Instruction Set
특정 CPU가 구현하는 명령어 집합은 ISA(Instruction Set Architecture)라고 합니다.
- 그리고 하드웨어와 소프트웨어 사이의 인터페이스를 정의합니다.
- ISA는 다음을 포함합니다:
- 명령어 형식 (Instruction formats)
- 데이터 형식 (Data types)
- 레지스터 집합 (Register set)
- 메모리 주소 지정 방식 (Memory addressing modes)
- 입출력 방식 (Input/Output mechanisms)
- 기계의 언어 (Language of the Machine)
- 컴퓨터마다 다른 명령어 세트가 있습니다
- 하지만 여러 가지 측면에서 공통점이 있습니다
- 초기 컴퓨터에는 매우 간단한 명령어 세트가 있었습니다
- 단순화된 구현
- 명령어는 CPU가 실행하는 기본 연산자입니다. → 호환됨.
- 많은 현대 컴퓨터들도 간단한 명령어 세트를 가지고 있습니다. → instruction set 조합
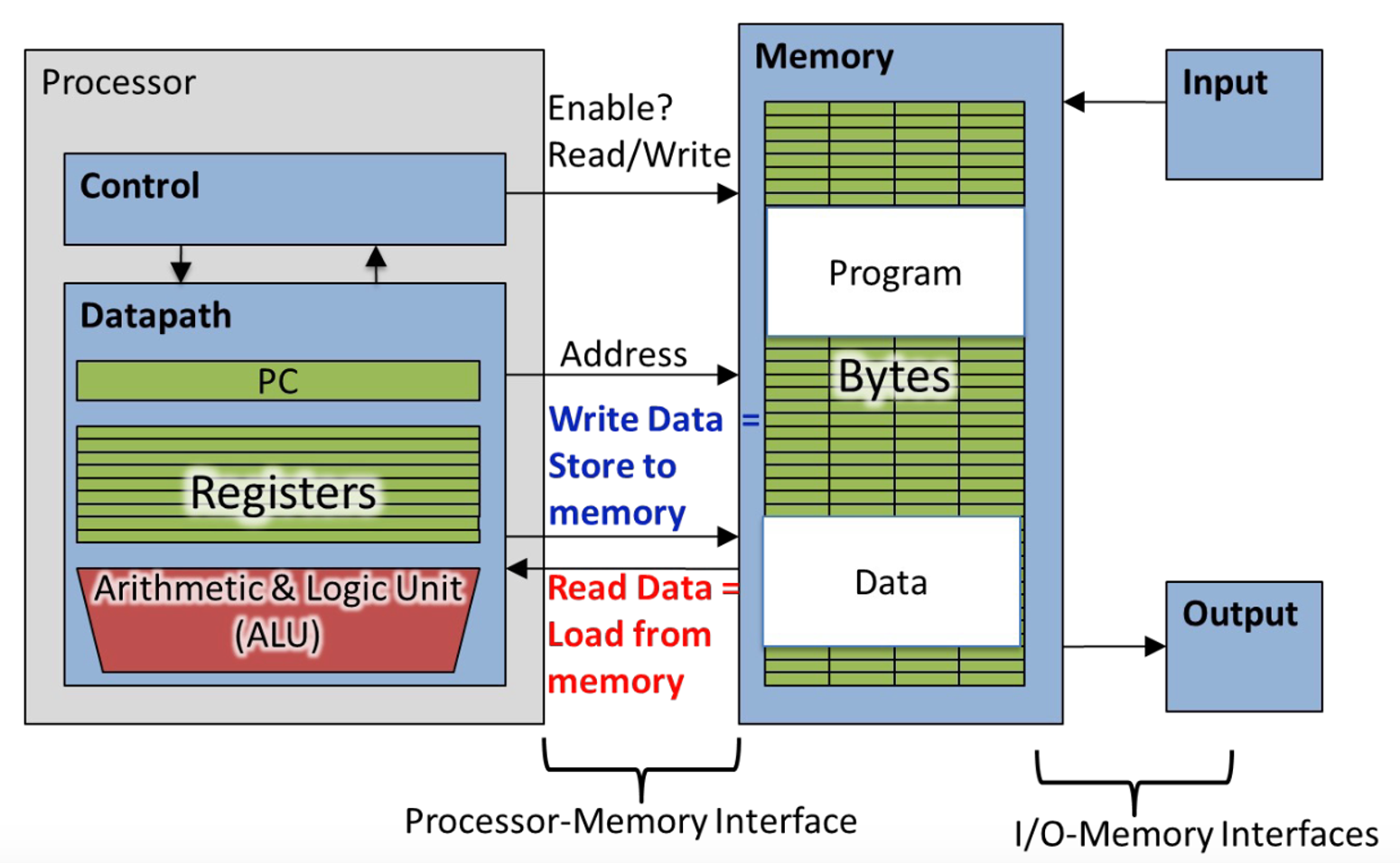
ISA 정의
ISA (Instruction Set Architecture는 데이터를 저장하기 위한 레지스터 및 메모리 모델 입니다.
