선택해서 경사를 내려가는 방법도 있습니다.
이렇게, 여러개의 샘플을 사용해 경사 하강법을 수행하는 방식을 미니배치 경사 하강법 (Mini-Batch Gradient descent) 이라고 합니다.
극단적으로, 한번 경사로를 이동하려고 전체 샘플을 사용하는 경우도 있습니다. 이 방식을 배치 경사 하강법 (Batch Gradient Descent)라고 합니다.
이 방법은 전체 데이터를 사용하기 때문에 가장 안정적인 방법이 될수도 있습니다. 다만 전체 데이터를 사용하면 컴퓨터의 자원을 많이 써먹기 때문에, 경우에 따라 데이터가 너무 많으면 한번에 전체 데이터를 불러 오지 못할수도 있습니다.
마지막으로 정리하면, 확률적 경사 하강법은 훈련 세트를 이용해서 산 아래에 있는 최적의 장소로 이동하는 알고리즘 입니다.
특히, 확률적 경사 하강법은 훈련 시킬 데이터가 모두 준비되어 있지 않습니다. 이유가 한번 경사를 내려갈때 전체 훈련 데이터를 사용하는 것이 아닌, 랜덤으로 하나의 훈련 샘플만이 사용되기 때문에, 매일매일 새로운 데이터로 업데이트가 되어도 학습을 계속 이어나갈 수 있습니다.
손실 함수 (Loss Function)
손실 함수(Loss Function)는 어떤문제에서 머신러닝 알고리즘 값이 얼마나 엉터리 인지 측정하는 기준입니다.
손실함수의 값이 클수록 안좋은거고, 작을수록 좋은겁니다. 근데, 어떠한 값이 최소값인지는 손실함수로 알 수 없습니다.
가능한 최대한 많이 찾아보고 괜찮으면, 어느정도 산을 다 내려왔다고 생각하는것이 맞을듯 합니다.
이 방법이면 확률적 경사 하강법이 적합할것 같습니다. 그러면 여기서 어떠한 손실 함수(Loss Function)을 사용해야 하는지 알아보겠습니다.
분류
분류에서 손실은 간단합니다. 정답을 못맞추는 것이죠. 예로 2진분류를 들어보겠습니다.
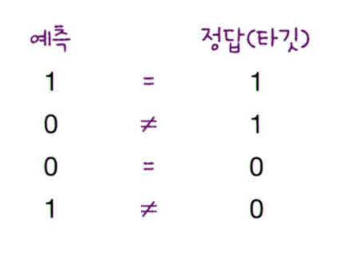
도미가 양성(1), 빙어가 음성(0)이라고 가정하고 아래 그림을 한번 보겠습니다.
정확도는 4개의 예측중 2개만 맞았으므로 2/4 = 0.5 입니다. 근데, 여기서 정확도를 손실 함수로 사용할 수 있을까요?
예를 들어서 정확도에 음수를 취하면 -1.0이 제일 낮고 0.0이 제일 높습니다. 사용할 수 있을까요?
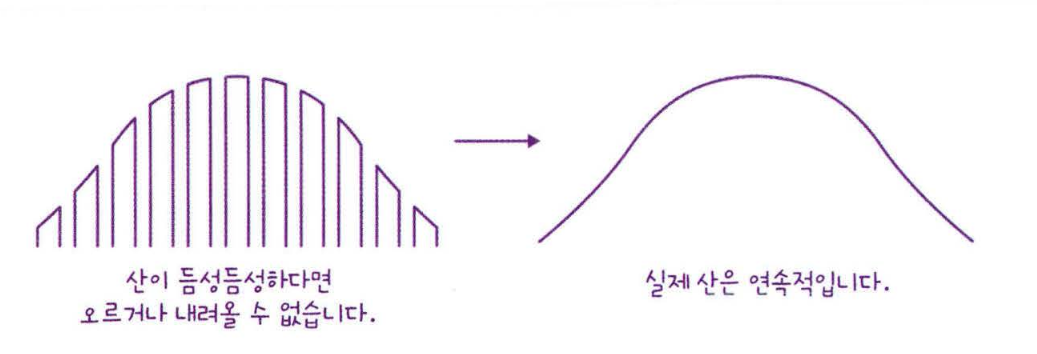
근데, 정확도에는 단점이 있습니다 앞의 그림처럼 4개의 샘플만 있다면 가능한 정확도는 0, 0.25, 0.5, 0.75, 1 다섯가지 뿐입니다.
그리고 정확도의 개수가 많이 없어서 중간이 듬성듬성하다면 경사하강법을 이용해서 조금씩 움직일 수 없습니다. 산의 경사면은 연속적이여야 하기 때문입니다.
그러면 어떻게 해야 연속적인 손실함수를 만들 수 있을까요? 혹시 'Logistic Regression(로지스틱 회귀)'에서 회귀 모델이 확률을 출력한 것을 기억하시나요?