- 데이터를 저장하기 위한 레지스터 및 메모리 모델
- ISA는 CPU가 사용할 수 있는 레지스터의 수와 종류, 크기를 정의합니다.
- 메모리 모델은 주소 지정 방식과 메모리 계층 구조를 포함합니다.
- 데이터 운영 및 제어 흐름
- 데이터 운영: 산술 연산, 논리 연산, 시프트 연산 등을 포함합니다.
- 제어 흐름: 조건 분기, 무조건 분기, 함수 호출 및 리턴을 포함합니다.
- 높은 수준의 프로그램을 효율적으로 번역하기 위한 충분한 Instruction
- ISA는 고급 프로그래밍 언어의 명령을 효율적으로 기계 코드로 변환할 수 있도록 충분한 명령어를 제공합니다.
- 이를 통해 컴파일러가 고성능 코드 생성이 가능하도록 합니다.
Instruction Set Format – 이진 표현
- 가변 길이 지침: 명령어의 길이가 다양하여 유연성이 높지만 디코딩 복잡도가 증가합니다.
- 고정 길이 지침: 명령어의 길이가 일정하여 디코딩이 단순하지만 유연성이 떨어질 수 있습니다.
CISC (Complex Instruction Set Computer) vs RISC (Reduced Instruction Set Computer)
- CISC: 복잡한 명령어를 적게 가지고 있어 프로그램 크기를 줄일 수 있지만, 개별 명령어의 실행이 더 복잡하고 느릴 수 있습니다.
- RISC: 간단한 명령어를 많이 가지고 있어 실행이 빠르고 효율적이지만, 프로그램 크기가 더 커질 수 있습니다.
지시 유형 예
- 데이터 처리
- 연산: ADD, SUB 등
- 논리: AND, OR, XOR 등
- 시프트: SHL, SHR 등
- 데이터 이동
- Register ↔ Register: MOV, XCHG 등
- Register ↔ Memory (또는 외부 장치): LOAD, STORE 등
- 제어 흐름
- 분기 또는 점프: JMP, JNZ 등
- 함수 호출 및 리턴: CALL, RET 등
- 시스템
- 시스템 명령어는 운영 체제와의 상호 작용을 위해 사용됩니다.
- 예: 인터럽트, 시스템 호출 등.
Instruction Set Architecture: CISC vs RISC
- 컴퓨터 아키텍처의 초기 단계에서
- 정교한 작업을 수행하기 위해 새로운 CPU에 점점 더 많은 지침이 추가됩니다.
- VAX 아키텍처에는 다항식을 곱하라는 명령이 있었습니다!
- CISC(Complex Instruction Set Computer) - 많은 지침(수백 개)
- 명령어를 실행하려면 여러 사이클이 필요합니다. 예: Intexl Pentium (x86)
- RISC(Reduced Instruction Set Computer) (1980년대) → ARM
- 명령어 세트를 작고 간단하게 유지하고,
- 빠른 하드웨어 구축(1 클럭 파이프라인 실행)이 용이합니다 → 규칙, 단순성
- 기본 프리미티브만 구현 & 아키텍처 로드/저장
- 소프트웨어가 더 간단한 작업을 구성하여 복잡한 작업을 수행하도록 합니다.
- Instruction Set을 정기적으로 유지합니다 - 명령어의 디코딩/스케줄링을 간소화합니다
- 예: ARM, MIPS, Spark, PowerPC, RISC-V
- 명령어 세트를 작고 간단하게 유지하고,
| CISC | RISC |
| 하드웨어 강조 | 소프트웨어에 대한 강조 |
| 다중 클럭 복잡한 명령어(Variable) 몇 가지 명령어 포함 | 단일 클럭, 축소된 명령어만 (고정) 많은 명령어 |
| 메모리-투-메모리: 명령어에 포함된 "LOAD" 및 "STORE” | 등록할 등록: "LOAD" 및 "STORE"는 독립적인 지침입니다 |
| 작은 코드 크기, 초당 높은 주기 느린 속도 | 큰 코드 크기 초당 낮은 주기 빠른 속도 |
| 복합구조 고출력 소비 | 간단한 구조 저전력 소비 |
RISC-V
RISC-V는 Reduced Instruction Set Computer (RISC) 원칙을 따르는 오픈 소스 명령어 세트 아키텍처(ISA)입니다.
- RISC-V는 기존의 상업용 ISA와 달리 누구나 사용할 수 있고 확장 가능하도록 설계되었습니다.
- UCBerkey에서 오픈 ISA로 개발 ( http://riscv.org )
- RISC-I(1981), RISC-II(1983), SOAR(1984), SPER(1989), RISC-V(2010)
- 오픈 소스: RISC-V는 누구나 자유롭게 사용할 수 있는 오픈 소스 ISA입니다. 이를 통해 연구, 교육 및 상업적 용도로 자유롭게 사용할 수 있습니다.
- 많은 업계의 후원자가 있습니다.
- 삼성, 구글, 퀄컴, NVDIA, IBM, 화웨이등..
- 합성 가능한 모듈식 설계
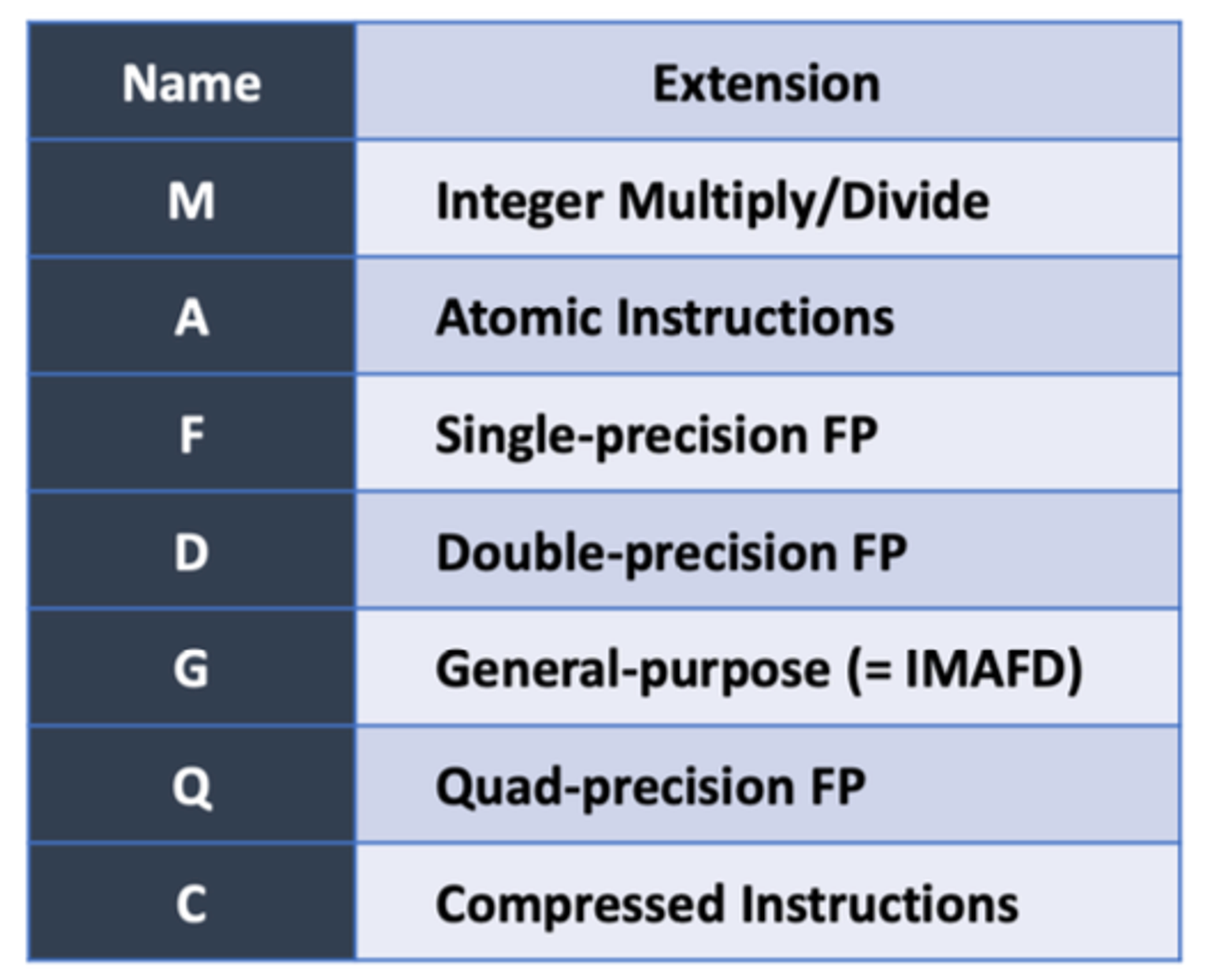
- 기본 세트: RV32I (32비트), RV64I (64비트), RV128I (128비트) 등 기본 명령어 세트가 있습니다.