예측하는 값은 0 또는 1이지만, 확률은 0~1 사이의 어떠한 값도 될수 있습니다. 즉, 연속적이죠. 한번 예시를 들어보겠습니다.
Logistic Loss Function (로지스틱 손실 함수)
샘플 4개의 확률을 각각 0.8, 0.7, 0.4, 0.2 라고 가정해보겠습니다. 이런 경우, 예측이 1에 가까울수록 좋은 모델입니다.
예측 값이 1에 가까울수록 예측과 타깃의 곱의 음수는 점점 작아집니다. 이 값을 손실 함수로도 사용할 수 있습니다.
0.8(예측) x 1 (정답/Target) = - 0.8 0.7(예측) x 1 (정답/Target) = - 0.7 1 - 0.4 -> 0.6(예측) x 0 -> 1 (정답/Target) = - 0.6 1 - 0.2 -> 0.8(예측) x 0 -> 1 (정답/Target) = - 0.8
첫,2번째 샘플들은 양성 클래스 임으로, 양성 클래스의 타깃인 1과 곱해서 음수로 봐꿀 수 있습니다.
3,4번째 샘플들은 음성 클래스 임으로, 음성 클래스의 타깃인 0과 곱하면? 무조건 0이 됨으로 결론을 내릴수는 없습니다.
그래서 방법은 타깃을 양성 클래스처럼 봐꿔서 1로 봐꿉니다. 예를 들어서 1 - 0.4 = 0.6으로 봐꿔서 사용합니다. 그리고 곱해서 음수로 봐꾸는것은 동일합니다.
그래서 예측 확률의 범위는 0~1 사이인데, 로그함수는 이 사이에서 음수가 됨으로 최종 손실값은 양수가 됩니다. 손실이 양수가 되면 더 이해하기 쉽습니다.
그리고 로그 함수는 0에 가까울수록 아주 큰 음수가 됨으로 손실을 크게 만들어서 모델에 영향을 미치는것도 가능합니다.
결론적으로. loss의 값이 0에 가까울수록 높은 손실, 1에 가까울수록 낮은 손실을 기록합니다.
정리하면 위의 그림과 같습니다. 양성 클래스(Target = 1)일때, 손실은 -log(예측 확률)로 계산합니다. 확률이 1에서 멀어질수록, 손실이 아주 큰 양수가 됩니다. 음수 클래스 (Target = 0)일때, 손실은 -log(1 - 예측 확률)로 계산합니다. 이 확률이 0에서 멀어질수록 손실은 아주 큰 양수가 됩니다.
이 손실함수를 Logistic loss function(로지스틱 손실 함수) or Binary cross-entropy loss function(이진 크로스엔트로피 손실 함수) 라고 부릅니다.
이진 분류에는 Logistic loss function(로지스틱 손실 함수)를 사용하고 다중분류를 할때에는 Binary cross-entropy loss function(이진 크로스엔트로피 손실 함수)를 사용합니다.
그러면 이번에 확률적 경사 하강법을 사용한 분류 모델을 한번 보겠습니다.
SGDClassifier
import pandas as pd
fish = pd.read_csv('https://bit.ly/fish_csv_data')
fish_input = fish[['Weight','Length','Diagonal','Height','Width']].to_numpy()
fish_target = fish['Species'].to_numpy()
여기서 Species열을 제외한 나머지 5개 데이터는 input data로 사용합니다. Species열은 Target data로 사용합니다.
이제 scikit-learn의 train_test_split() 함수를 사용해 이 데이터를 train & test set로 나눕니다.
그리고, 각 데이터 세트의 특성을 표준화 전러리를 합니다. 꼭, 훈련세트에서 한습한 통계 값으로 테스트 세트로 변환 해야 합니다.
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
이렇게 특성값의 Scale을 맞추고 2개의 Numpy의 배열을 준비하여, 확률적 경사 하강법을 제공하는 대표적인 분류법인 SGDClassifier 클래스를 사용하여 import 하겠습니다.
객체를 만들때 2개의 매개변수를 지정을 하는데, loss='log_loss'를 지정하여 로지스틱 손실 함수를 지정하고, max_iter는 수행할 epoch 횟수를 지정합니다. 여기선느 10으로 지정해서 전체 훈련세트를 10번 반복하겠습니다.
from sklearn.linear_model import SGDClassifier
# scikit-learn의 SGDClassifier는 확률적 경사하강법만 지원한다.
# ConvergenceWarning 발생시, max_iter의 값을 늘려주는것이 좋다.
sc = SGDClassifier(loss='log_loss', max_iter=10, random_state=42)
sc.fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target)) # 정확도
print(sc.score(test_scaled, test_target)) # 정확도
0.8151260504201681 0.8
이렇게 정확도가 낮으면 반복횟수를 높이면 됩니다.