- 확장 모듈: M(정수 곱셈/나눗셈), A(원자적 명령어), F(단정밀도 부동소수점), D(배정밀도 부동소수점) 등의 확장이 있습니다.
- 맞춤형 설계: 특정 응용 분야에 맞춘 맞춤형 프로세서 설계가 가능합니다.
Why Open ISA?
무료 사용 : 오픈 ISA는 라이선스 비용이 없기 때문에 누구나 자유롭게 사용할 수 있습니다. 이는 개발 비용을 크게 절감할 수 있습니다.
자유 시장 경쟁을 통한 더 큰 혁신
- 경쟁 촉진: 개방형 ISA는 다양한 기업과 개발자가 참여할 수 있게 함으로써 경쟁을 촉진하고 혁신을 가속화합니다.
- 폐쇄형 및 개방형 설계자들: 많은 핵심 설계자들이 개방형 ISA를 통해 개발에 참여함으로써 개발의 선순환 구조를 만듭니다.
공유 개방형 핵심 설계
- 비용 절감: 개방형 설계는 비용이 많이 드는 전용 설계를 대신하여 저렴하게 사용할 수 있습니다.
- 예: Arduino, Raspberry Pi와 같은 저가의 하드웨어 플랫폼이 이를 잘 보여줍니다.
- 시장 출시 시간 단축: 재사용 가능한 설계를 통해 제품의 시장 출시 시간을 단축할 수 있습니다.
- 오류 감소: 개방형 설계는 더 많은 개발자와 연구자가 참여하여 오류를 찾고 수정할 수 있어 오류 감소 효과가 있습니다.
- 투명성: 오픈 소스의 특성상 정부 기관이나 기타 기관이 비밀 트랩 도어를 추가하기가 어렵습니다.
더 많은 장치에 적합한 가격의 프로세서
- 저비용 프로세서: 오픈 ISA는 저비용의 프로세서 설계를 가능하게 하여 더 많은 장치에 적합합니다.
- 사물 인터넷(IoT) 확장 지원: 예를 들어, 1달러 이하의 비용이 드는 IoT 장치에도 활용할 수 있습니다.
소프트웨어 스택은 오래 지속됩니다
- 장기적 지원: 오픈 ISA 기반의 소프트웨어 스택은 커뮤니티와 개발자들의 지속적인 지원을 받아 오랜 기간 동안 유지되고 발전할 수 있습니다.
건축 연구 및 교육을 보다 실제적으로 구현
- 현실적 연구 및 교육: 오픈 ISA는 하드웨어 및 소프트웨어 스택을 완전히 개방하여 연구자와 학생들이 실제 환경에서 실험하고 학습할 수 있게 합니다.
- 완전한 접근: 연구자와 학생들이 하드웨어와 소프트웨어 스택의 모든 부분에 접근할 수 있어 더욱 깊이 있는 학습과 연구가 가능합니다.
RISC-V Base Architecture Components
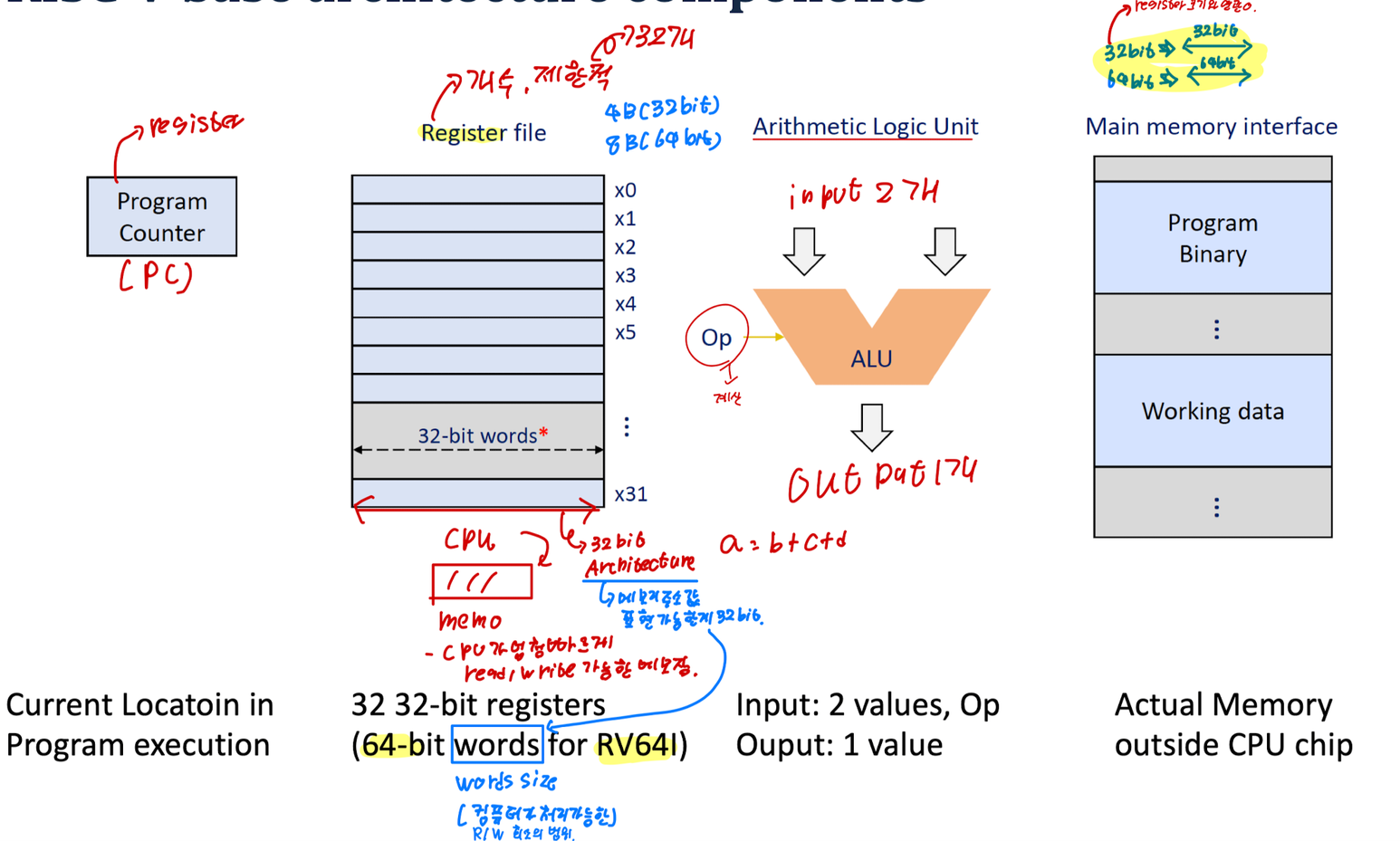
- Program Counter(Register): 프로그램 실행 중인 현위치를 의미합니다.
- Register File(개수가 제한적): 32비트 레지스터 32개(RV64I의 경우 64비트 워드)
- 메모리 주소값을 표현 가능한게 32bit 입니다.
- Words Size → 컴퓨터가 처리가능한 Read/Write 최소의 범위를 의미합니다.
- Arithmetic Logic Unit (산술 논리 단위): Input이 2개, Output이 1개
- Input: 2 Values, OP
- Output: 1 Value
- Main Memory Interface: CPU 칩 외부의 실제 메모리를 의미합니다.
Registers and ALU
레지스터 : Register File

- Register는 프로세서에 직접 내장된 일종의 메모리 입니다. → 프로세서 공정 때 Built-in 되어서 나옵니다.
- 데이터를 보관할 특수 위치의 수를 고정합니다.