여기서 확률적 경사 하강법은 점진적 학습이 가능합니다. SGDClassifier 객체를 다시 만들지 말고, 훈련한 모델 sc를 더 훈련시켜 보겠습니다. 모델을 계속 이어서 훈련 시키러면? partial_fit() Method를 사용합니다.
# scikit-learn 에서 epoch를 늘려가면, max_iter를 크게 하면 모델이 많이 훈련된 과대 적합으로 갈 수 있다.
sc.partial_fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))
partial_fit() Method는 일반 fit() Method와 사용법이 같지만 호출할때 마다, 1 epoch씩 이어서 훈련할 수 있습니다
Epoch와 과대/과소적합
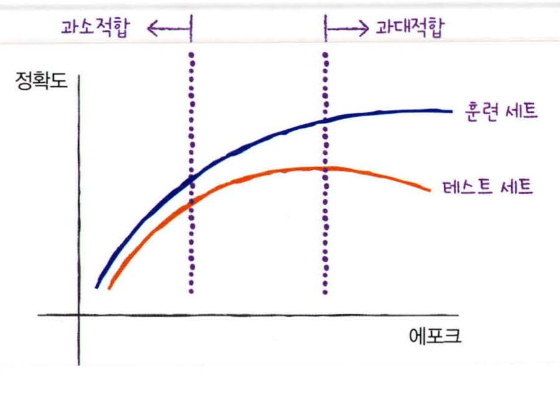
확률적 경사 하강법을 사용한 모델은 epoch의 횟수에 따라 과소or과대 적합이 될수 있습니다. 횟수가 적으면 훈련세트를 덜 학습하고, 많으면 완전히 학습해서 아주 잘 맞는 모델이 만들어 집니다. 다만 이러한 문제들은 모델이 과소/과대 적합이 될수 있습니다.
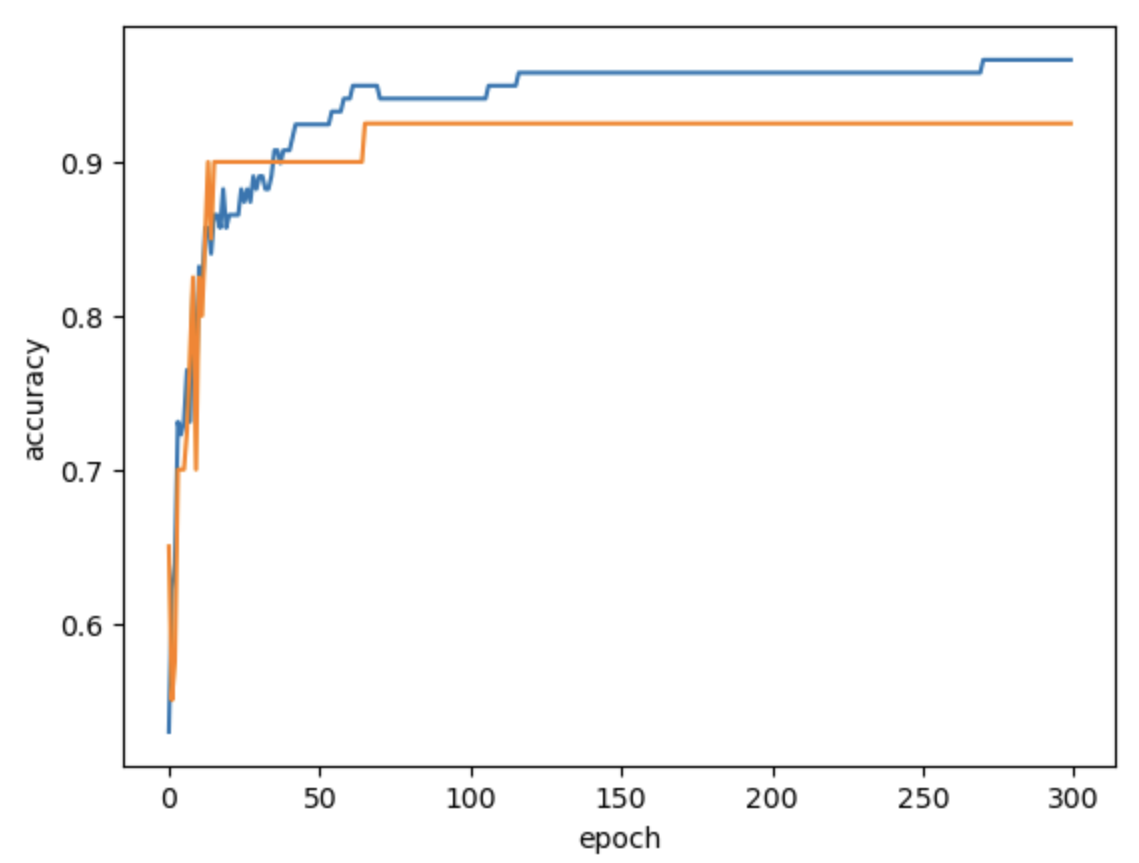
훈련세트 점수는 epoch가 진행될수록 꾸준히 증가하지만, 테스트 세트 점수는 어느지점부터 감소하기 시작합니다. 바로 이 지점이 모델이 과대적합 되기 시작하는 곳입니다.