- RISC-V 작업은 다음에 대해서만 수행할 수 있습니다
- 레지스터를 효율적으로 사용하려면 코드를 매우 신중하게 작성해야 합니다.
내 프로그램이 Read/Write 하는 데이터를 효과/효율적으로 Register에 올려서 관리?
- ALU : Armetric and Logic Unit -> 연산, 논리, 시프트 연산을 수행하기 위한 조합 회로 입니다.
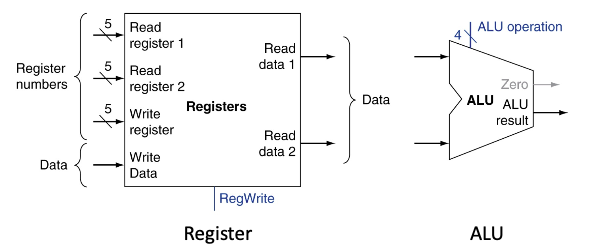
- ALU Operation의 진행 Flow. 즉, 진행 흐름은?
- Register number들을 Read Register에 전달 → Read data(우리가 번호를 전달해준 값)을 ALU에 Input으로 넣습니다.
- → ALU는 input 2개, Output은 1개. ALU Operation을 수행합니다. (4bit opcode: +, -, x, / )
- ALU result는 더한값을 output내어서 1개의 값을 출력. → 결과를 Register의 Write Data 부분에 넣습니다.
Register
레지스터는 적은 양의 데이터를 저장하도록 특별히 설계된 CPU 구성 요소입니다.
- 각 레지스터는 32비트(32비트 시스템의 경우) 또는 64비트(64비트 시스템의 경우)의 데이터를 저장합니다.
- Computer Instruction (컴퓨터 명령어)
- Storage Address (저장소 주소)
- 모든 종류의 데이터(비트 시퀀스) → 2진 데이터
- 이 데이터는 완전히 이진법입니다. 유형은 어셈블리 수준에 존재하지 않으므로 레지스터를 사용하여 어떤 것을 저장하는 경우 해당 레지스터와 해당 레지스터의 의도된 용도를 추적하는 것은 프로그래머의 책임입니다
- 프로그래머의 책임 → Register를 효율적으로 사용하는건 프로그래머의 몫입니다.
- 레지스터는 하드웨어 구성 요소이므로 CPU를 만들자마자 사용 가능한 레지스터 수를 변경할 수 없습니다.
Memory
대규모 1차원 배열로 보입니다.
아주 큰 배열 ROM (메모리 주소 공간) → Bytes 단위로 (1 byte)
- 메모리 주소가 바이트 입니다 → 4 byte씩 끊어서
- 각 주소는 8비트 바이트를 식별합니다
- RV32I에서 메모리 주소의 수는 32비트입니다 2^32 𝑏𝑦𝑡𝑒𝑠 → 4𝐺𝐵
- RV32I → Register 32bit (최대 값. 32bit → 2^32)
- 물리적으로 바이트는 메모리 액세스 성능을 위해 메모리 액세스 단위로 그룹화됩니다.
성능 → 1byte 단위로 읽고 쓰지 않음. 성능 저하 issue. Memory 읽고 쓰는건 전기적 신호로 읽고 씁ㄴ디ㅏ.
- 16비트 시스템의 경우 2B (32비트의 경우 4B)
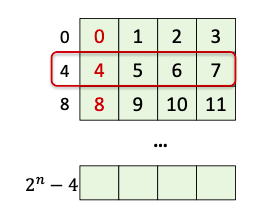
- In RV32I , Word is 4 bytes → Word 단위
- Words: 프로세서의 데이터 처리 장치 단위입니다.
- 또한 물리적으로 4B 그룹을 구성하는 것이 이상적입니다
- Words들은 기억 속에 정렬되어 있습니다 → 4byte 단위, 그리고 주소는 4의 배수여야 합니다.
Memory Alignment
물리적 메모리는 일반적으로 바이트 그룹에서 액세스됩니다.
- 메모리 액세스 유닛(32비트 시스템의 경우 4바이트 → Word 단위. 성능 issue)
- Aligned Access
- 액세스 주소가 메모리 액세스 장치로 제한됩니다
- Byte: A[31:0] → 제약 없음(다만, 성능 issue 때문에 잘 안씀. 사용은 가능)
- Half word (2B): A[31:1]0 → 2의 배수 (4 Byte / 2 → 2 Byte)
- Word (4B): A[31:2]00 → 4의 배수 (4의 배수 단위)

- 최신 시스템은 성능을 위해 정렬된 액세스를 의미합니다.
Endianness
Memory 주소 나열. 주소 어떻게 표현 및 접근?
- 메모리 또는 파일에 1B 데이터 이상의 순서(Byte Order) 저장
- Big-Endian: 고차 바이트 우선 → 인간 친화적 (네트워크 바이트 순서)
- Little-Endian: 하위 바이트 우선 → 기계 친화적 (x86, RISC-V)
Example) Value 0x1A2B2C4D
MSB(Big Endian) → 1A, 2B, 3C, 4D 순서
LSB(Little Endian) → 4D, 3C, 2B, 1A 순서
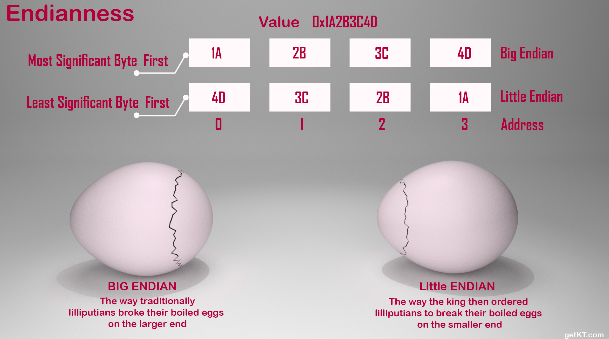
Big-Endian vs Little-Endian
메모리 주소 100에 4바이트 0xAABBCCD 저장을 저장한다고 예시를 들어보겠습니다.
- MSB(Big Endian): 0x부터 ~ DD
- LSB(Little Endian): DD부터 ~ 0x
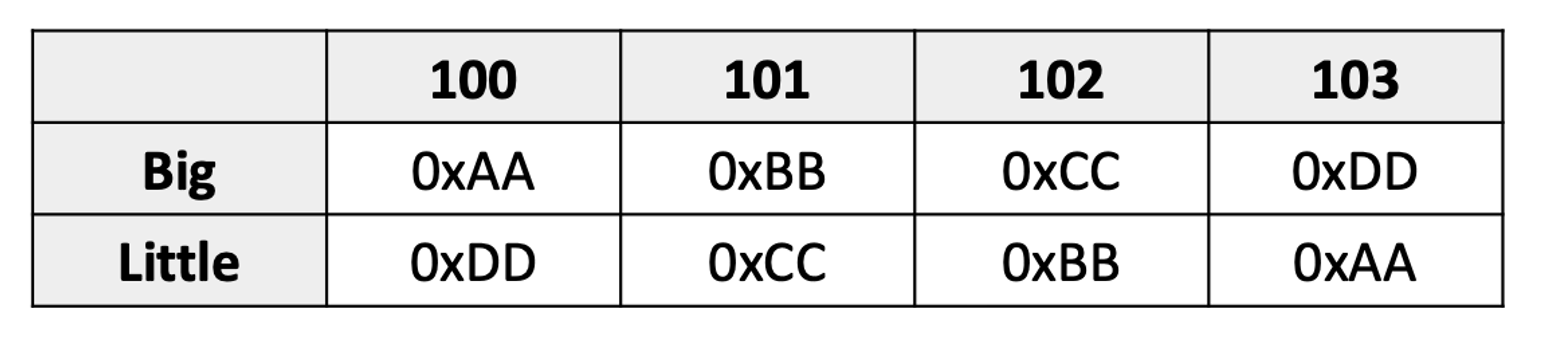

- MSB (Big-Endian): 고차 바이트 우선 → 인간 친화적 (네트워크 바이트 순서)
- LSB (Little-Endian): 하위 바이트 우선 → 기계 친화적 (x86, RISC-V)
엔디안
'⚙️ Computer Architecture' 카테고리의 다른 글
| [Computer Architecture] Operation (연산) (0) | 2024.07.15 |
|---|---|
| [Computer Architecture] RISC-V (0) | 2024.07.13 |
| [Computer_Architecture] Performance Part.2 (0) | 2024.06.24 |
| [Computer_Architecture] Performance Part.1 (0) | 2024.06.15 |
| [Computer Architecture] Processor, Computer System Organization (0) | 2024.04.18 |