이럴때, 과대적합이 되기전에 모델을 훈련을 종료 시키는데 이것을 조기종료(early stopping)이라고 합니다. 한번 그래프를 만들어서 보겠습니다.
여기서는 partial_fit() Method만 사용하겠습니다. 이 Method만 사용하려면, 훈련세트에 있는 전체 클래스의 label을 partial_fit() Method에 전달을 해주어야 합니다. 이를 위해서 np.unique() 함수로 train_target에 있는 7개의 생선 목록을 만듭니다. 그리고 각 epoch 마다 훈련, 테스트 세트에 대한 점수를 기록하기 위해서 2개의 list를 준비합니다.
SGDClassifier 클래스는 일정 epoch 동안 성능이 향상되지 않을시, 더 훈련하지 않고, 자동으로 멈춤니다. tol 매개 변수를 None으로 지정하면 자동으로 멈추지 않고, max_iter=100 만큼 무조건 반복하도록 합니다.
Hinge loss (흰지 손실)
이 글을 마무리 하기 전에, SGDClassifier의 loss 매개 변수를 잠시 설명을 드리겠습니다. loss 매개변수의 기본값은 'hinge'입니다. 흰지 손실 (Hinge loss)는 Support Vector Machine 이라고 불리는 머신러닝 알고리즘을 위한 손실 함수입니다.
자세히는 설명 드리지는 않겠습니다만, Support Vector Machine이 널리 사용하는 머신러닝 알고리즘중 하나라는 점
SGDClassifier가 여러 종류의 손실 함수를 loss 매개 변수에 지정하여 다양한 ML 알고리즘을 지원하는것만 알려드리겠습니다.
훈련 세트에서 샘플 하나씩 꺼내 손실 함수의 경사를 따라 최적의 모델을 찾는 알고리즘입니다. 샘플을 하나씩 사용하지 않고 여러 개를 사용하면 미니배치 경사 하강법 이 됩니다. 한 번에 전체 샘플을 시용하면 배치 경사 하강법이 됩니다.
손실 함수 (Loss Function)
확률적 경사 하강법이 최적화할 대상입니다. 대부분의 문제에 잘 맞는 손실 함수 가 이미 정의되어 있습니다. 이진 분류에는 로지스틱 회귀(또는 이진 크로스엔트로피) 손실 함수를 사용합니다. 디중 분류에는 크로스엔트로피 손실 함수를 사용합니다. 회귀 문제에는 평균 제곱 오차 손실 함수를 사용합니다.
에포크 (Epochs)
확률적 경사 하강법에서 전체 샘플을 모두 사용하는 한 번 반복을 의미합니다. 일반 적으로 경사 하강법 알고리즘은 수십에서 수백 번의 에포크를 반복합니다.
scikit-learn
SGDClassifier는 확률적 경사 하강법을 사용한 분류 모델을 만듭니다. loss 매개변수는 획률적 경사 하강법으로 최적화할 손실 함수를 지정합니다.
기본값은 서포트 벡터 머신을 위한 ‘hinge’ 손실 함수입니다. 로지스틱 회귀를 위해서는 ‘log’로 지정합니다.
penalty 매개변수에서 규제의 종류를 지정할 수 있습니다. 기본값은 L2 규제를 위한 ‘12’입니 다. L1 규제를 적용하려면 ‘11’로 지정합니다. 규제 강도는 alpha 매개변수에서 지정합니다. 기본값은 0.0001입니다.
max_iter 매개변수는 에포크 횟수를 지정합니다. 기본값은 1000입니다.
tol 매개변수는 반복을 멈출 조건입니다. n iter_no_change 매개변수에서 지정한 에포크 동 안 손실이 tol 만큼 줄어들지 않으면 알고리즘이 중단됩니다. tol 매개변수의 기본값은 0.001 이고 n_iter_no_change 매개변수의 기본값은 5입니다.
SGDRegressor
획률적 경사 하강법을 사용한 회귀 모델을 만듭니다. loss 매개변수에서 손실 함수를 지정합니다. 기본값은 제곱 오치를 나타내는 ‘squared_loss’ 입니다.
앞의 SGDClassifier에서 설명한 매개변수는 모두 SGDRegressor에서 동일하게 사용됩니다.